OneFileLLM: Integrating Multiple Data Sources into a Single Text File
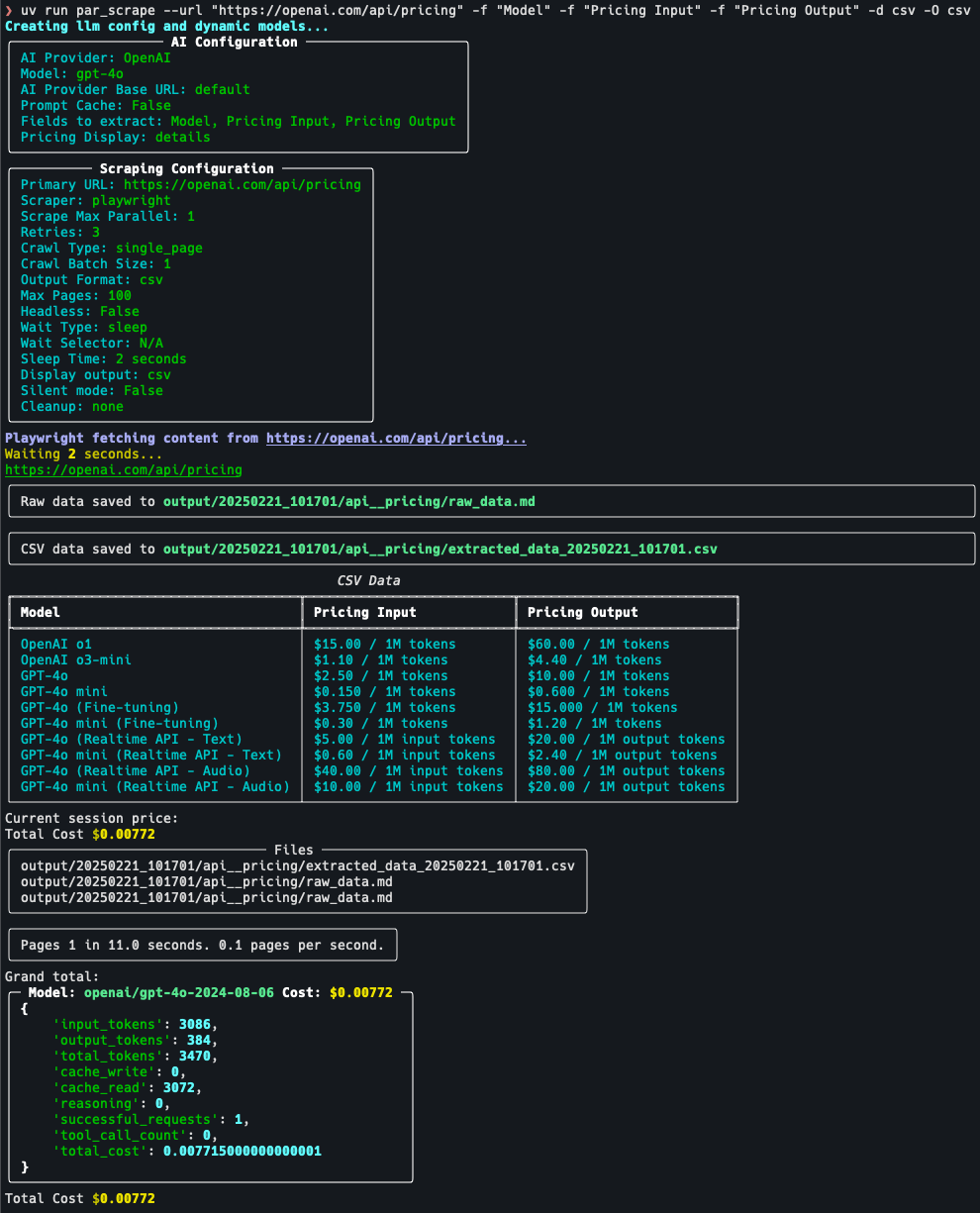
