
注解:本文使用Dify v0.7.2版本。
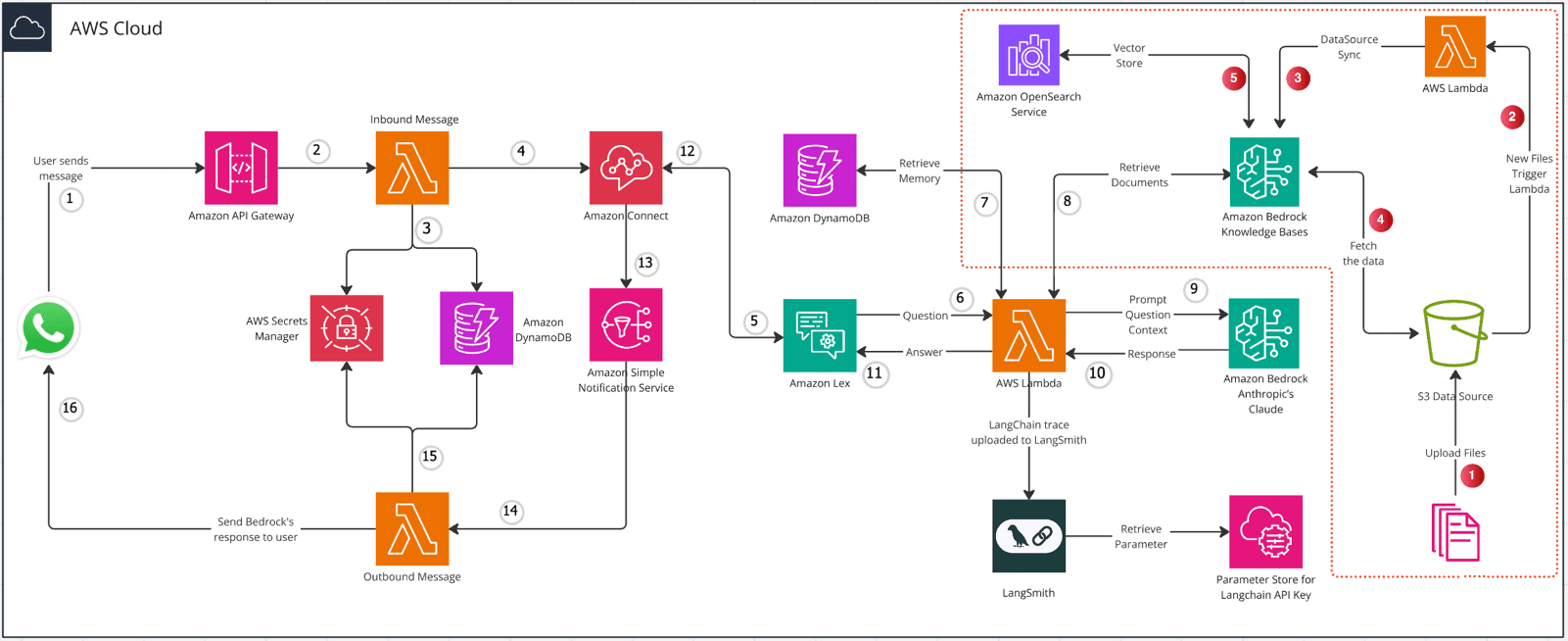
此聊天流程展示了如何构建一个用于门诊导诊的聊天机器人,可通过网页或语音对话来收集病人的数据。简单理解,即根据患者信息(年龄、性别和症状),给患者推荐科室。
一.工作流思路
1.工作流截图
门诊导诊完整工作流截图,如下所示:

2.工作流伪流程图
门诊导诊工作流的目的是根据患者输入的年龄、性别和症状,给患者推荐科室。在第1轮对话时,因为患者可能会一次性输入全部或者部分信息,因此采用"参数提取器"节点,从患者首次输入中提取性别、症状和年龄。并通过"变量赋值"节点将会话变量is_first_message设置为0。
3.存在问题1
在后续的轮次对话时,每次仅能识别1种字段信息,尽管患者可能提供多种字段,字段识别顺序为年龄、性别、症状。

