
Actualización del modelo DeepSeek-V3 de perfil bajo, la capacidad de código salta a Claude-3.7

La competencia en el sector tecnológico es cada vez mayor. Recientemente, el equipo de la startup china de IA DeepSeek actualizó su modelo base V3 de forma discreta y sin publicidad a gran escala, y la nueva versión del DeepSeek-V3-0324 se ha puesto a disposición de los desarrolladores en la plataforma Hugging Face para su descarga y despliegue. A pesar del bajo perfil de esta actualización, las importantes mejoras del nuevo modelo en términos de capacidad de código han suscitado rápidamente un gran interés y acalorados debates en la comunidad técnica.
Hace unas horas, DeepSeek-AI ha abierto una versión actualizada de DeepSeekV3, la versión 0324, subida a HuggingFace el 24 de marzo de 2025 y de código abierto utilizando el protocolo del MIT.
La información de configuración del modelo muestra que DeepSeekV3-0324 sigue siendo un gran modelo MoE, que contiene 256 expertos en enrutamiento y 1 experto compartido para cada ficha Utiliza 8 expertos para la inferencia. DeepSeekV3-0324 alcanza una longitud máxima de contexto de 16.3840 (160.000) mediante RoPE. El tamaño del vocabulario del modelo es de 129280 e integra el mecanismo LoRA para permitir un ajuste fino ligero.
Ninguno de estos parámetros ha cambiado desde el lanzamiento de DeepSeekV3 el 26 de diciembre de 2024, lo que significa que esta actualización es muy probablemente el resultado de un entrenamiento continuo o post-entrenamiento del modelo original.
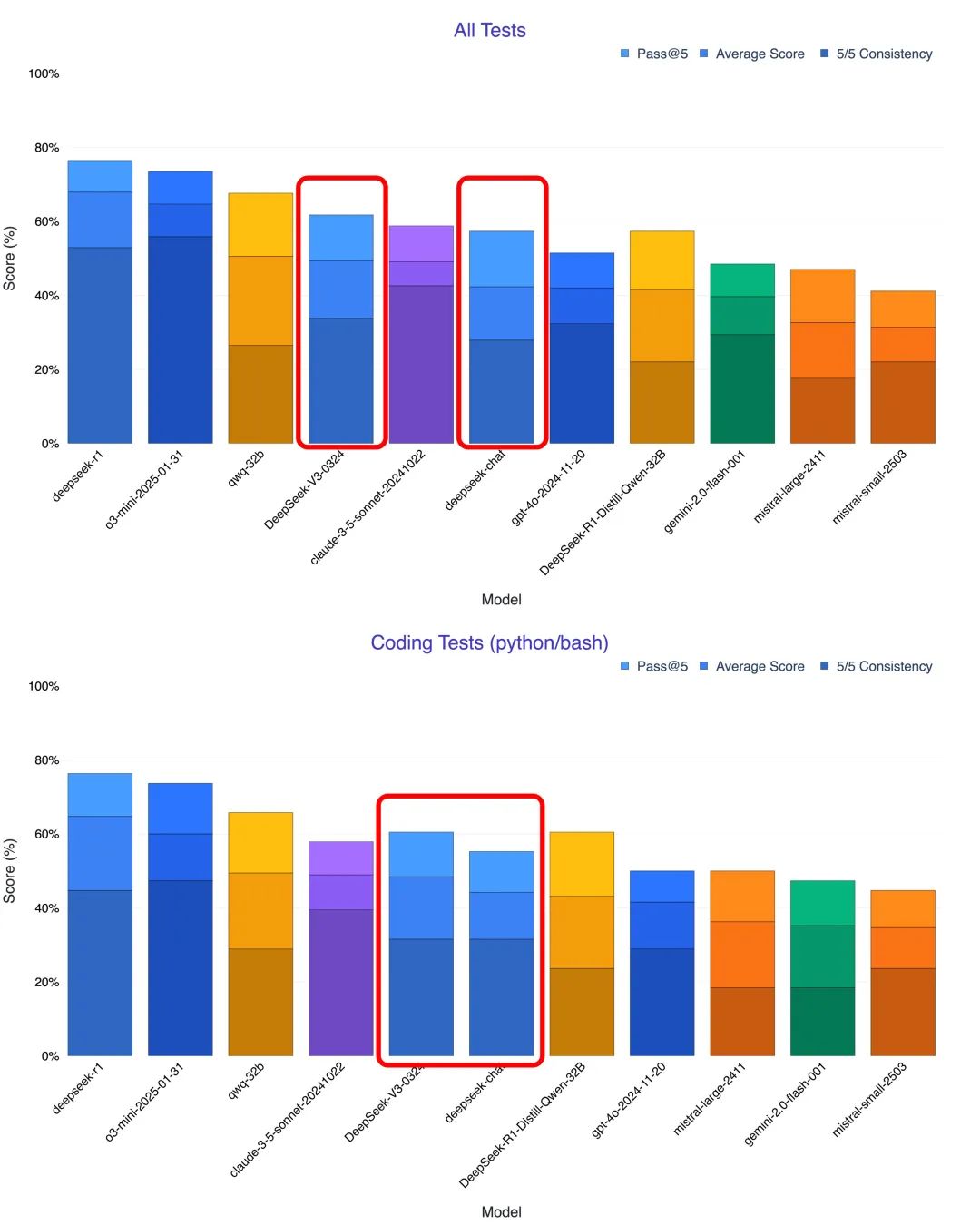