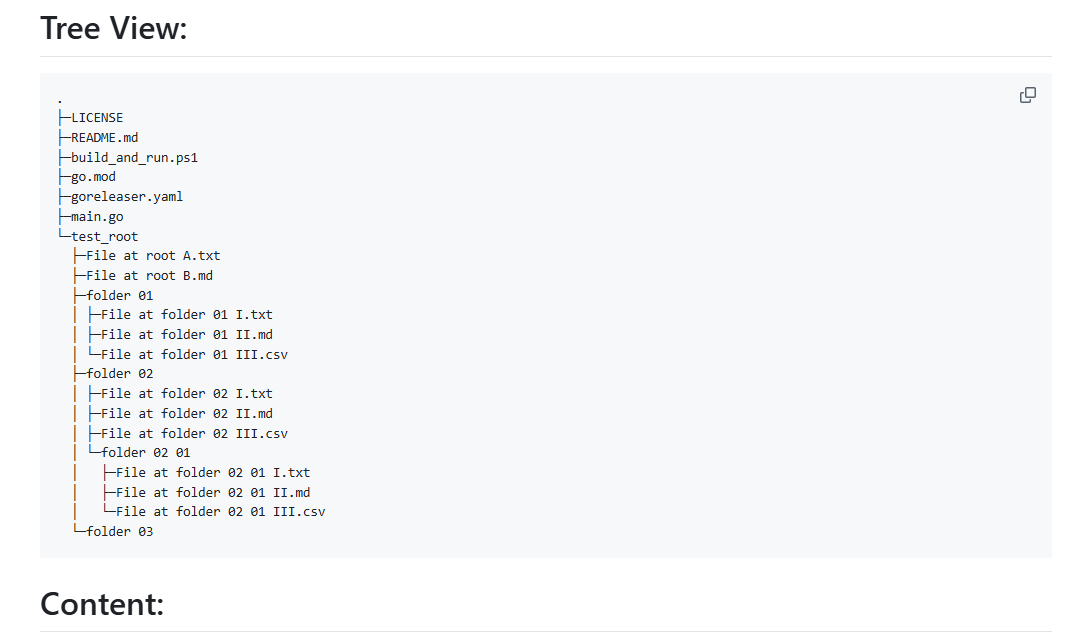
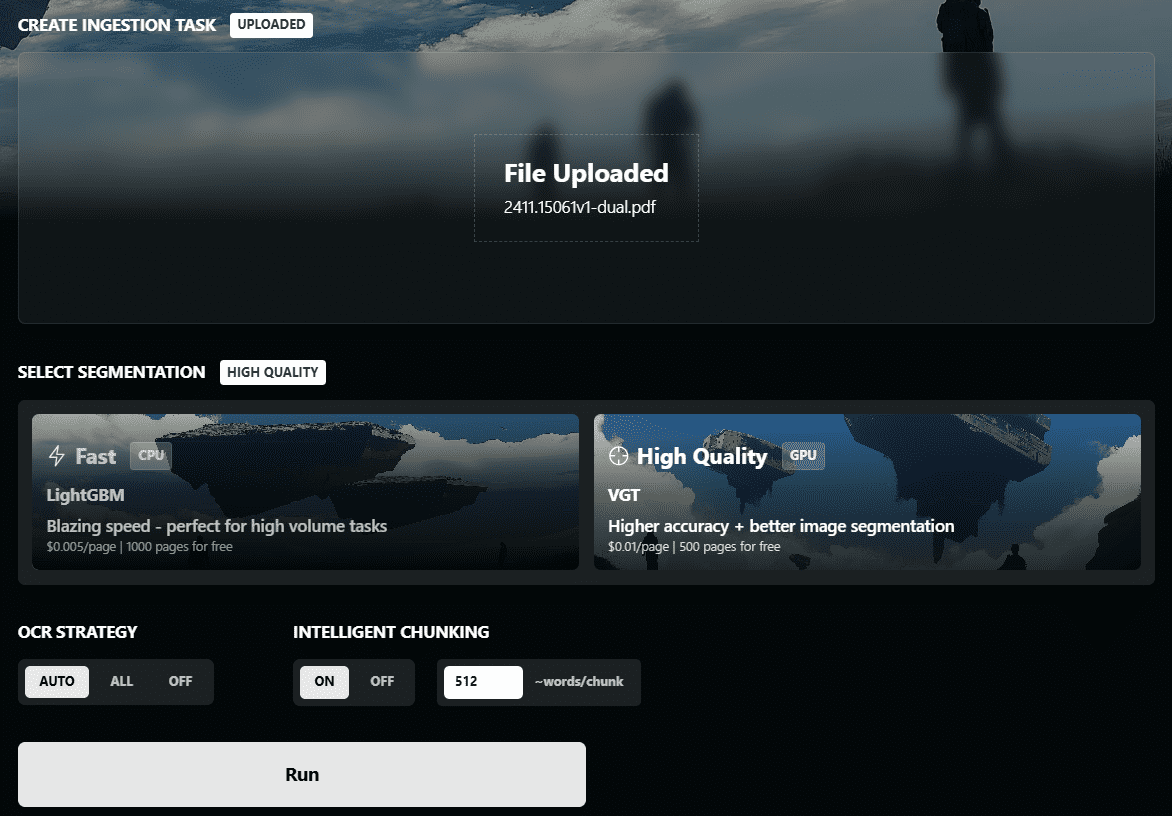
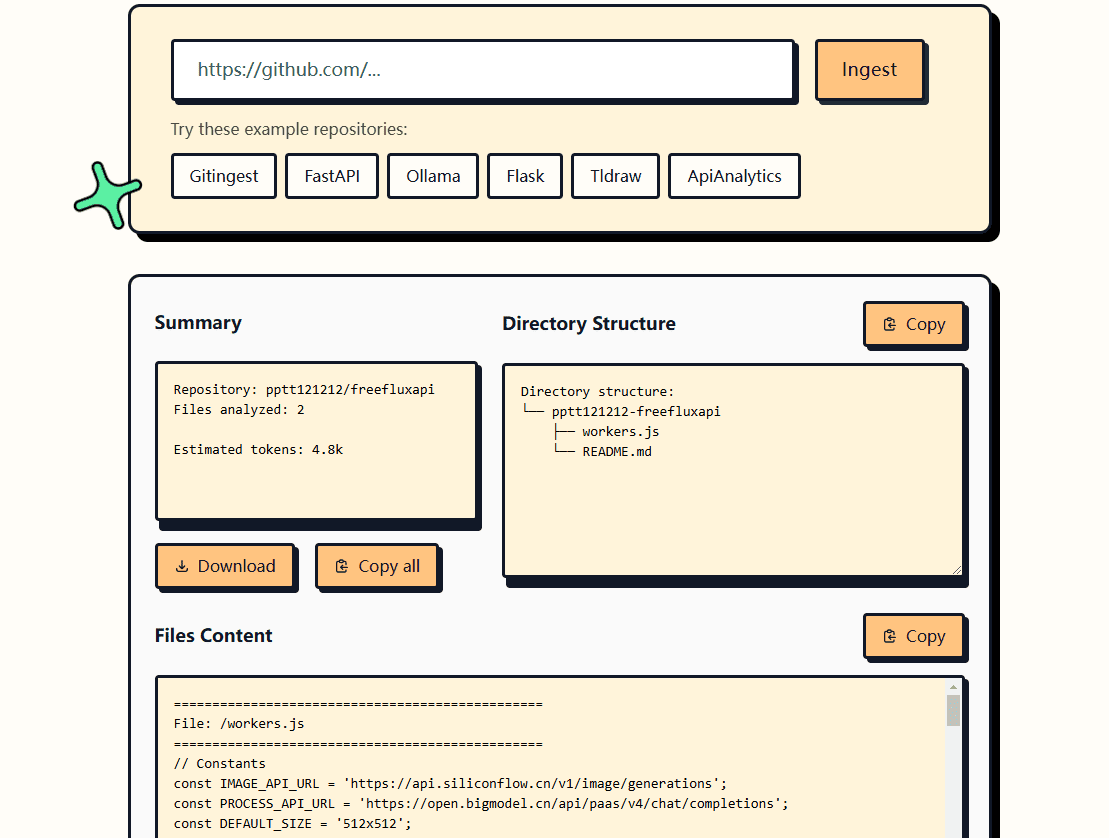