4.存在问题2
如果根据患者信息已经推荐过科室,那么再次输入任何信息都会推荐上次的科室。因为department字段不空,走的直接回复流程。

二.会话变量
会话变量用于存储 LLM 需要的上下文信息,如用户偏好、对话历史等。它是可读写的。会话变量面向多轮对话场景,因此会话变量仅适用于 Chatflow 类型(聊天助手 -> 工作流编排)应用。
1.会话变量数据类型
(1)String 字符串
(2)Number 数值
(3)Object 对象
(4)Array[string] 字符串数组
(5)Array[number] 数值数组
(6)Array[object] 对象数组
2.会话变量特性
(1)会话变量可在大部分节点内全局引用;
(2)会话变量的写入需要使用变量赋值节点;
(3)会话变量为可读写变量。
3.本工作流定义的会话变量
本工作流定义的5个会话变量,分别为是否首轮对话、年龄、性别、症状和科室。

三.工作流相关接口
1.获取工作流的接口
(1)源码位置
- 源码位置:dify-0.7.2\api\controllers\console\app\workflow.py
- 源码位置:dify-0.7.2\api\services\workflow_service.py
(2)获取工作流操作
http://localhost:5001/console/api/apps/3c309371-54f6-4bfb-894a-4193b189ffa5/workflows/draft。其中,draft像草稿一样,表示在workflow页面中进行调试。

(3)获取工作流实现
工作流会在workflows数据表中存储一条记录。现在的version为draft,每发布一次工作流,就会在该表中插入一条记录。如下所示:

(4)Workflow数据结构
接口返回的Workflow数据结构,如下所示:
class Workflow(db.Model):
__tablename__ = 'workflows'
__table_args__ = (
db.PrimaryKeyConstraint('id', name='workflow_pkey'),
db.Index('workflow_version_idx', 'tenant_id', 'app_id', 'version'),
)
id: Mapped[str] = db.Column(StringUUID, server_default=db.text('uuid_generate_v4()'))
tenant_id: Mapped[str] = db.Column(StringUUID, nullable=False)
app_id: Mapped[str] = db.Column(StringUUID, nullable=False)
type: Mapped[str] = db.Column(db.String(255), nullable=False)
version: Mapped[str] = db.Column(db.String(255), nullable=False)
graph: Mapped[str] = db.Column(db.Text)
features: Mapped[str] = db.Column(db.Text)
created_by: Mapped[str] = db.Column(StringUUID, nullable=False)
created_at: Mapped[datetime] = db.Column(db.DateTime, nullable=False, server_default=db.text('CURRENT_TIMESTAMP(0)'))
updated_by: Mapped[str] = db.Column(StringUUID)
updated_at: Mapped[datetime] = db.Column(db.DateTime)
_environment_variables: Mapped[str] = db.Column('environment_variables', db.Text, nullable=False, server_default='{}')
_conversation_variables: Mapped[str] = db.Column('conversation_variables', db.Text, nullable=False, server_default='{}')
2.更新工作流的接口
(1)源码位置
- 源码位置:dify-0.7.2\web\app\components\workflow\hooks\use-nodes-sync-draft.ts
- 源码位置:dify-0.7.2\web\service\workflow.ts
(2)更新工作流操作
http://localhost:5001/console/api/apps/3c309371-54f6-4bfb-894a-4193b189ffa5/workflows/draft。

(3)更新工作流前端代码
由于Dify工作流前端使用的React Flow框架,推测可能是当workflow发生变化时进行POST操作,比如增删改等操作。通过后端Console中的日志发现调用了workflows/draft?_token=:

