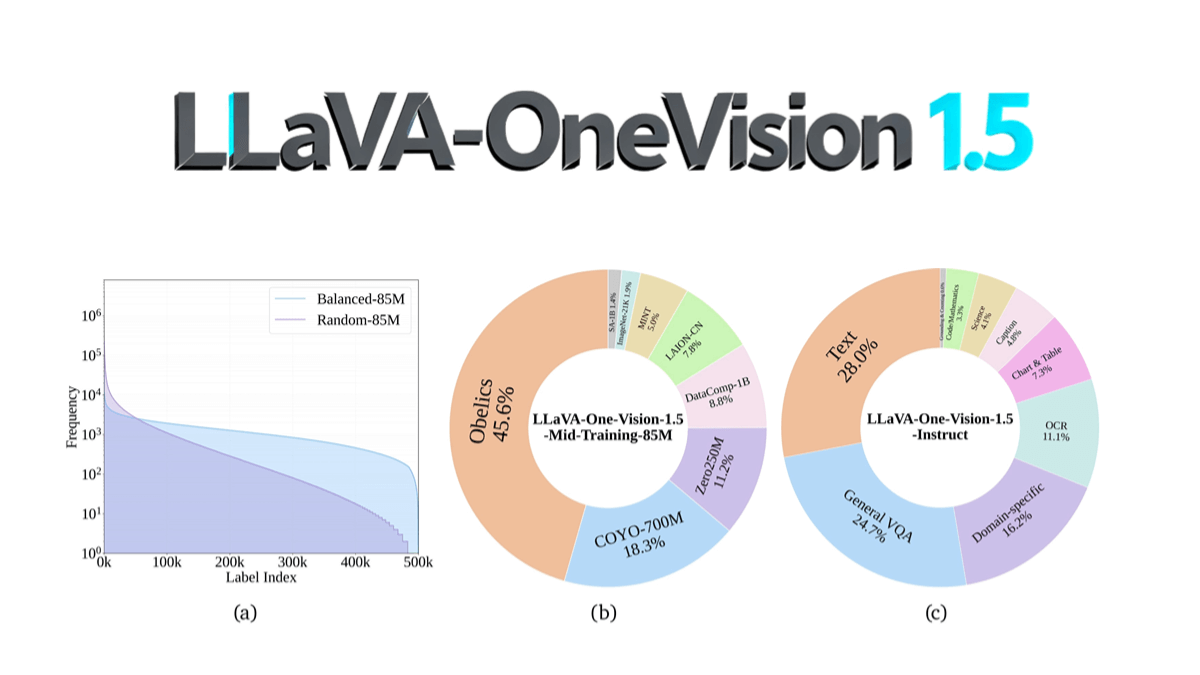
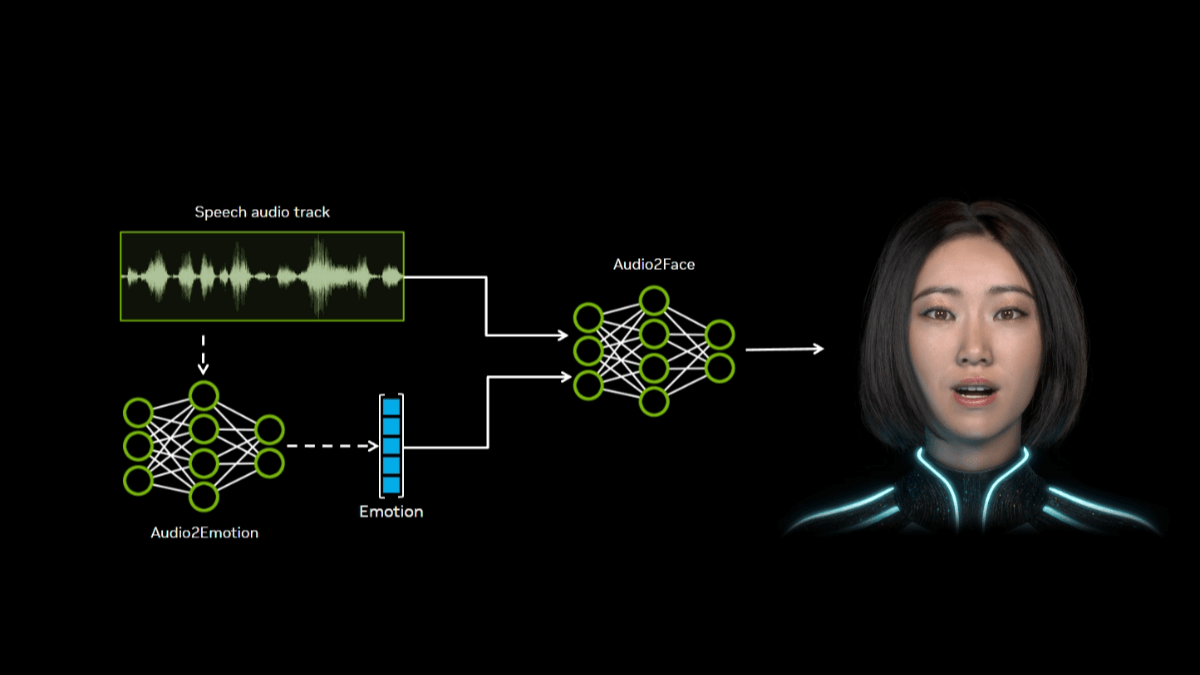
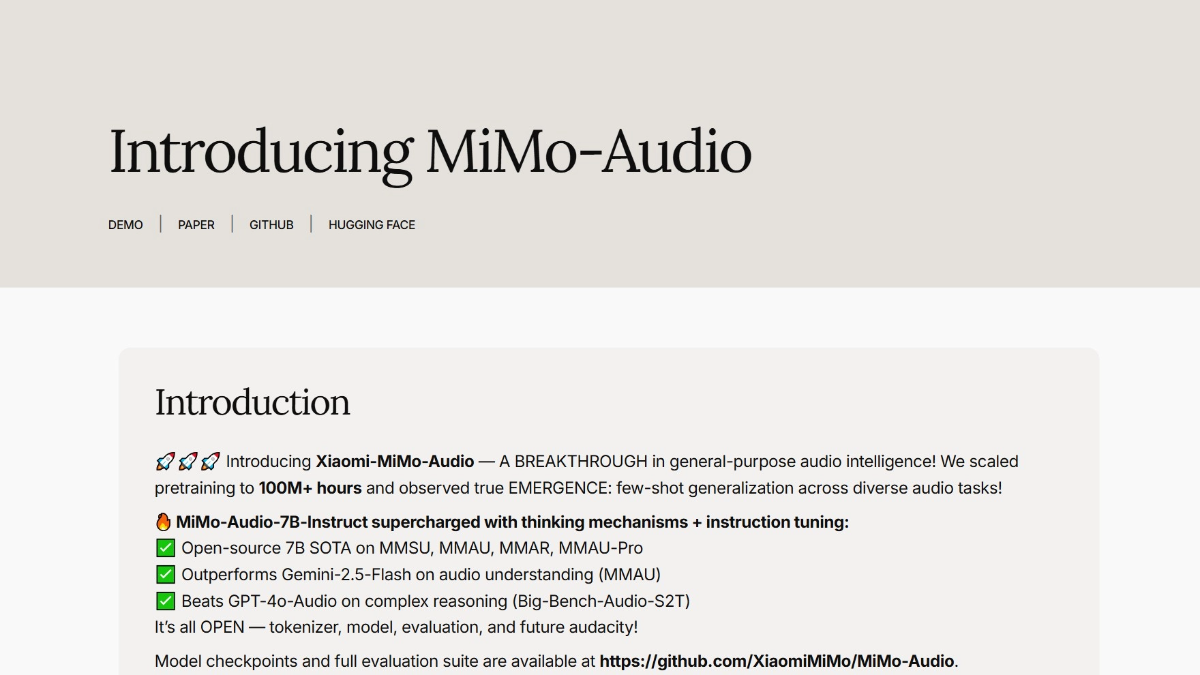
FLM-Audioは、Beijing Zhiyuan Artificial Intelligence Research InstituteとSpin Matrix、Nanyang Technological University of Singaporeが共同開発したネイティブ全二重音声対話マクロモデルで、中国語と英語の両方に対応している。ネイティブの全二重アーキテクチャを採用し、各時間ステップでリスニング、スピーキング、モノローグをマージすることができます...
