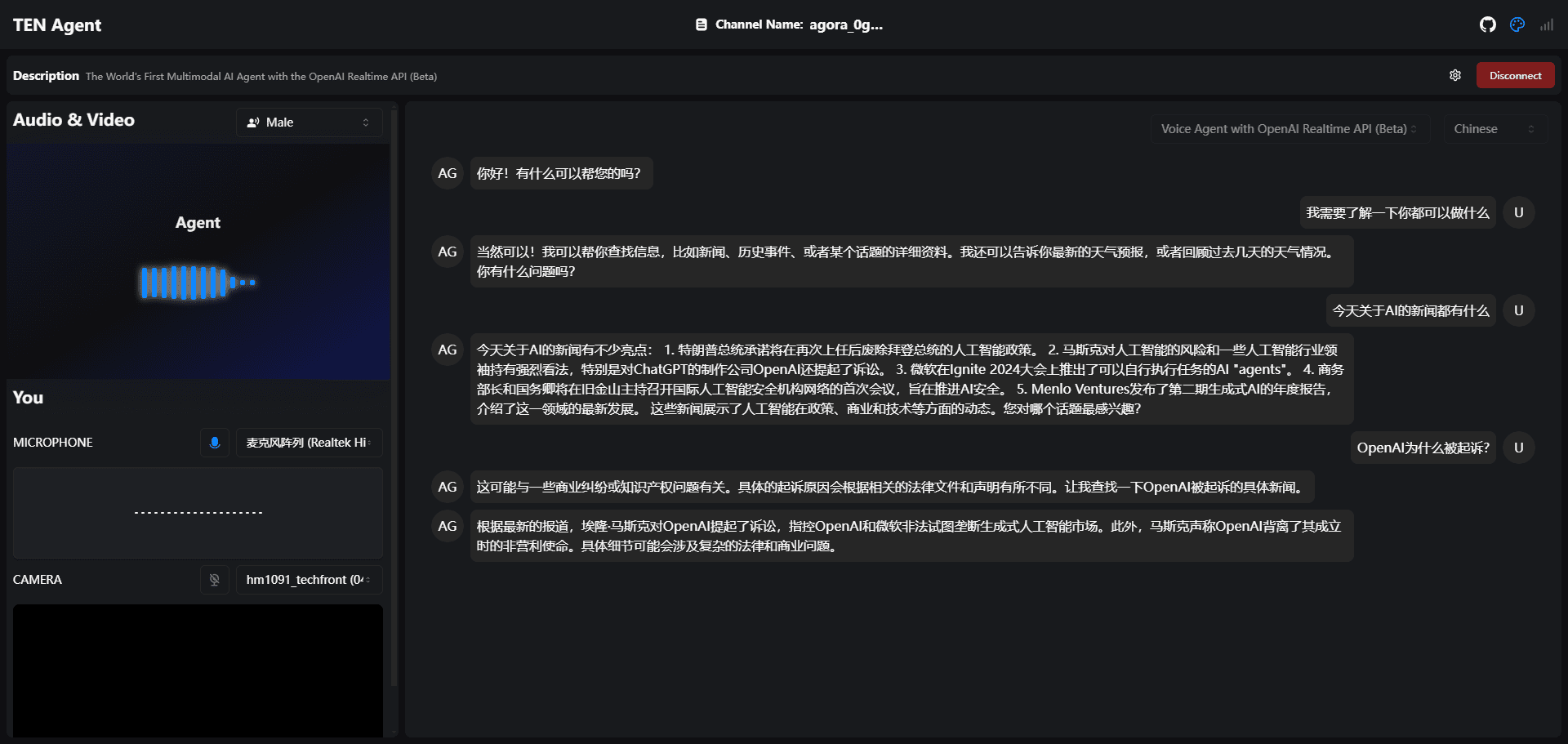
LM Speed: Rapidly Test Large Model API Performance

General Introduction
LM Speed is a tool designed specifically for AI developers and is available as an online service at lmspeed.net. Its core function is to test and analyze the performance of language model APIs, helping users to quickly identify speed bottlenecks and optimize calling strategies. The tool supports a variety of interfaces, including the OpenAI API, and provides real-time data monitoring and detailed performance reports. Whether you're an individual developer or a team, LM Speed makes it easy to compare the performance of different models and vendors through intuitive data charts and automated tests.

Function List
- Real-time performance monitoring: displays multi-dimensional data such as processing per second token Number (TPoS).
