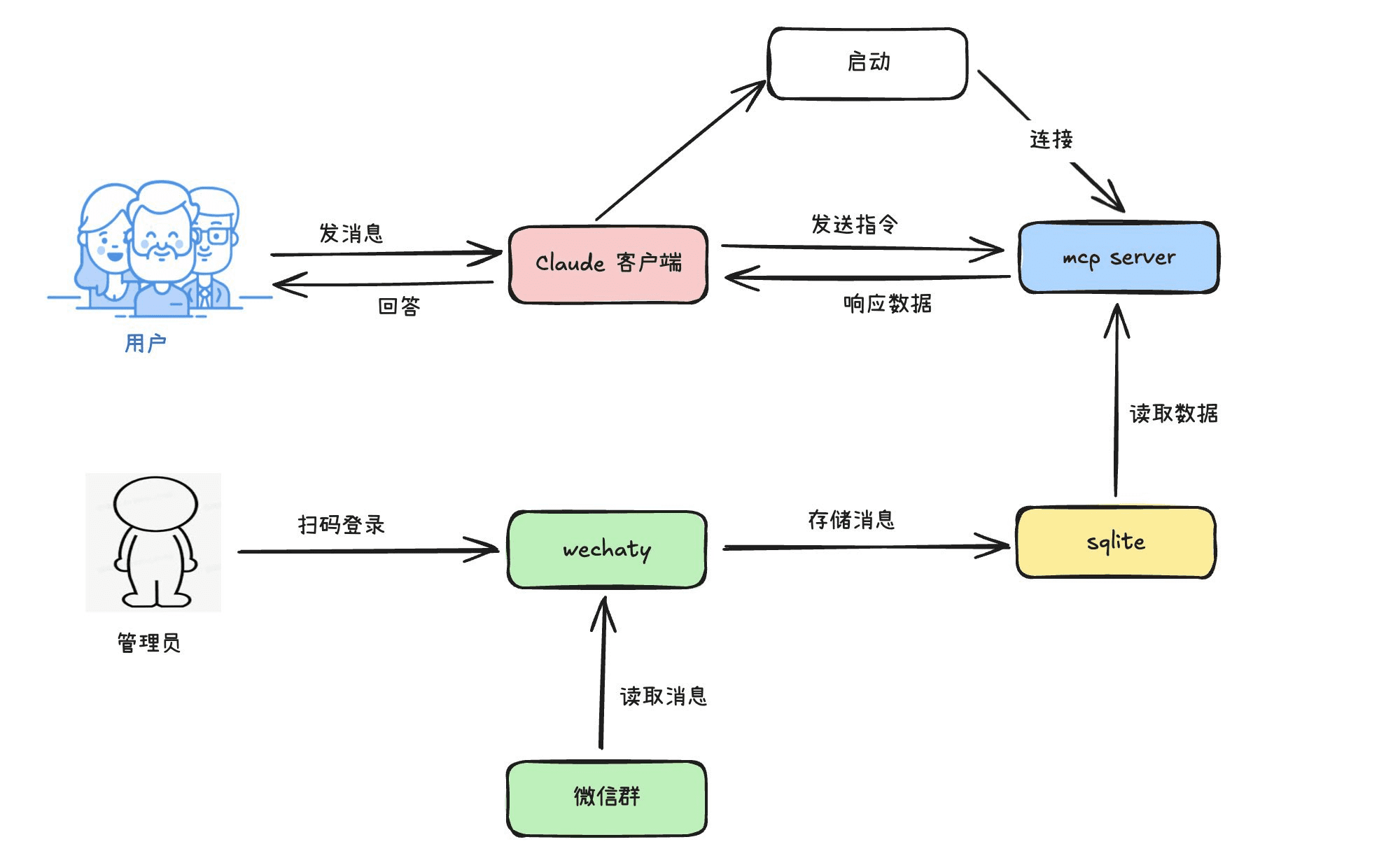

综合介绍
ER-NeRF (Efficient Region-Aware Neural Radiance Fields)是一个开源的说话人物合成系统,发表于ICCV 2023会议。该项目利用区域感知神经辐射场技术,能够高效地生成高保真度的说话人物视频。系统的主要特点是采用区域化处理方案,分别对人物头部和躯干进行建模,并通过创新的音频-空间分解技术,实现了更准确的唇形同步。项目提供了完整的训练和推理代码,支持自定义训练视频,并可使用不同的音频特征提取器(如DeepSpeech、Wav2Vec、HuBERT等)来处理音频输入。该系统在视觉质量和计算效率方面都取得了显著的提升,为说话人物合成领域提供了一个重要的技术解决方案。
新项目:https://github.com/Fictionarry/TalkingGaussian

功能列表
- 高保真度说话人物视频合成
- 区域感知的神经辐射场渲染
- 支持头部和躯干分离建模
- 精确的唇形同步处理
- 多种音频特征提取支持(DeepSpeech/Wav2Vec/HuBERT)
- 自定义视频训练支持
- 音频驱动的人物动画生成
- 平滑的头部运动控制
- 眨眼动作支持(AU45特征)
- LPIPS微调优化功能
使用帮助
1. 环境配置
系统运行环境要求:
- Ubuntu 18.04操作系统
- PyTorch 1.12版本
- CUDA 11.3
安装步骤:
- 创建conda环境:
conda create -n ernerf python=3.10
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
- 安装额外依赖:
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
2. 预处理模型准备
需要下载并准备以下模型文件:
- 人脸解析模型
- 3DMM头部姿态估计模型
- Basel Face Model 2009
3. 自定义视频训练流程
- 视频准备要求:
- 格式:MP4
- 帧率:25FPS
- 分辨率:建议512x512
- 时长:1-5分钟
- 要求每一帧都包含说话人物
- 数据预处理:
python data_utils/process.py data/<ID>/<ID>.mp4
- 音频特征提取(三选一):
- DeepSpeech特征提取:
python data_utils/deepspeech_features/extract_ds_features.py --input data/<n>.wav
- Wav2Vec特征提取:
python data_utils/wav2vec.py --wav data/<n>.wav --save_feats
- HuBERT特征提取(推荐):
python data_utils/hubert.py --wav data/<n>.wav
4. 模型训练
训练分为头部训练和躯干训练两个阶段:
- 头部训练:
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
- 躯干训练:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
5. 模型测试和推理
- 测试模型效果:
# 仅渲染头部
python main.py data/obama/ --workspace trial_obama/ -O --test
# 渲染头部和躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test
- 使用目标音频进行推理:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud <audio>.npy
提示:添加--smooth_path参数可以减少头部抖动,但可能降低姿态准确性。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...