Ali Bailian proporciona la API QwQ-32B de forma gratuita, ¡y 1 millón de tokens son libres de usarla cada día!

Recientemente se anunció la plataforma de refinamiento AliCloud Hundred para QwQ-32B El Big Language Model abre interfaces API y proporcionaAcceso gratuito a 1 millón de fichas al díaEl modelo QwQ-32B es una tecnología nueva y emocionante que reduce significativamente las barreras para que los usuarios experimenten la tecnología de IA de vanguardia. Para los usuarios que desean experimentar el potente rendimiento del modelo QwQ-32B pero están limitados por la potencia de cálculo del hardware local, llamar al modelo en la nube a través de la interfaz API es sin duda una opción más atractiva.
Lectura recomendada para quienes no conozcan el QwQ-32B:Modelo pequeño, gran potencia: QwQ-32B con parámetros 1/20 para luchar contra DeepSeek-R1 de pura cepa
Ventajas de la interfaz API: superación de las limitaciones del hardware, potente potencia de cálculo al alcance de la mano
Anteriormente publicamos Despliegue Local de Modelos Grandes QwQ-32B: Una Guía Fácil para PCs Además, los usuarios que desean experimentar modelos lingüísticos a gran escala como QwQ-32B a menudo necesitan desplegar localmente equipos informáticos de alto rendimiento. El requisito de hardware de 24 GB o incluso más de memoria de vídeo a menudo bloquea a muchos usuarios a las puertas de la experiencia de la IA. La interfaz API proporcionada por la plataforma Hundred Refine de AliCloud resuelve inteligentemente este punto problemático.
Al llamar a los modelos QwQ a través de la interfaz API, los usuarios pueden obtener varias ventajas:
- No hay umbral para la configuración del hardware. No es necesario desplegar localmente hardware de alto rendimiento, lo que reduce el umbral de uso. Incluso los portátiles ligeros y finos y los smartphones pueden recurrir sin problemas a la potente potencia de modelado de la nube. Se recomienda a los usuarios que utilicen una tarjeta gráfica con una memoria de vídeo de 24 G o superior para disfrutar de una experiencia de ejecución local de modelos más fluida.
- Compatibilidad con el sistema. La interfaz API es independiente del sistema operativo y multiplataforma. No importa si usas Windows, macOS o Linux, puedes acceder a ella fácilmente.
- La versión Plus, más potente. Los usuarios pueden experimentar la versión mejorada de QwQ Plus, que supera a la versión completa de QwQ-32B implantada localmente. La versión Plus, es decir, la versión mejorada del modelo de inferencia QwQ para Tongyi Qianqi, se basa en el modelo Qwen2.5 y se entrena mediante aprendizaje por refuerzo. En comparación con la versión básica, la versión Plus consigue una mejora significativa en la capacidad de inferencia del modelo, y alcanza el mayor rendimiento en las métricas principales (por ejemplo, AIME 24/25, livecodebench) y algunas métricas generales (por ejemplo, IFEval, LiveBench, etc.) en la evaluación. DeepSeek-R1 Versión completa del nivel del modelo.
- Respuesta de alta velocidad. La interfaz API permite tiempos de respuesta rápidos de 40-50 tokens/segundo. Esto significa que los usuarios pueden tener una experiencia interactiva casi en tiempo real, lo que mejora drásticamente la eficiencia.
Cabe mencionar que, además de AliCloud Hundred Refine, la plataforma de movilidad in silico también proporciona una interfaz API para el modelo QwQ-32B. Si los usuarios están interesados en la plataforma de flujo in silico, pueden consultar el artículo anterior. En este artículo, presentaremos principalmente cómo utilizar la interfaz API proporcionada por la plataforma Aliyun Hundred Refine.
Guía de acceso a la API de Aliyun Hundred Refined: ¡Tres sencillos pasos para empezar!
