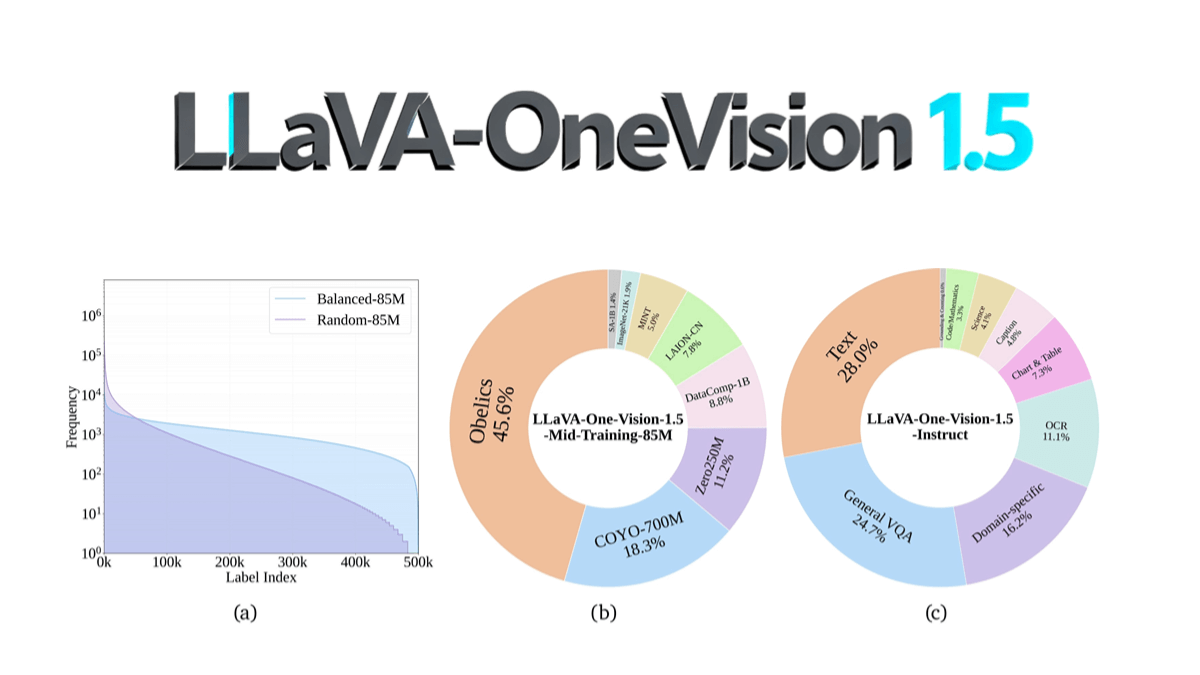
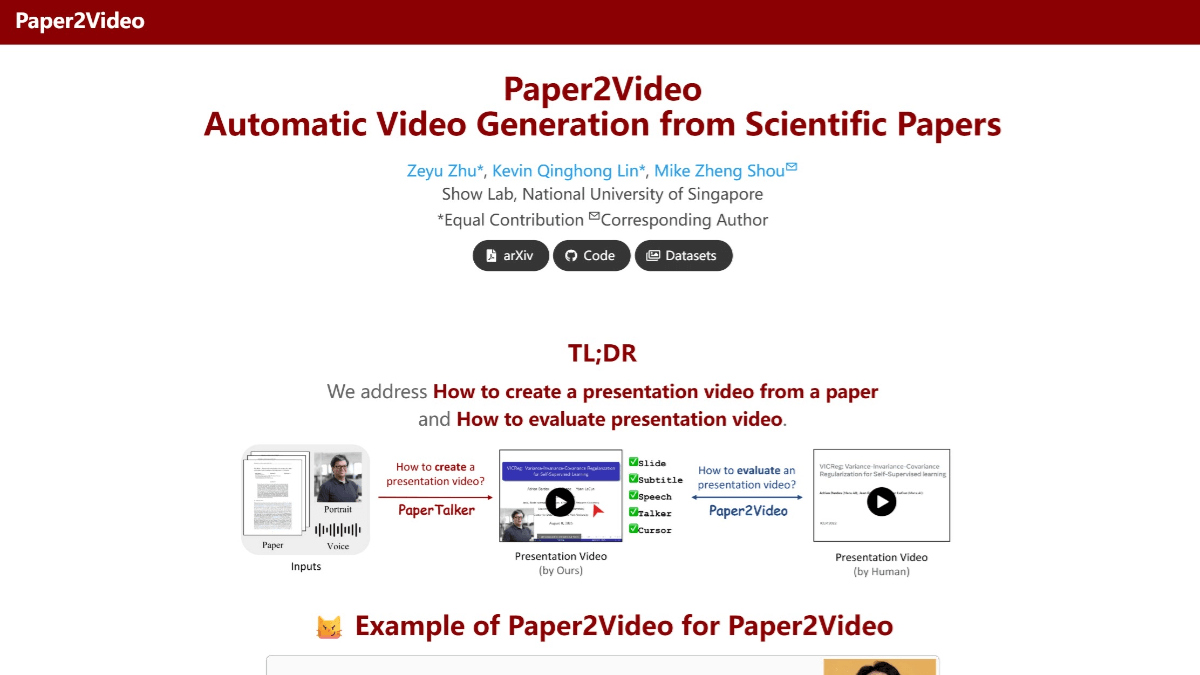
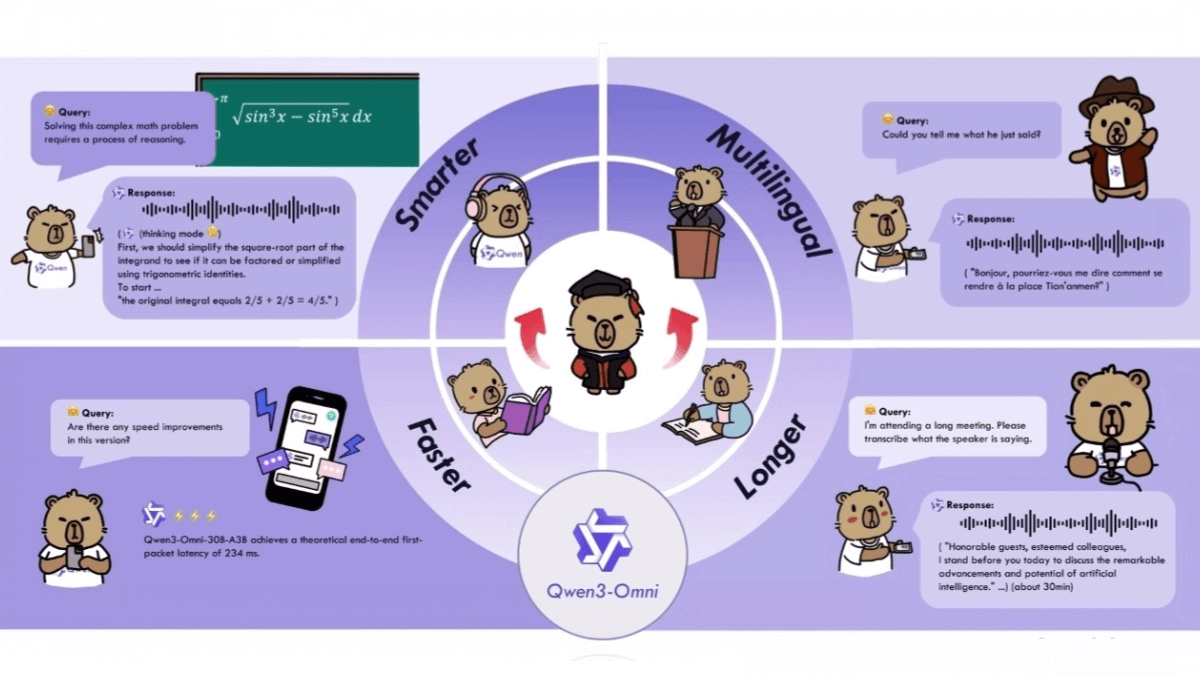
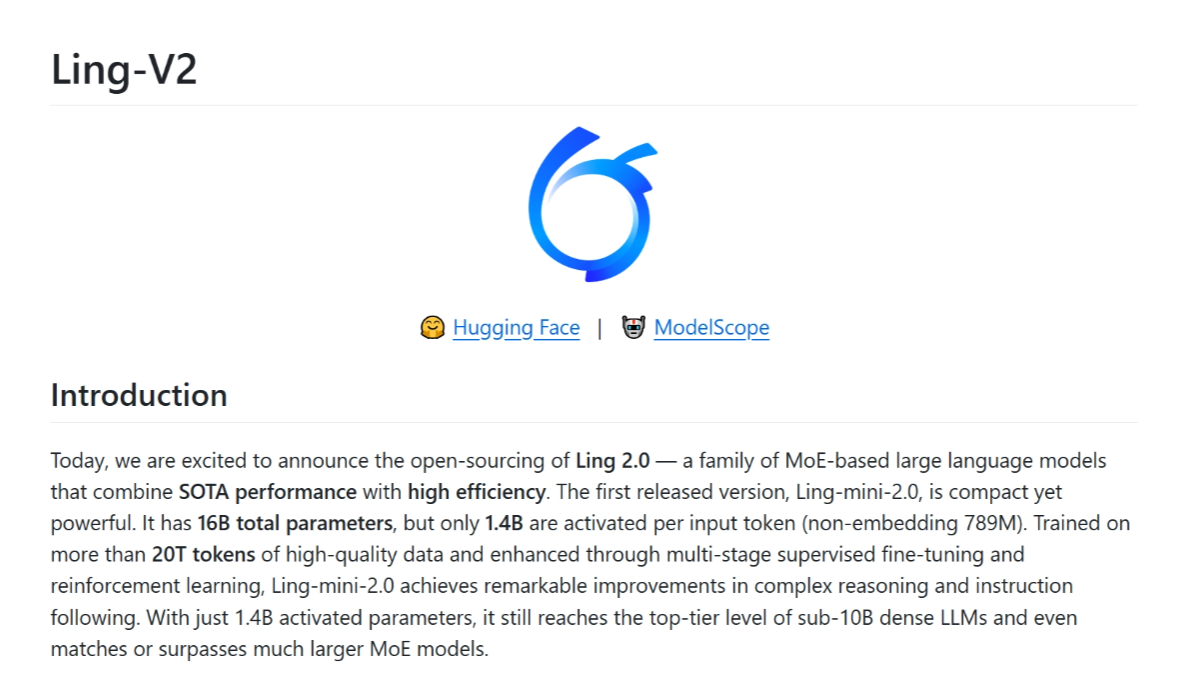
