MOSS-Speech - Fudan University's open source speech-to-speech grand modeling

What is MOSS-Speechs
MOSS-Speech is an open source speech-to-speech (Speech-to-Speech) big model by Prof. Qiu Xipeng's team at Fudan University. It breaks through the traditional speech processing, without the need for text guidance, and directly comprehends and generates speech, which can capture non-text elements such as intonation and emotion, making speech interaction more natural. The model is designed based on pre-trained text LLM, and through modal layering and two-phase pre-training, it integrates speech understanding and generation capabilities, supports both speech and text input and output, and realizes cross-modal interactions.MOSS-Speech adopts advanced speech coding technology, which allows the model to understand the meaning of speech while compressing it. The frozen pre-training strategy introduces speech processing capabilities while retaining the original LLM capabilities.
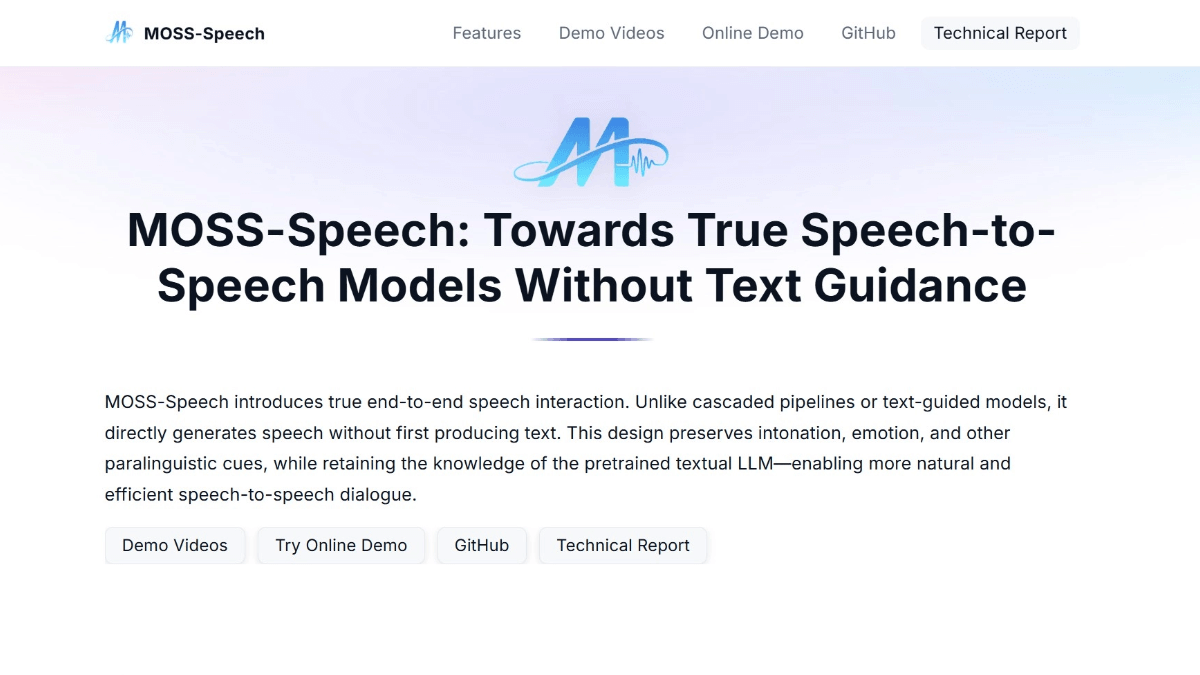
Features of MOSS-Speechs
- Voice-to-speech direct interaction: No need for text conversion, directly processing voice input and generating voice output, supporting natural and smooth voice dialog.
- Speech Understanding and Generation: The ability to understand the semantics, intonation and emotions in speech and to generate speech with emotion and intonation makes communication more vivid and natural.
- cross-modal interaction: It supports two-way interaction between voice and text, users can choose voice or text input, and the model will be output in the corresponding modality to meet the needs of different scenarios.
- multi-scenario application: It is applicable to intelligent voice assistants, voice interaction devices, etc., providing users with efficient and natural voice interaction experience and enhancing the interactive performance of the devices.
- Powerful speech modeling capabilities: Excellent performance in speech modeling and spoken quiz tasks, capable of processing complex speech information, providing accurate speech understanding and generating results.
Core Benefits of MOSS-Speechs
- True speech-to-speech modeling: Processes speech input and output directly without relying on text conversion, preserving the natural characteristics and emotional expression of speech.
- Bimodal native support: Supporting both voice and text interaction, users can select input and output methods according to their needs, realizing flexible cross-modal communication.
- Advanced speech coding technology: Through a special coding system, it is possible to understand the meaning of speech while preserving its acoustic characteristics, enhancing the accuracy and naturalness of voice interaction.
- Freezing pre-training strategies: While retaining the powerful reasoning ability and knowledge reserve of textual LLM, it introduces speech comprehension and generation capabilities to realize efficient knowledge migration and modal fusion.
- Excellent performance: Leading results in speech modeling and spoken quiz tasks demonstrate its strong capabilities in speech understanding and generation.
- Rich application scenariosIt is suitable for intelligent voice assistants, voice interaction devices, etc., providing users with a more natural and efficient voice interaction experience and meeting a variety of practical application requirements.
What is MOSS-Speechs official website?
- Project website:: https://moss-speech.open-moss.com/
- Github repository:: https://github.com/OpenMOSS/MOSS-Speech
- HuggingFace Model Library:: https://huggingface.co/collections/OpenMOSS-Team/moss-speech
- arXiv Technical Paper:: https://arxiv.org/pdf/2510.00499
- Online Experience Demo:: https://huggingface.co/spaces/OpenMOSS-Team/MOSS-Speech
Who is MOSS-Speechs for?
- smart device makerMOSS-Speech can be integrated into smart speakers, smart car systems and other devices to enhance the voice interaction experience of the product.
- software developer: The ability to develop voice interaction applications, such as voice assistants, voice customer service, etc., using their APIs or open source code.
- artificial intelligence researcher: Can be used to study cutting-edge technologies in the fields of speech recognition, speech synthesis and multimodal interaction.
- Corporate Customers: Suitable for enterprises that need efficient voice interaction solutions, such as customer service centers, smart homes and other fields.
- regular user: You can directly use voice assistants or devices developed based on MOSS-Speech to enjoy more natural and convenient voice interaction services.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...