La plataforma Hundred Refinement de AliCloud ofrece a los usuarios de la API de modelos de la serie QwQ 1 millón de diarios fichas El crédito gratuito. Para la mayoría de los usuarios, esta cantidad es suficiente para la experiencia diaria y las pruebas. Los usuarios sólo tienen que completar un simple registro y configuración para empezar.
A continuación se describen brevemente los pasos para configurar Aliyun Bai Lian QwQ Plus API en el lado del cliente:
1. Obtener la clave API y el nombre del modelo
En primer lugar, visite la página Plataforma de refinamiento AliCloud Hundred y complete el registro o el inicio de sesión.
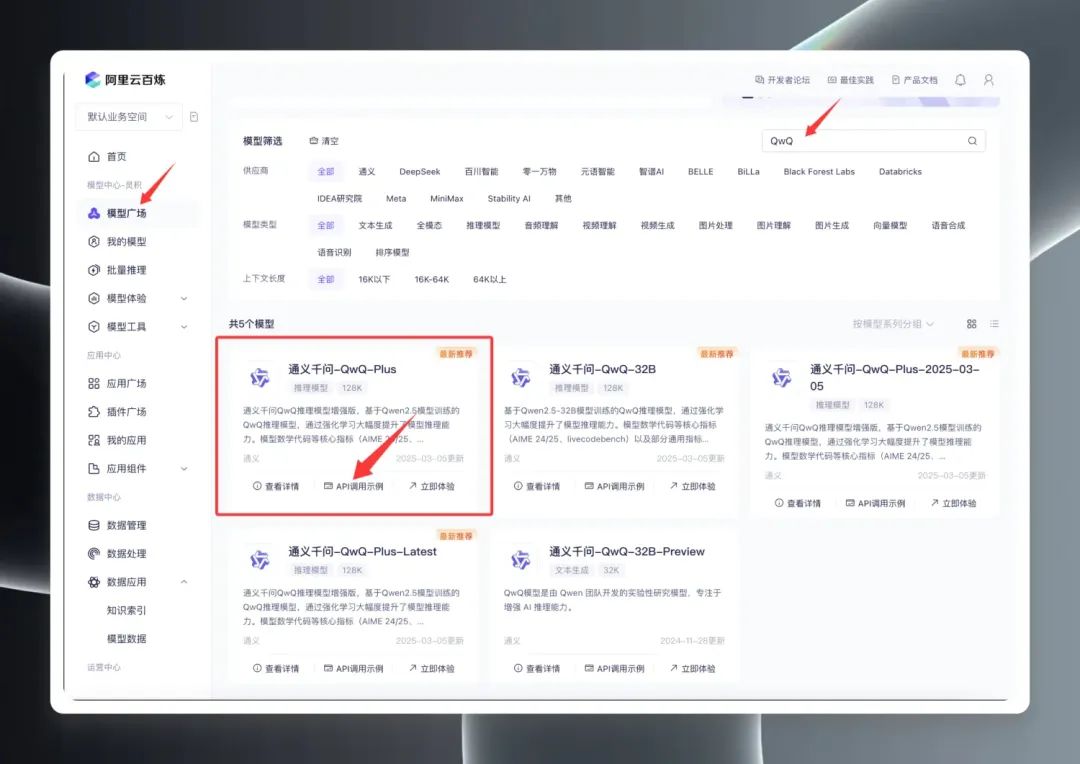
Una vez iniciada la sesión, busca "QwQ" en el Model Square para ver la gama de modelos QwQ. De hecho, el Model Square muestra tres versiones principales: QwQ32B (versión oficial), QwQ32B-Preview (versión preliminar) y QwQ Plus (versión mejorada, también conocida como versión comercial).