- Comprehensive performance evaluation: Measure core metrics such as first token latency, response time and more.
- Data Visualization: Generate rich charts to visualize performance trends.
- Automated stress testing: five consecutive rounds of testing to ensure reliable data.
- One-click report generation: automatically create professional test reports, support export and sharing.
- Quick Test for URL Parameters: Launch the test directly from the link without manual input.
- Historical data saving: record test results and support trend analysis.
Using Help
Use of online services
- Access to the website
Open your browser and go to https://lmspeed.net. - Input test parameters
Fill in the page form with the following information:baseUrl: API service address, e.g.https://api.deepseek.com/v1TheapiKey: Your API key.modelId: the ID of the model to be tested, e.g.free:QwQ-32BThe
- startup test
Click the "Start Test" button and the system will automatically run five rounds of stress tests. During the test, you will see real-time data updates, including TPoS and response times. - View Results
Once the test is complete, the page displays detailed graphs and metrics, such as first token latency and average performance. You can click the "Generate Report" button to download the PDF or share it with your team. - Quick Test of URL Parameters
If you don't want to enter it manually, you can start the test directly with a link. Example:
https://lmspeed.net/?baseUrl=https://api.suanli.cn/v1&apiKey=sk-你的密钥&modelId=free:QwQ-32B
After opening the link, the test starts automatically. Note: For security reasons, it is recommended not to pass the API key directly in the URL.
Local Deployment Installation Process
- Preparing the environment
Make sure your computer has Git, Node.js (v16 or higher recommended), Docker, and Docker Compose installed; if not, download and install them first. - clone warehouse
Open a terminal and enter the following command to download the code:
git clone https://github.com/nexmoe/lm-speed.git
cd lm-speed
- Docker Deployment
- establish
docker-compose.ymlfile, copy the officially provided code:version: '3.8' services: app: image: nexmoe/lmspeed:latest ports: - "8650:3000" environment: - DATABASE_URL=postgresql://postgres:postgres@db:5432/nexmoe - NODE_ENV=production depends_on: - db restart: always db: image: postgres:16 restart: always environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: postgres POSTGRES_DB: nexmoe volumes: - postgres_data:/var/lib/postgresql/data volumes: postgres_data: - Runs in the terminal:
docker-compose up -d - After successful deployment, access the
http://localhost:8650Viewing Services.
- manual deployment
- Install the dependencies:
npm install - Copy and configure environment variables:
cp .env.example .envcompiler
.envfile, fill in the database address and API configuration. - Start the service:
npm run dev - interviews
http://localhost:3000The
Featured Function Operation
- real time monitoring
When testing online, the page dynamically displays TPoS and response time changes. You can hover over the graphs with your mouse to see the exact values. - automated test
After clicking "Start Test", the system automatically conducts five rounds of testing. The results of each round will be recorded, and finally the average value and fluctuation range will be generated to help you judge the stability of the API. - Report Export
At the end of the test, click "Export Report" and select the PDF format. The report contains the test environment, performance metrics and graphs, and is suitable for team sharing or archiving. - Historical data analysis
The online service keeps a record of your tests. After logging in, go to the "History" page to view previous test results and performance trends.
caveat
- Make sure the API key is valid or the test will fail.
- When deploying locally, check that the firewall has ports open (default 3000 or 8650).
- If the chart is loading slowly, there may be a network problem, so we recommend refreshing the page and retrying.
With these steps, you can test the performance of the Language Modeling API online or locally with LM Speed. The operation is simple, the results are clear and very useful.
application scenario
- Developers choose API services
Developer testing with LM Speed DeepSeek and APIs such as Silicon Flow to select the vendor best suited for the project. - Team Optimization Model Calling
AI teams use it to monitor the performance of APIs under high load, adjusting call strategies to improve application efficiency. - Researchers analyze performance fluctuations
- The researchers studied the changes in the model's performance under different conditions through five rounds of testing and historical data to write the academic report.
QA
- What APIs does LM Speed support?
It mainly supports APIs in OpenAI format, such as DeepSeek, Suanli, and so on. As long as the API is compatible with the OpenAI SDK, it can be tested. - What about erratic test results?
Check that the network connection is stable, or increase the number of test rounds (local deployments can modify the code). Large fluctuations in results may be an issue with the API provider. - Do I have to pay for it?
The online service is currently free, but functionality may be limited. Local deployment is completely free and the code is open source.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...