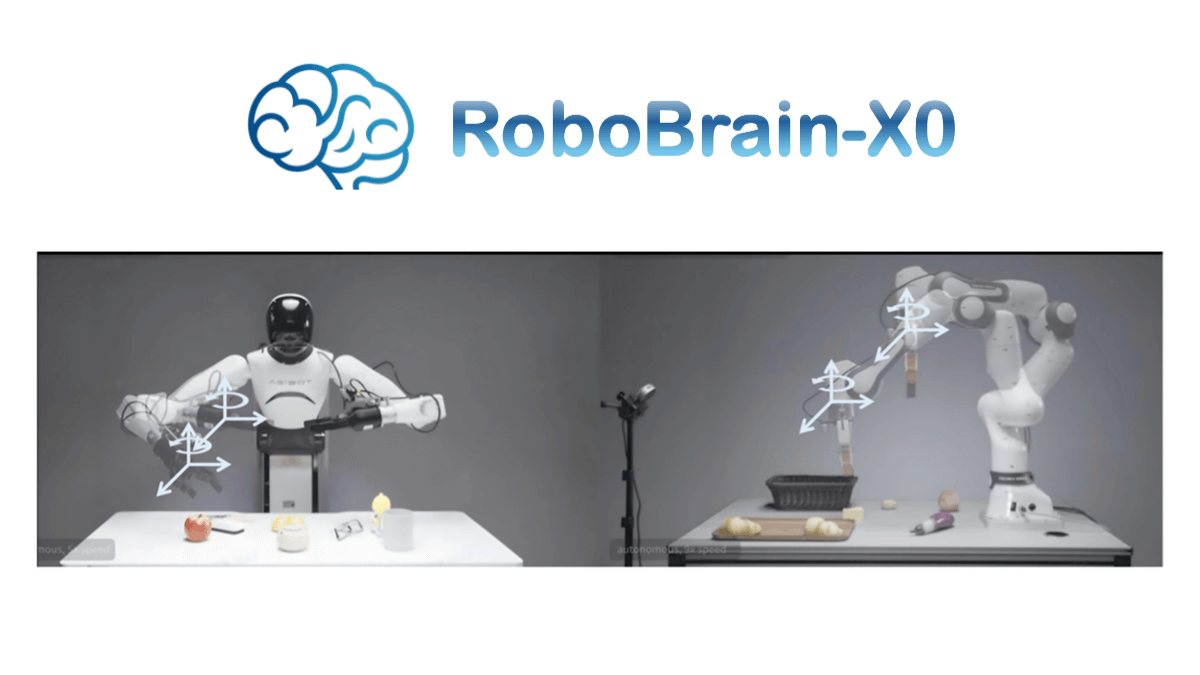
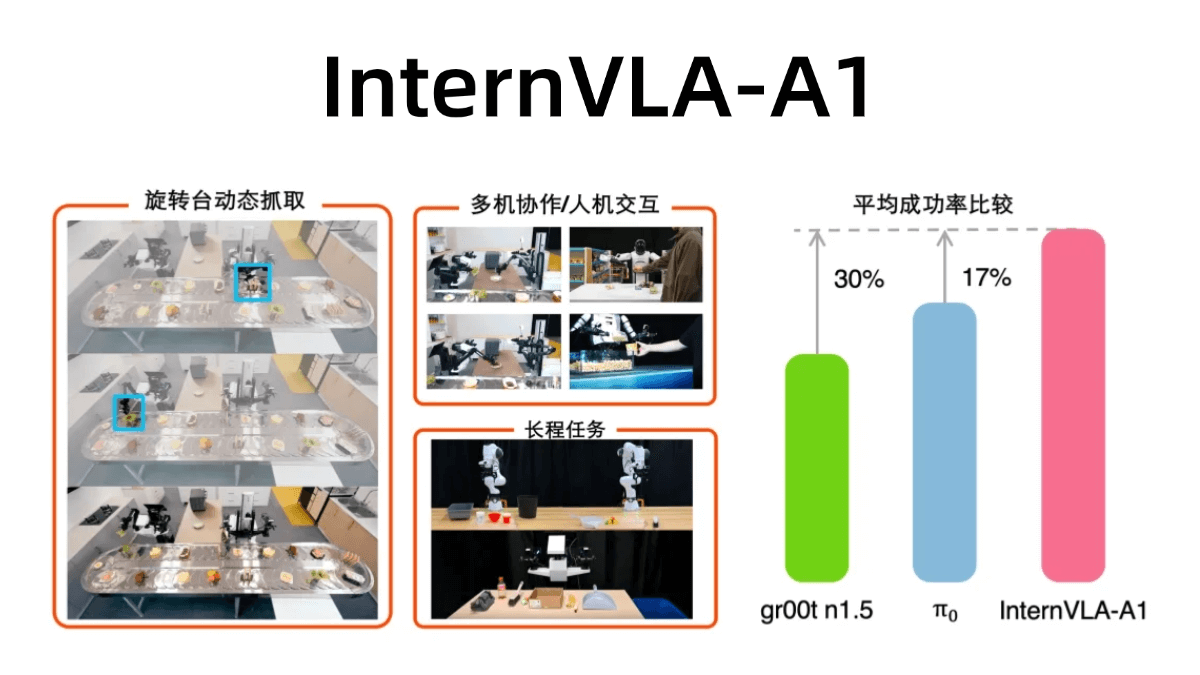
UnifoLM-WMA-0は、Yu Shu Technologyによる複数のクラスのロボットオントロジーにまたがるオープンソースのワールドモデル-アクションアーキテクチャであり、一般的なロボット学習のために設計されている。ワールドモデルとアクションアーキテクチャから構成され、ワールドモデルはロボットと環境の相互作用の物理法則を理解し、アクションアーキテクチャは特定の...