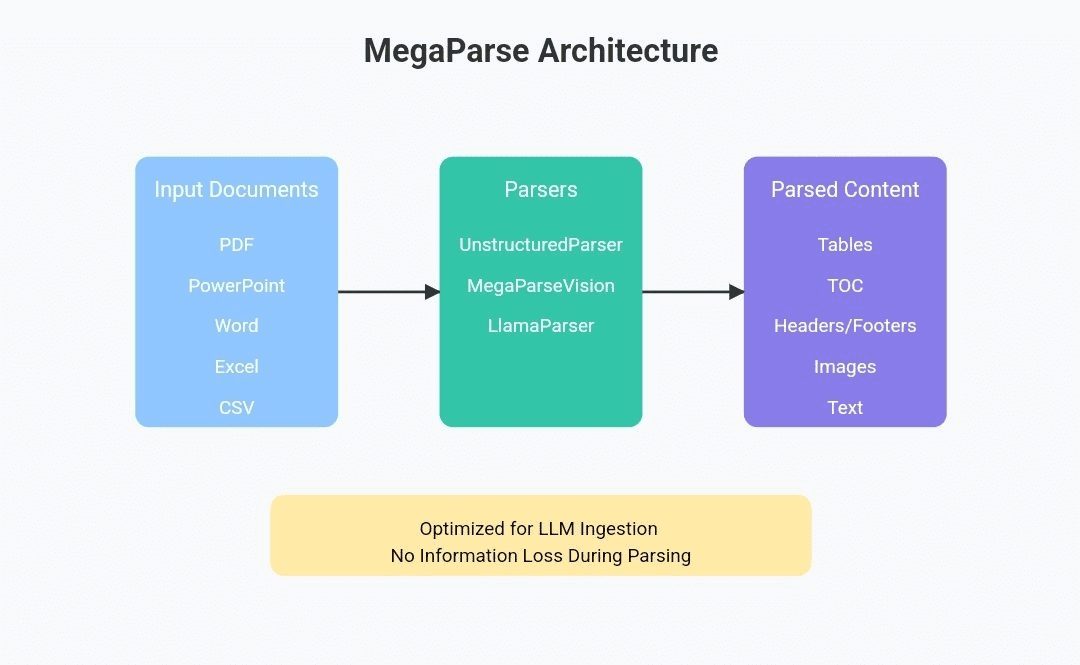
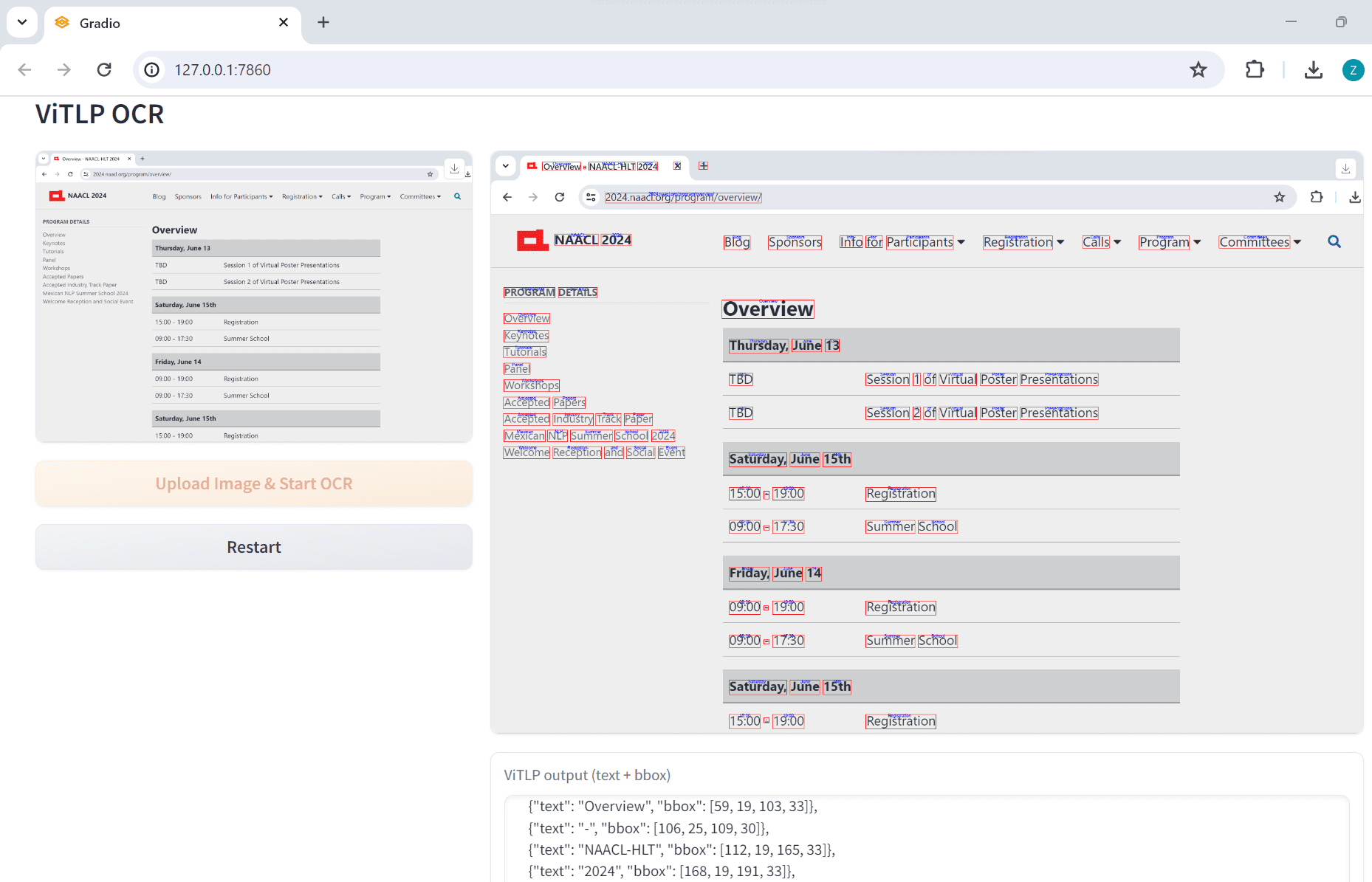
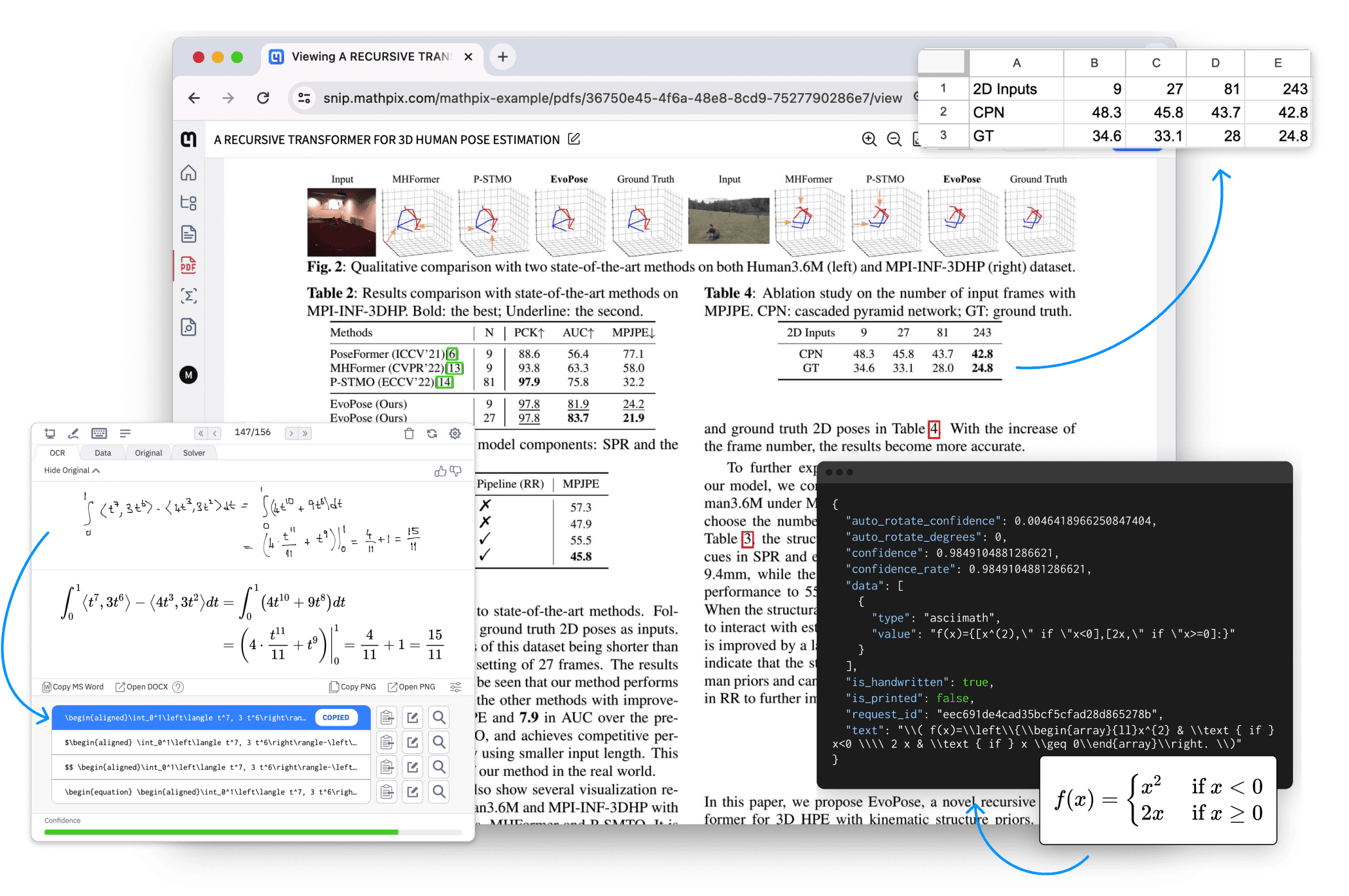