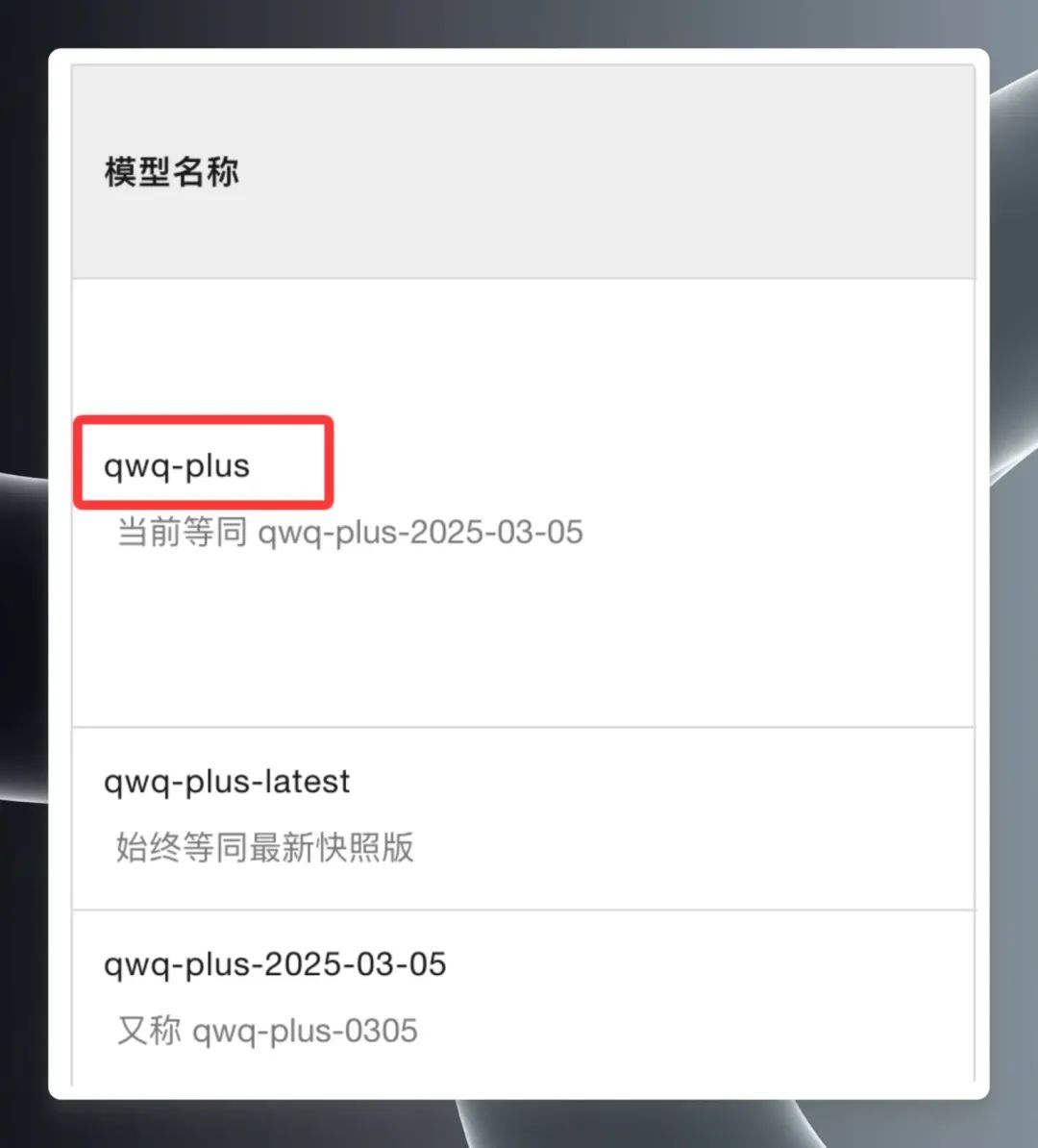
Seleccione "QwQ Plus (Enhanced)", haga clic en "API Call Examples" y, en la nueva página, busque el archivo Nombre del modelo qwq-plus.