Las capacidades del código se disparan hasta alcanzar niveles de referencia cercanos
Las primeras impresiones de los usuarios y las múltiples pruebas realizadas indican que la mejora más notable de DeepSeek-V3-0324 es su capacidad de generación y comprensión de código. Muchos probadores señalaron que en áreas como el razonamiento matemático y el desarrollo front-end, la nueva versión supera incluso al Claude 3.5 y Claude 3.7 Sonnet. El blogger @KuittinenPetri en la plataforma de medios sociales X fue aún más franco cuando dijo que DeepSeek-V3-0324 hace que sea fácil y libre para crear hermoso HTML5, CSS y código front-end, que es grande para el Antrópico y OpenAI plantean nuevos retos.
Por ejemplo, con un simple comando, DeepSeek-V3-0324 fue capaz de generar una página de inicio responsiva de gran aspecto para una empresa de IA llamada NexusAI, integrando todos los elementos en un único archivo HTML5. El código resultante tenía 958 líneas y dio lugar a un sitio web interactivo y apto para dispositivos móviles que incluía incluso los recursos de imagen necesarios. Según @KuittinenPetri, DeepSeek-V3-0324 es DeepSeek El mejor modelo de no-inferencia disponible actualmente no sólo es genial en la escritura creativa, sino que ahora es incluso mejor en la generación de HTML5 + CSS + código front-end que R1. Otro usuario también consiguió que DeepSeek-V3-0324 creara un sitio web en el que el modelo generó más de 800 líneas de código de una sola vez y el diseño del sitio fue bastante acertado.
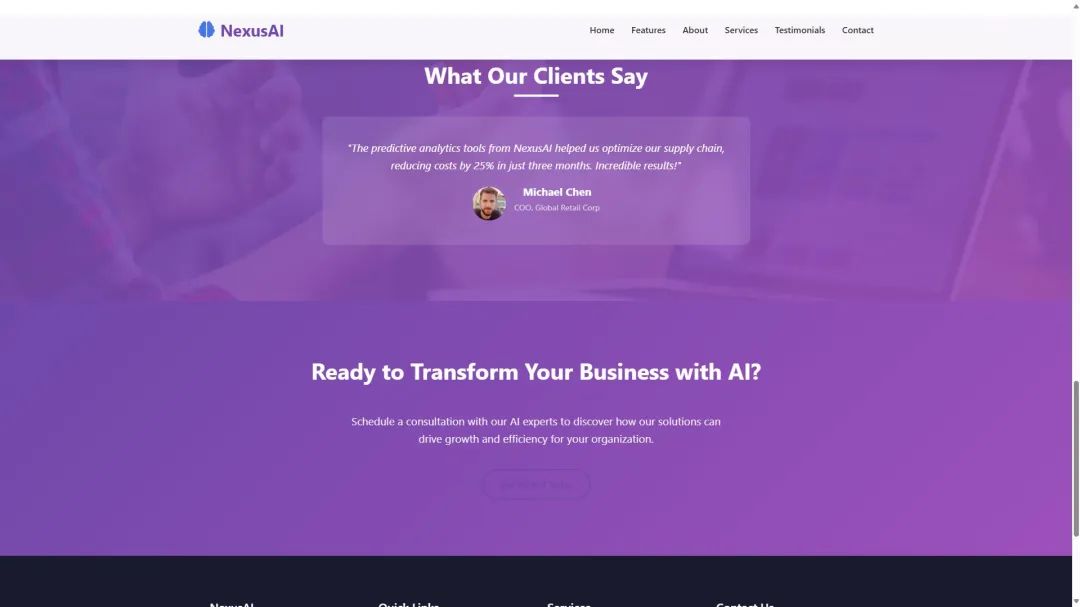
Pruebas en múltiples escenarios reales que demuestran un gran potencial de programación.
