DeepSeek-OCR - DeepSeek open source optical character recognition model

What is DeepSeek-OCR?
DeepSeek-OCR is DeepSeek The team's open-source, advanced optical character recognition (OCR) model converts text into images using "optical compression in context" technology that utilizes visual token Compression and decoding to realize efficient long text processing. Its technical features include high compression ratio (accuracy up to 97% at 10x compression), joint vision-language understanding, multi-structure and multi-format support (JPG, PNG, PDF, etc. and multi-language recognition), end-to-end VLM architecture, etc. It can be used in a wide range of application scenarios to process long text and complex documents. Wide range of application scenarios, can handle long text, complex documents, multi-language support, support for localized deployment. Significant performance advantages, high efficiency (a single A100-40G graphics card supports more than 200,000 pages of training data generation per day), low latency (mobile devices can realize real-time recognition at 15 frames per second, with a latency of less than 100 milliseconds), and high adaptability (recognition accuracy of up to 98.7% in complex scenarios). The open source code and model weights have been released for developers' convenience.
Features of DeepSeek-OCR
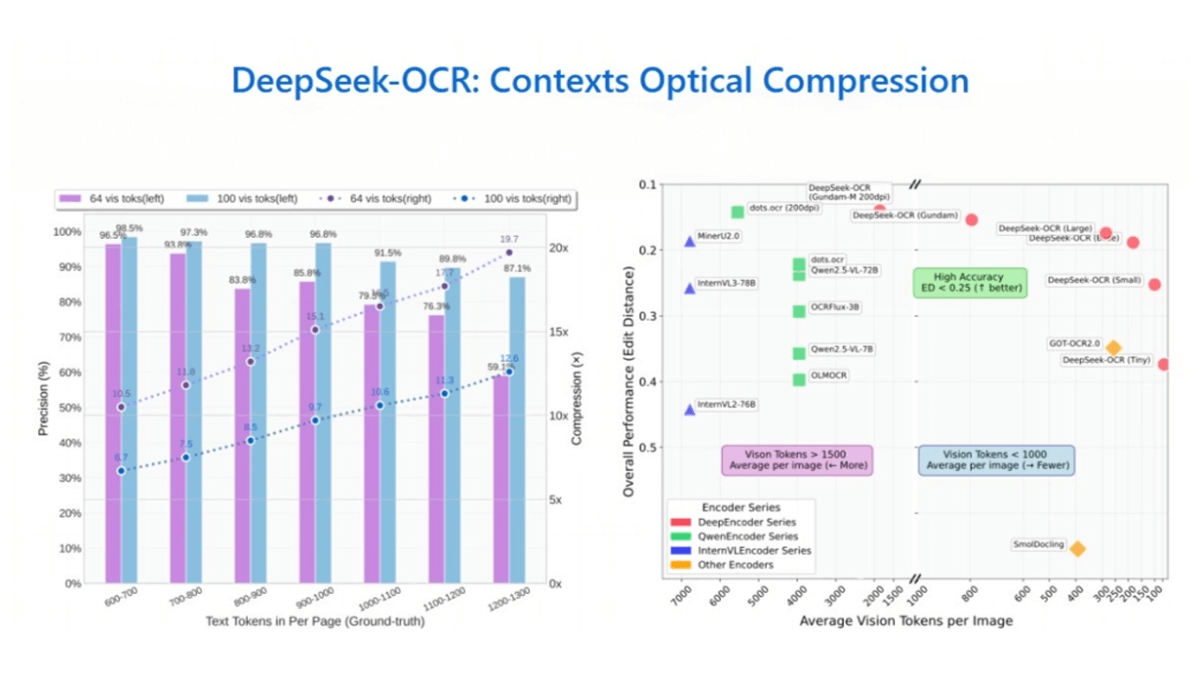
- Contextual Optical Compression: Convert text to image, compress and decode by visual token to realize efficient long text processing with accuracy up to 97% under 10x compression.
- Joint visual-verbal understanding: Combining visual information in images with the ability to understand language models to accurately grasp the semantics and layout structure of text.