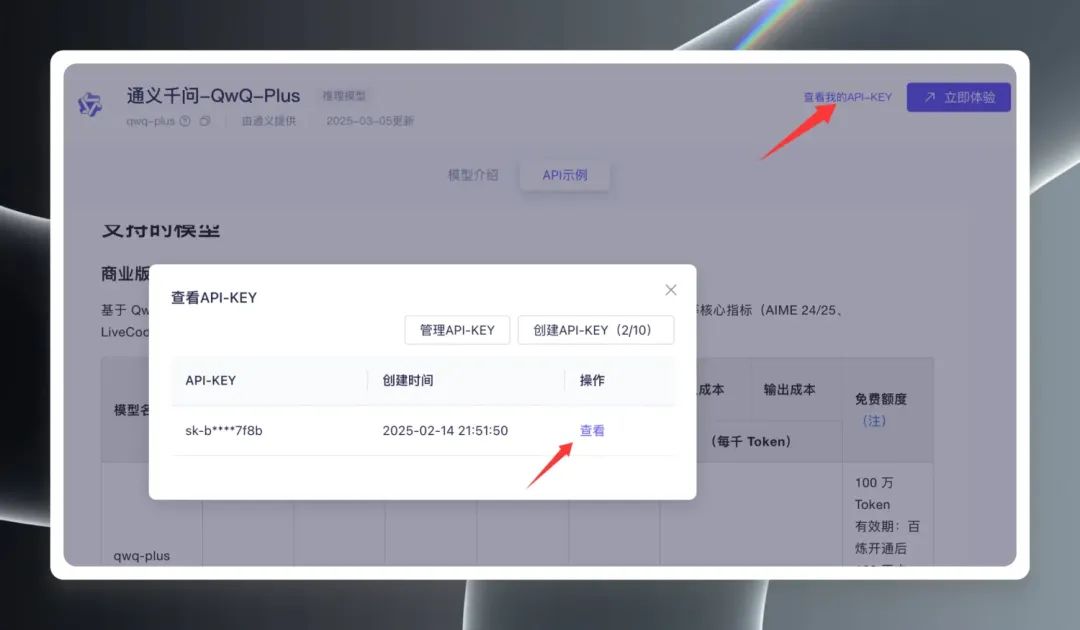
A continuación, haga clic en "Ver mi clave de API" en la esquina superior derecha de la página, tiene que crear una clave de API por primera vez, si ya ha creado una, puede verla directamente y copiarla. Clave API.
2. Configuración del cliente
este documento se basa en Chatwise El cliente se utiliza como ejemplo para fines de demostración. Abra el software Chatwise, haga clic en el avatar del usuario y vaya a la pantalla "Configuración".
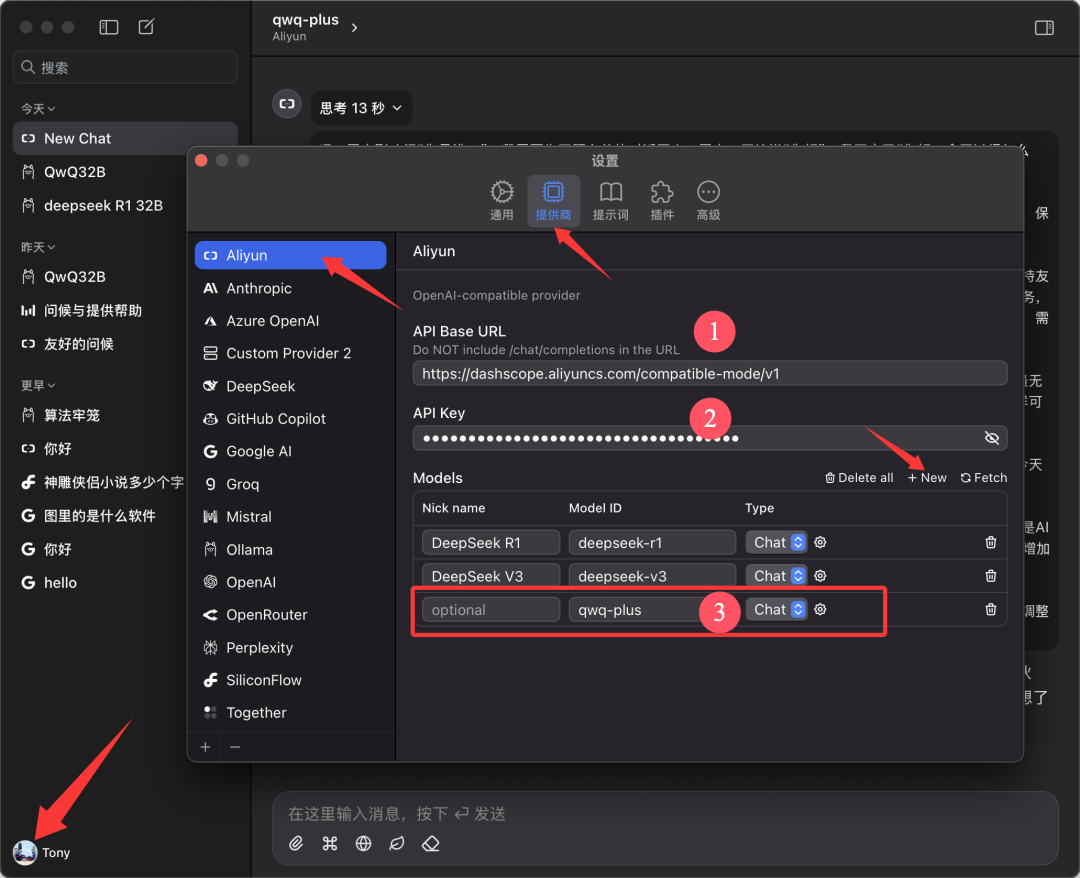
Busca "Aliyun" en la lista de proveedores, si no lo encuentras haz clic en "➕" en la parte inferior para añadirlo.