Para evaluar mejor las capacidades de programación de DeepSeek-V3-0324, muchos investigadores realizaron pruebas con diferentes escenarios y lo compararon con modelos como el antiguo V3, Claude 3.7 y o1 pro. Los resultados de las pruebas demostraron la notable mejora de la nueva versión de V3 en términos de programación.
- Páginas de texto a visualización: En la prueba de conversión de descripciones de texto en páginas web interactivas, DeepSeek-V3-0324 muestra un salto cualitativo respecto a la antigua versión V3. Las páginas web generadas por la nueva versión no sólo son más ricas en contenido, sino que también presentan un diseño y una disposición de la interfaz de usuario significativamente mejorados, que incluso superan la actualización de Claude 3.5 a 3.7. Cabe destacar que DeepSeek-V3-0324 es capaz de seguir instrucciones detalladas para convertir el contenido de un archivo PDF en una bella visualización en chino de una página web, lo que a menudo se considera un punto fuerte de Claude 3.7.
- Generar animación 3D: En las pruebas en las que se generaron presentaciones interactivas en 3D a partir de la base de código JS, la nueva V3 fue capaz de modelar cada paso del proceso de elaboración del chocolate y admitir interacciones con pestañas y barras laterales. Aunque todavía se puede mejorar respecto a Claude, supera con creces las capacidades de la antigua V3.
- Diseño de componentes de interfaz de usuario: En la prueba de diseño del componente de interfaz de usuario de previsión meteorológica, V3-0324 ha mejorado su rendimiento de animación y la precisión del etiquetado del texto meteorológico, lo que demuestra que es más capaz de generar interfaces de usuario prácticas.
- Simulación del mundo físico: En una prueba que simulaba una pelota rebotando dentro de un hexágono giratorio, DeepSeek-V3-0324 implementa con precisión el efecto de colisión de la pelota. Aunque sigue habiendo algunos fallos, el rendimiento general es mejor que el de la antigua V3 y comparable al de la o1 pro.
- Generación de juegos de IA: Lo más sorprendente es que DeepSeek-V3-0324 genera un juego jugable de serpientes de píxeles con efectos de sonido y modos asistidos por IA con sólo una frase de instrucciones. Aunque se quede corto en complejidad y perfección respecto al modo de pensamiento extendido de Claude 3.7, el hecho de que haya sido capaz de completar un juego totalmente funcional es una gran demostración de sus potentes capacidades de programación.
Características técnicas y ventajas económicas
DeepSeek-V3-0324 aún no ha publicado una ficha detallada del modelo, pero se sabe que tiene un tamaño de parámetros de 685.000 millones. Cabe señalar que DeepSeek V3 utiliza el modelo Modelización experta híbrida (ME) arquitectura con 671.000 millones de parámetros, de los cuales sólo 37.000 millones se activan por inferencia. (Nota del editor: El modelo MoE reduce significativamente el coste computacional y la latencia al descomponer grandes modelos en múltiples subredes "expertas", manteniendo al mismo tiempo el rendimiento del modelo). Para resolver el problema de la carga desequilibrada de expertos en el modelo tradicional de ME, DeepSeek propone de forma innovadora en la V3 que Estrategia de equilibrio de carga sin pérdidas auxiliares V3 también utiliza un "término de sesgo" para ajustar dinámicamente la carga experta con el fin de mejorar el rendimiento del modelo y la eficacia del entrenamiento. Además, V3 también adopta Mecanismos de encaminamiento limitados por nodos para reducir los costes de comunicación en la formación distribuida a gran escala.
Además de un gran rendimiento, DeepSeek-V3-0324 continúa con el relajado protocolo de código abierto del MIT. Y lo que es más importante, su API tiene un precio competitivo en comparación con la de OpenAI. o1-pro Al menos 50 veces más barato. Comparado con Claude 3.7, DeepSeek v3 cuesta aproximadamente una décima parte del precio de entrada, mientras que el precio de salida es aproximadamente una treceava parte del precio estándar, e incluso una veintisieteava parte del precio con descuento. Esta atractiva ventaja de precio, combinada con su naturaleza de código abierto, supondrá sin duda un fuerte incentivo para popularizar y desarrollar la programación de IA.
Características del modelo DeepSeek-V3-0324

DeepSeek-V3-0324 presenta mejoras significativas con respecto a su predecesor, DeepSeek-V3, en varias áreas clave.