- Multi-structure, multi-format supportIt supports a wide range of image formats (JPG, PNG, PDF) and multi-language recognition, and it can also cope well with handwriting, mixed text, and documents with a mixture of charts and text.
- High compression ratio and high accuracy: Under 10x compression, the OCR accuracy can reach 97%; even if the compression rate is increased to 20x, the model accuracy can still be maintained at around 60%.
- End-to-End VLM Architecture: DeepEncoder encoder and DeepSeek3B-MoE decoder are used, the encoder is responsible for extracting image features, tokenization, and compression of the visual representation, and the decoder generates the desired results based on image tokens and cues.
- Wide range of application scenariosThe document can be "photographed" with thousands of words into a single diagram, and 97% can be accurately restored at less than one-tenth of the cost, providing an efficient solution to the problem of long contexts in large language models; it can recognize information in text, charts and diagrams in tables or financial statements, and even read chemical molecular formulas, mathematical formulas and geometric shapes; it supports more than 100 languages, including Chinese and English; it supports local deployment, avoiding the need to send sensitive documents to third-party cloud services, even read chemical molecular formulas, mathematical formulas and geometric shapes; supports more than 100 languages, including Chinese and English; supports local deployment, which avoids sending sensitive documents to third-party cloud services.
- Significant performance advantagesThe single A100-40G graphics card can support more than 200,000 pages of large language model/visual language model training data generation per day; real-time recognition at 15 frames per second can be realized on mobile devices, with latency lower than 100 milliseconds; through the multi-scale dynamic feature fusion module and context-aware decoder, the model's recognition accuracy in complex scenes soars to 98.7%, 6.4 percentage points higher than the industry 6.4 percentage points higher than the industry average.
Core Benefits of DeepSeek-OCR
- Efficient Contextual Optical CompressionThe following is an example: By converting text into images and using visual tokens for compression and decoding, it achieves high compression ratio while maintaining high accuracy, with an accuracy of up to 97% under 10x compression, and around 60% under 20x compression, which effectively solves the problem of long text processing.
- A deep fusion of vision and language: Combining the visual information in the image (e.g., location, layout, graphics, table boundaries) and the comprehension of language models, it not only recognizes the textual content, but also accurately grasps the semantics and layout structure to enhance the processing of complex documents.
- Extensive format and language supportIt supports a wide range of image formats (JPG, PNG, PDF) and more than 100 languages, and can also cope well with handwriting, mixed text, charts and text, and is suitable for a wide range of scenarios.
- Powerful performanceA single A100-40G graphics card can support more than 200,000 pages of large language model training data generation per day; real-time recognition at 15 frames per second with a latency of less than 100 milliseconds on mobile devices; and a recognition accuracy of up to 98.71 TP3T in complex scenes, significantly better than the industry average.
- Flexible deploymentLocalized deployment is supported to avoid sending sensitive documents to third-party cloud services and to safeguard data security, as well as to meet the needs of different users for deployment environments.
What is the official DeepSeek-OCR website?
- GitHub repository:: https://github.com/deepseek-ai/DeepSeek-OCR
- HuggingFace Model Library:: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- Technical Papers:: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Who is DeepSeek-OCR for?
- business user: A large number of documents need to be processed, such as financial statements, contracts, technical documents, etc., which can be used to improve work efficiency and reduce labor costs based on efficient long text processing and complex document recognition capabilities.
- (scientific) researcherDeepSeek-OCR's multi-language support and accurate recognition capabilities can help in academic research, where complex content such as multilingual documents, charts and formulas often need to be handled.
- educator: It is used for the organization and digitization of teaching materials, such as courseware production and test paper analysis, etc. Its handwriting recognition and multi-format support functions can meet the needs of teaching.
- developer: The open source code and model weights facilitate developers to integrate into their own projects, develop customized OCR applications, and expand their application scenarios.
- individual userDeepSeek-OCR is a convenient and efficient solution for extracting document content, organizing notes, and translating foreign language materials to enhance personal office and study efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...