Configúrelo como se muestra en la figura siguiente:
- URL base de la API.
https://bailian.aliyuncs.com(General) - Clave API. Pegue la clave API que copió en el paso anterior
- Modelos. Añadir nombre de modelo
qwq-plus(debe ser el nombre)
3. Comenzar la experiencia
Vuelve a la pantalla principal de Chatwise y selecciona el modelo "qwq-plus" en el menú desplegable de selección de modelos para comenzar tu experiencia de diálogo.
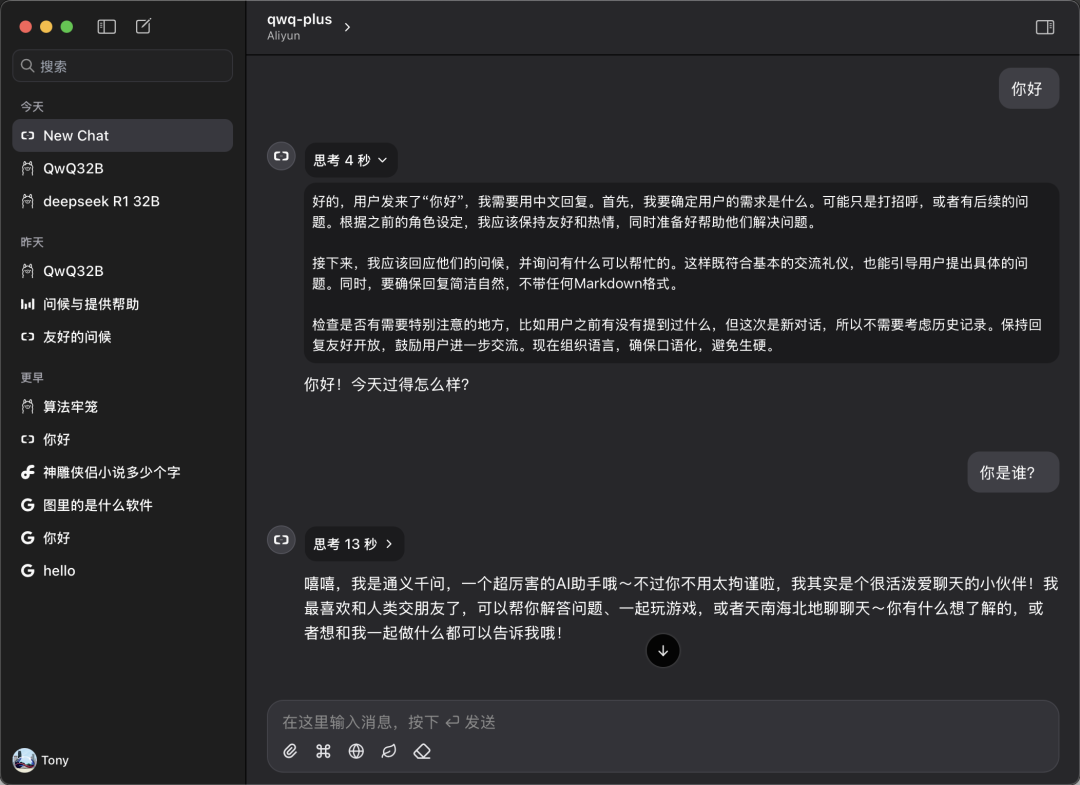
Rendimiento en el mundo real: comparable o superior al de las implantaciones locales.
