
Qwen3-Omni - Omnimodal AI model launched by Ali Tongyi

What is Qwen3-Omni
Qwen3-Omni is a fully modal AI model introduced by Ali Tongyi team that can handle multiple data types such as text, image, audio and video, and supports text interactions in 119 languages with low latency and high controllability. With its innovative architectural design and robust performance, Qwen3-Omni outperforms several well-known models in audio and audio-video benchmarks. The model supports personalized customization and tool invocation, and can be widely used in content creation, intelligent customer service, education, medical assistance and other fields, bringing users an efficient and intelligent multimodal interaction experience.
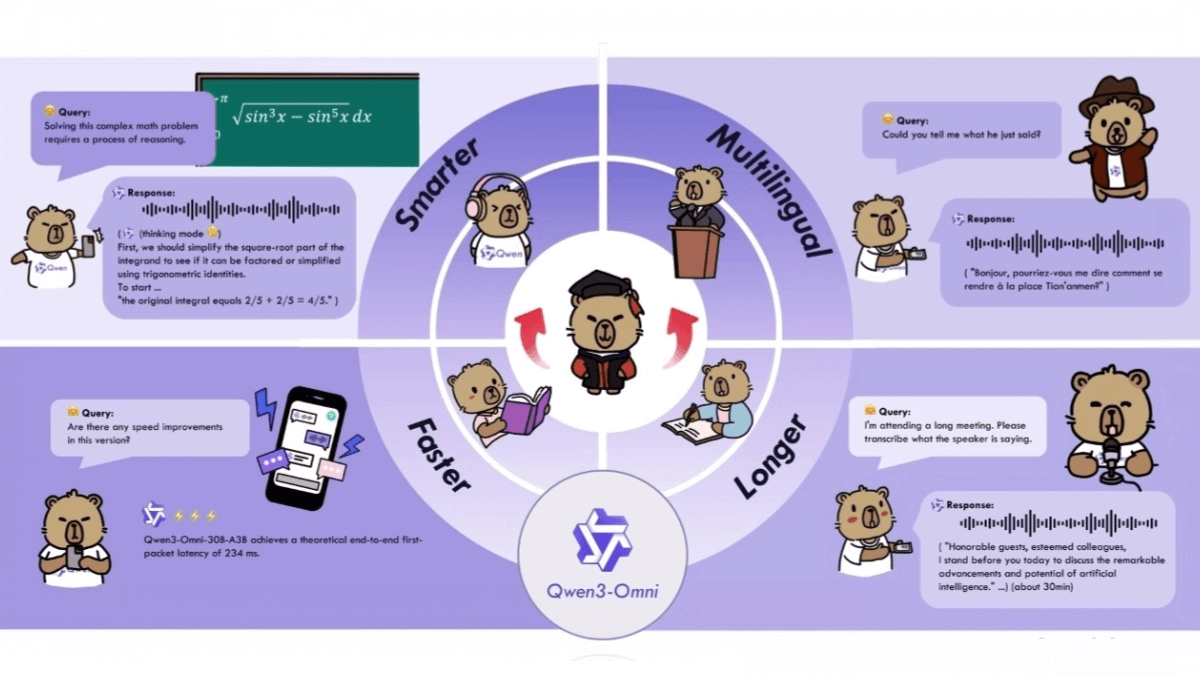
Features of Qwen3-Omni
- full-modal interaction: The model can seamlessly handle multi-modal data such as text, image, audio and video, and realize cross-modal fusion processing, such as generating corresponding image or audio content based on text, or understanding the information in images and audio and outputting text descriptions.
- High performanceQwen3-Omni has achieved excellent results in numerous audio and video benchmarks, outperforming well-known strong models.
- Multi-language support: Supports text interaction in multiple languages, can, understand and generate text content in multiple languages, meets the needs of users of different languages, and has strong globalized language capabilities.
- rapid response: The low latency of the model's end-to-end audio dialog enables fast processing and response to incoming audio, providing a real-time interactive experience.
- Long Audio Processing: The model supports up to 30 minutes of audio comprehension and can handle longer audio content without performance degradation or inability to process.
- Personalization: Users can customize the model's system prompts and other words according to their own needs, and modify the reply style, persona, etc., so that the model can better adapt to different usage scenarios and user preferences.
- Tooling capabilities: The model is equipped with powerful built-in tool invocation functions, and can be efficiently integrated with external tools or services to realize more complex functions and applications, expanding the application scope and usefulness of the model.
Performance of the Qwen3-Omni
- Comprehensive performance evaluation: The Qwen3-Omni demonstrates excellent multimodal processing capabilities. In unimodal tasks, the performance is comparable to that of the Qwen family of unimodal models of the same size, with a significant advantage in audio tasks.
- 36 audio/video benchmarks: Qwen3-Omni achieves best-in-class performance in the open source space in 32 tests and top-of-the-industry (SOTA) in 22 tests, outperforming powerful closed-source models such as Gemini-2.5-Pro, Seed-ASR, GPT-4o-Transcribe, and more.
Core Benefits of Qwen3-Omni
- True full modal capability: Qwen3-Omni is a native all-modal large model that can simultaneously process text, image, audio and video data in multiple modalities with excellent performance in each modality without degrading the processing power of a single modality due to multi-modal fusion.
- Powerful performance and efficiency: Qwen3-Omni outperforms many well-known models in audio and audio-video benchmarks, demonstrating superior performance. The model features low latency - as low as 211 milliseconds for audio conversations and 507 milliseconds for video conversations - and responds quickly to user input for a smooth interactive experience.
- Rich Language SupportThe model supports 119 kinds of text language interactions and a variety of speech understanding and generation languages, which enables the model to meet the needs of users of different languages globally, and has a strong potential for internationalization.
- Highly customizable and flexibleUsers can personalize the model according to their own needs, such as modifying the reply style, persona, etc., and adjusting the model's behavior through system prompt words, etc., so that the model can better adapt to different application scenarios and user preferences.
- Open Source and Innovative Architecture Design: Qwen3-Omni is based on innovative Thinker-Talker architecture and multi-codebook technology, etc., to improve the performance and efficiency of the model and provide developers with more room for innovation. The open source nature of the model makes it easier for developers to conduct research and application development, and promotes the further development of the technology.
What is Qwen3-Omni's official website?
- Project website:: https://qwen.ai/blog?id=65f766fc2dcba7905c1cb69cc4cab90e94126bf4&from=research.latest-advancements-list
- GitHub repository:: https://github.com/QwenLM/Qwen3-Omni
- HuggingFace Model Library:: https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
- Technical Papers:: https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
People for whom Qwen3-Omni is suitable
- content creator: The model generates high-quality text, image, audio, and video creative material, providing creators with inspiration and efficiency gains.
- Corporate & Customer Service Team: With multi-language text and voice interaction capabilities, the model can quickly and accurately answer customer questions, improving customer service efficiency and user experience.
- Educators and students: The model can generate personalized learning materials, assist teachers in designing teaching content to meet different learning needs, and improve the efficiency of teaching and learning.
- Medical Industry Practitioners: The model can process multimodal data such as medical images and voice recordings to assist doctors in diagnosing and formulating treatment plans, and improve the efficiency of medical work.
- Entertainment and multimedia industry practitioners: Models can create music, generate video scripts, design game plots, etc., providing rich creative materials for entertainment and multimedia content creation.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...