- Se mejora la capacidad de razonamiento:
- MMLU-Pro: 75,9 → 81,2 (+5,3)
- GPQA: 59,1 → 68,4 (+9,3)
- AIME: 39,6 → 59,4 (+19,8)
- LiveCodeBench: 39,2 → 49,2 (+10,0)
- Capacidades mejoradas de desarrollo web front-end:
- Mejora de la ejecución de código
- Los frontales web y de juegos son más agradables estéticamente
- Perfeccionamiento de la escritura china:
- Mejora de la calidad del estilo y el contenido:
- Más cerca del estilo de escritura R1
- Mayor calidad de los escritos de longitud media
- mejora funcional
- Mejora de la capacidad de reescritura interactiva multirronda
- Optimización de la calidad de la traducción y la correspondencia
- Mejora de la calidad del estilo y el contenido:
- Mejora de la capacidad de búsqueda en China:
- Resultados más detallados de las solicitudes de análisis de informes
- Función Función de llamada mejorada:
- Llamada a función Mejora de la precisión y corrección de problemas heredados de la versión V3
Recomendaciones de uso
Indicación del sistema
Las mismas alertas del sistema con fechas específicas se utilizan en la web/app oficial de DeepSeek.
该助手为DeepSeek Chat,由深度求索公司创造。
今天是{current date}。
Por ejemplo:
该助手为DeepSeek Chat,由深度求索公司创造。
今天是3月24日,星期一。
Ajuste de los parámetros de temperatura
En los entornos web y de aplicación de DeepSeek, el parámetro de temperatura (Tmodelo) se establece en 0,3. Teniendo en cuenta que muchos usuarios utilizan la temperatura predeterminada de 1,0 en las llamadas a la API, DeepSeek implementó la temperatura de la API (Tapi) que ajusta el valor de temperatura de entrada API de 1,0 al ajuste de temperatura del modelo más apropiado de 0,3.
Tmodelo = Tapi × 0.3 (0 ≤ Tapi ≤ 1)
Tmodelo = Tapi - 0.7 (1 < Tapi ≤ 2)
Por lo tanto, si llama a V3 a través de la API, la temperatura 1,0 corresponde a la temperatura del modelo 0,3.
Avisos de carga de archivos y búsquedas en Internet
Para cargar archivos, cree avisos siguiendo la plantilla siguiente, donde {file_name}y{file_content} responder cantando {question} como parámetro.
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
Para búsquedas en Internet.{search_results}y{cur_date} responder cantando {question} como parámetro.
Consulta china Prompt:
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
Consulta en inglés Prompt:
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
Métodos de funcionamiento local
La estructura del modelo de DeepSeek-V3-0324 es idéntica a la de DeepSeek-V3. Para obtener más información sobre la ejecución local de este modelo, visite la página DeepSeek-V3 Repositorio de código.
El modelo admite funciones como la llamada a funciones, la salida JSON y la finalización FIM. Para obtener instrucciones sobre cómo crear avisos para utilizar estas funciones, consulte la sección DeepSeek-V2.5 Repositorio de código.
DeepSeek-V3-0324 es una actualización discreta que ha llamado mucho la atención en el mundo de la tecnología. Ha dado pasos impresionantes en sus capacidades de codificación, no sólo mostrando su fortaleza en una serie de tareas de programación, sino rivalizando en algunos aspectos con modelos superiores como Claude 3.5/3.7 Sonnet. Su naturaleza de código abierto, eficiente y rentable, le augura un futuro prometedor. La era de la universalidad de la programación de IA puede estar acelerándose DeepSeek. A medida que más plataformas de terceros se conecten a la nueva versión V3 de DeepSeek, tanto desarrolladores como usuarios podrán experimentar capacidades avanzadas de programación de IA a un coste menor. Sin duda, esto inyectará nueva vitalidad a todo el ecosistema de la IA e impulsará la aparición de aplicaciones más innovadoras. Con la potente capacidad de código V3 y la capacidad de razonamiento superior R1, merece la pena esperar al futuro modelo R2 de DeepSeek.
Esta actualización de DeepSeekV3 demuestra una vez más que la tecnología de IA de China se está desarrollando y poniendo al día rápidamente. La estrategia de código abierto y licencia comercial gratuita de DeepSeek-V3-0324 sin duda atraerá a más desarrolladores y empresas a unirse a las filas del desarrollo de aplicaciones de IA, y promoverá conjuntamente el progreso y la popularidad de la tecnología de IA.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...