Para comprobar el rendimiento real de la API QwQ Plus, realizamos una sencilla prueba comparativa.
Prueba de velocidad:
Las mediciones muestran que la velocidad de la interfaz API de QwQ Plus es excelente, con una tasa estable de 40-50 tokens/segundo. En comparación, la DeepSeek API del modelo R1, la tasa es significativamente más lenta, de más de 10 tokens/seg.
Pruebas de compatibilidad:
Los usuarios también pueden configurar y utilizar la API de QwQ Plus en un cliente como CherryStudio, pero durante las pruebas de CherryStudio se observó un problema potencial: cuando el modelo realiza razonamientos complejos durante un largo periodo de tiempo, CherryStudio puede consumir una gran cantidad de recursos del sistema y pueden producirse reinicios del software en algunos dispositivos configurados. Sin embargo, el uso del cliente Chatwise en el mismo entorno de hardware no наблюдаться problemas similares. Esto puede estar relacionado con las diferencias en los marcos de desarrollo de los distintos clientes.
Comparación de competencias:
Seguimos con las anteriores preguntas de razonamiento lógico con sombrero y comparamos el rendimiento del modelo nativo QwQ32 con la API QwQ Plus.
Descripción del problema:
Hay 5 personas en fila, cada una con un sombrero de color rojo o azul. Pueden ver los sombreros de las personas que tienen delante, pero no el suyo. El animador anuncia: "Hay al menos un sombrero rojo". Empezando por la última persona, cada una dice por turno "sí" o "no" (indicando si conoce o no el color de su sombrero). Si la 5ª persona dice "No" y la 4ª dice "Sí", halla la distribución de todos los colores de sombrero posibles.
Rendimiento del modelo local QwQ32:

El modelo local QwQ32 fue finalmente contestado con éxito tras dos intentos, el segundo de los cuales tardó 196 segundos.