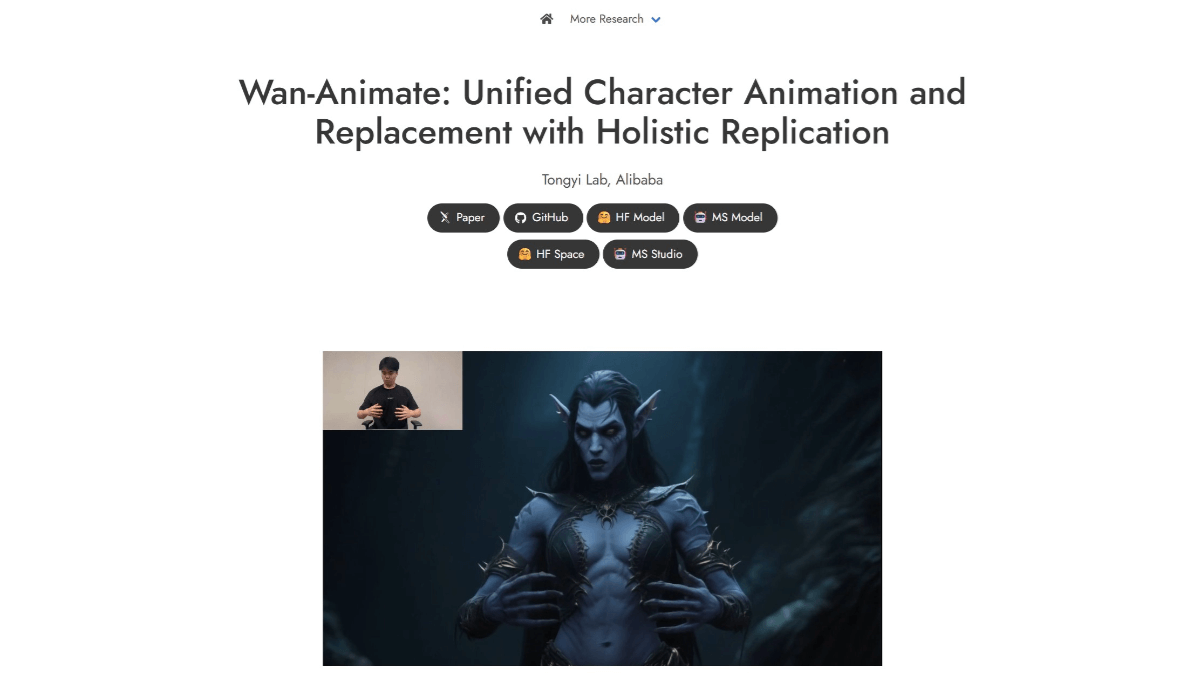
nanochat - Karpathy's free and open source low-cost model training program
nanochat is an open source project released by AI legend and former Tesla AI Director Andrej Karpathy that allows individuals to quickly train a small ChatGPT-like language model at a very low cost and simplicity. The entire project uses only about 800...