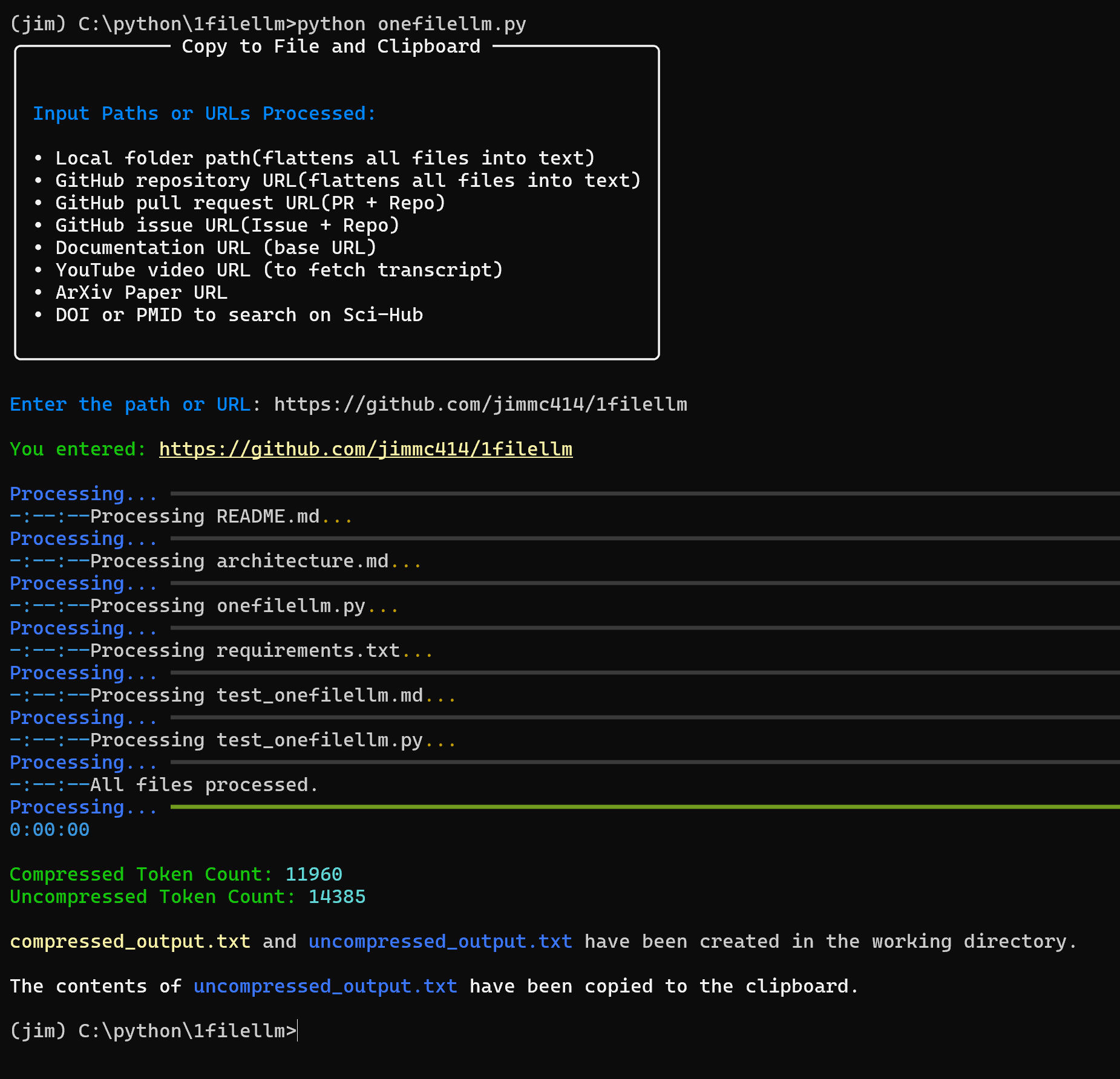
Comprehensive Introduction OneFileLLM is an open source command line tool designed to consolidate multiple data sources into a single text file for easy input into Large Language Models (LLMs). It supports processing GitHub repositories, ArXiv papers, YouTube video transcriptions, web...