Rendimiento de la API QwQ Plus:
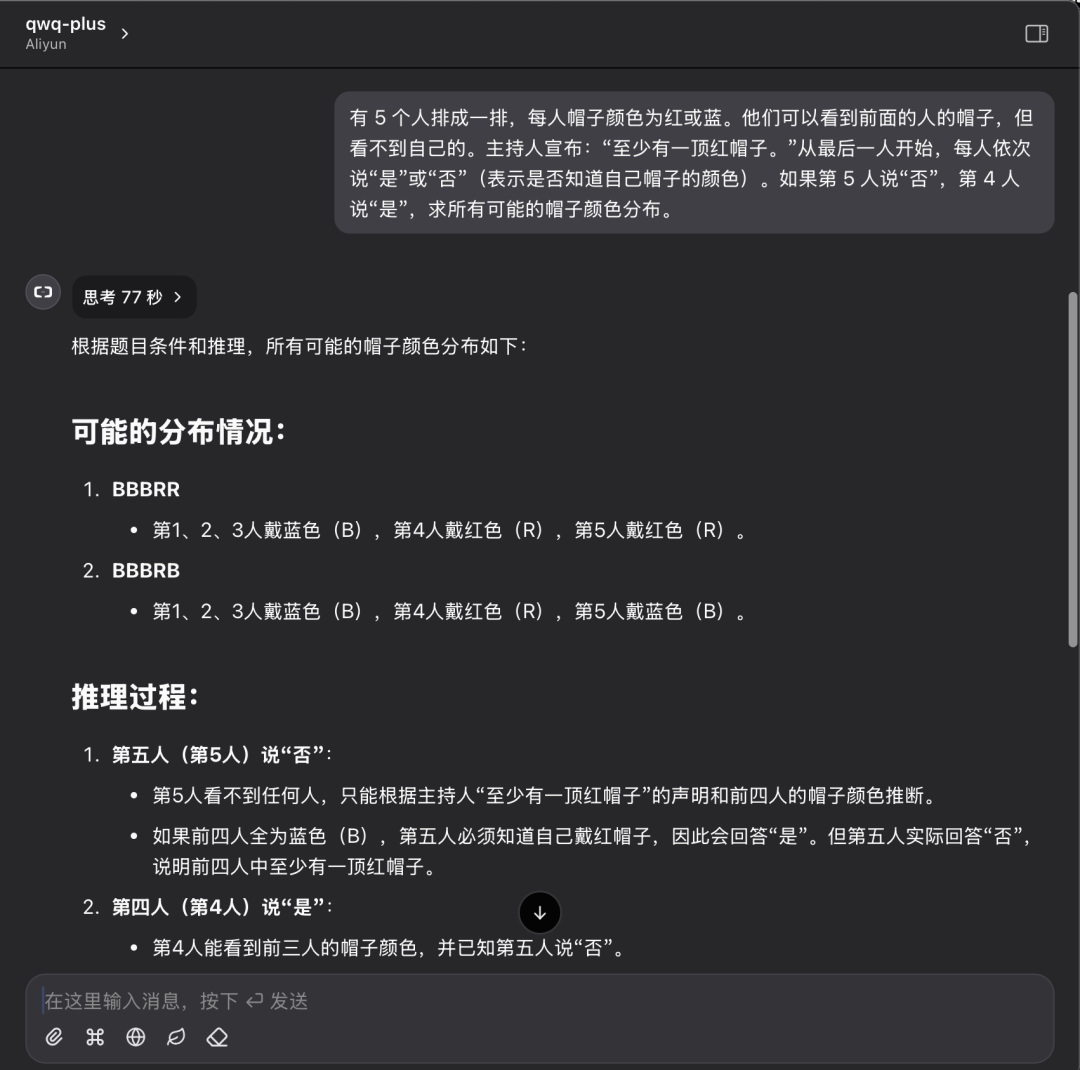
Rendimiento de la API QwQ Plus en la misma pregunta: una respuesta correcta en 77 segundos.
Análisis de los resultados de las pruebas:
Aunque un solo caso no basta para evaluar por completo la capacidad del modelo, los resultados de esta prueba pueden reflejar visualmente la diferencia entre el modelo implantado localmente y la solución de API en la nube. Al resolver problemas de razonamiento lógico, ambas soluciones pueden dar respuestas correctas, pero la API QwQ Plus es mejor en términos de eficiencia y claridad del proceso de razonamiento, con un tiempo de razonamiento más corto y un menor consumo de tokens.
Adoptar la IA en la nube para todos
La apertura gratuita de la interfaz API QwQ-32B en la plataforma AliCloud Hundred Refine y la provisión de generosos tokens gratuitos es, sin duda, un paso importante para promover la popularidad de la tecnología de modelado de grandes lenguajes. Con la interfaz API, los usuarios pueden experimentar fácilmente la potencia de los modelos de IA de alto rendimiento en la nube sin necesidad de invertir en costosos equipos informáticos. Tanto si eres desarrollador, investigador o entusiasta de la IA, ahora puedes aprovechar al máximo los recursos gratuitos proporcionados por Aliyun Hundred Refine para iniciar tu viaje de exploración de la IA.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...