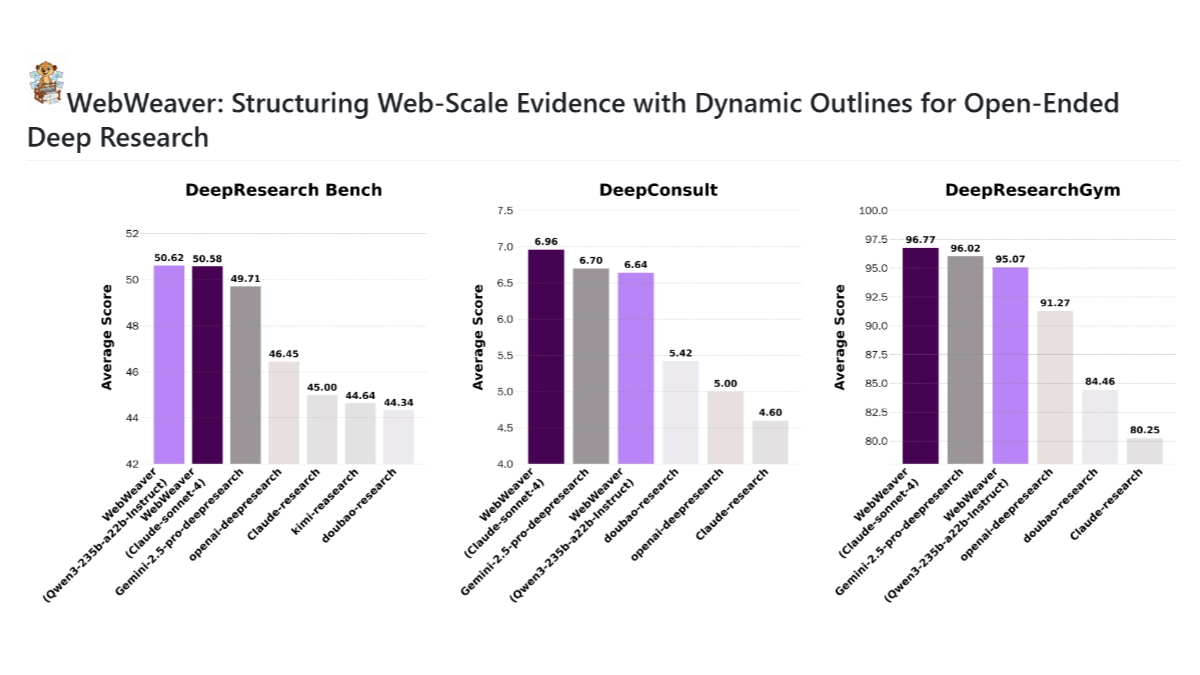
Wenxin Big Model X1.1は、バイドゥが発表したディープシンキングモデルで、ハイブリッド強化学習フレームワークに基づいており、言語理解と生成の向上に重点を置いている。このモデルは、複雑な質問の処理、指示に従うこと、知性の行動のシミュレーションに優れており、知識豊富な回答や高品質のテキストコンテンツを正確に提供することができる。
WeKnoraはTencent WeChatチームのオープンソースで、Large Language Model (LLM)文書理解と意味検索フレームワークに基づいており、複雑な異種文書コンテンツシナリオの構造のために設計され、モジュラーアーキテクチャを使用するように設計されており、マルチモーダル前処理、セマンティックベクターインデキシング、インテリジェントリコールと大規模なモデルの生成推論の統合...