通过workflows/draft?_token=在前端代码中搜索仅发现了一个地方使用,那肯定就是这里了。

由于执行POST操作,肯定要有Payload参数吧,在该文件中发现了workflow参数。

当依赖项getPostParams发生变化时,会异步执行syncWorkflowDraft(postParams)。

而syncWorkflowDraft(postParams)实际调用为POST。如下所示:

(4)工作流函数总结
对dify-0.7.2\web\service\workflow.ts中的函数进行总结,如下所示:
| 序号 | 函数名称 | 函数功能 | 参数及解释 |
|---|---|---|---|
| 1 | fetchWorkflowDraft | 获取工作流草稿。 | url:字符串,请求的 URL。 |
| 2 | syncWorkflowDraft | 同步工作流草稿。 | url:字符串,请求的 URL。params:对象,请求的参数,包含 graph、features、environment_variables 和 conversation_variables。 |
| 3 | fetchNodesDefaultConfigs | 获取节点的默认配置。 | url:字符串,请求的 URL。 |
| 4 | fetchWorkflowRunHistory | 获取工作流运行历史。 | url:字符串,请求的 URL。 |
| 5 | fetcChatRunHistory | 获取聊天运行历史。 | url:字符串,请求的 URL。 |
| 6 | singleNodeRun | 运行单个节点。 | appId:字符串,应用的 ID。nodeId:字符串,节点的 ID。params:对象,请求的参数。 |
| 7 | getIterationSingleNodeRunUrl | 获取单个节点运行的迭代 URL。 | isChatFlow:布尔值,指示是否为聊天流。appId:字符串,应用的 ID。nodeId:字符串,节点的 ID。 |
| 8 | publishWorkflow | 发布工作流。 | url:字符串,请求的 URL。 |
| 9 | fetchPublishedWorkflow | 获取已发布的工作流。 | url:字符串,请求的 URL。 |
| 10 | stopWorkflowRun | 停止工作流运行。 | url:字符串,请求的 URL。 |
| 11 | fetchNodeDefault | 获取节点的默认配置。 | appId:字符串,应用的 ID。blockType:枚举值,节点的类型。query:对象,可选,查询参数。 |
| 12 | updateWorkflowDraftFromDSL | 从 DSL 更新工作流草稿。 | appId:字符串,应用的 ID。data:字符串,DSL 数据。 |
| 13 | fetchCurrentValueOfConversationVariable | 获取会话变量的当前值。 | url:字符串,请求的 URL。params:对象,请求的参数,包含 conversation_id。 |
3.工作流的执行
参考《Chatflow创建、更新、执行和删除操作的过程实现》中"Chatflow的执行"部分[6]。
4.工作流的发布
(1)源码位置
- 源码位置:dify-0.7.2\api\controllers\console\app\workflow.py
- 源码位置:dify-0.7.2\api\services\workflow_service.py
- 源码位置:dify-0.7.2\api\events\event_handlers\update_app_dataset_join_when_app_published_workflow_updated.py
(2)工作流发布接口
点击发布工作流时就会执行http://localhost:5001/console/api/apps/3c309371-54f6-4bfb-894a-4193b189ffa5/workflows/publish接口。

主要包括创建一个新的workflow,以及触发app workflow事件。如下所示:

(3)创建新的workflow记录
主要包括创建一条新的workflow记录,其中version字段内容为2024-09-07 09:11:25.894535。表示已经发布的workflow,而不是draft(workflow没有发布,还在workflow画布中调试)。如下所示:

(4)app_published_workflow_was_updated事件实现
@app_published_workflow_was_updated.connect
def handle(sender, **kwargs):
app = sender
published_workflow = kwargs.get("published_workflow")
published_workflow = cast(Workflow, published_workflow)
dataset_ids = get_dataset_ids_from_workflow(published_workflow) # 从工作流中获取数据集ID
app_dataset_joins = db.session.query(AppDatasetJoin).filter(AppDatasetJoin.app_id == app.id).all() # 获取应用数据集关联
removed_dataset_ids = [] # 用于存储移除的数据集ID
if not app_dataset_joins: # 如果没有应用数据集关联
added_dataset_ids = dataset_ids # 添加数据集ID
else: # 如果有应用数据集关联
old_dataset_ids = set() # 用于存储旧的数据集ID
for app_dataset_join in app_dataset_joins: # 遍历应用数据集关联
old_dataset_ids.add(app_dataset_join.dataset_id) # 添加数据集ID
added_dataset_ids = dataset_ids - old_dataset_ids # 添加数据集ID
removed_dataset_ids = old_dataset_ids - dataset_ids # 移除数据集ID
if removed_dataset_ids: # 如果有移除的数据集ID
for dataset_id in removed_dataset_ids: # 遍历移除的数据集ID
db.session.query(AppDatasetJoin).filter(
AppDatasetJoin.app_id == app.id, AppDatasetJoin.dataset_id == dataset_id
).delete() # 删除应用数据集关联
if added_dataset_ids: # 如果有添加的数据集ID
for dataset_id in added_dataset_ids: # 遍历添加的数据集ID
app_dataset_join = AppDatasetJoin(app_id=app.id, dataset_id=dataset_id) # 创建应用数据集关联
db.session.add(app_dataset_join) # 添加应用数据集关联
db.session.commit() # 提交事务
这段代码的功能是处理 app_published_workflow_was_updated 信号,当某个应用的已发布工作流更新时,更新应用与数据集的关联关系。具体步骤如下:
- 获取发送信号的应用对象
app和更新后的工作流对象published_workflow。 - 调用
get_dataset_ids_from_workflow函数,从更新后的工作流中提取数据集 ID 集合dataset_ids。 - 查询数据库,获取当前应用的所有
AppDatasetJoin记录。 - 计算需要添加和删除的数据集 ID:
- 如果当前没有任何
AppDatasetJoin记录,则所有提取的数据集 ID 都需要添加。 - 否则,计算需要添加和删除的数据集 ID。
- 如果当前没有任何
- 删除需要移除的
AppDatasetJoin记录。 - 添加新的
AppDatasetJoin记录。 - 提交数据库事务。
(5)AppDatasetJoin表的作用
AppDatasetJoin 表的作用是维护应用程序 (App) 和数据集 (Dataset) 之间的多对多关系。每条记录表示一个应用程序与一个数据集的关联。具体字段如下:
- id: 主键,唯一标识一条记录。
- app_id: 应用程序的唯一标识符。
- dataset_id: 数据集的唯一标识符。
- created_at: 记录创建的时间戳。
- 通过这个表,可以查询某个应用程序关联了哪些数据集,或者某个数据集被哪些应用程序关联。
(6)get_dataset_ids_from_workflow()实现
def get_dataset_ids_from_workflow(published_workflow: Workflow) -> set: # 从工作流中获取数据集ID
dataset_ids = set() # 用于存储数据集ID
graph = published_workflow.graph_dict # 获取工作流图
if not graph: # 如果没有图
return dataset_ids # 返回空集合
nodes = graph.get("nodes", []) # 获取图中的节点
# fetch all knowledge retrieval nodes # 获取所有知识检索节点
knowledge_retrieval_nodes = [
node for node in nodes if node.get("data", {}).get("type") == NodeType.KNOWLEDGE_RETRIEVAL.value
] # 获取所有知识检索节点
if not knowledge_retrieval_nodes: # 如果没有知识检索节点
return dataset_ids # 返回空集合
for node in knowledge_retrieval_nodes: # 遍历知识检索节点
try:
node_data = KnowledgeRetrievalNodeData(**node.get("data", {})) # 获取节点数据
dataset_ids.update(node_data.dataset_ids) # 更新数据集ID
except Exception as e: # 如果出现异常
continue
return dataset_ids
其中,get_dataset_ids_from_workflow 函数的主要功能是从给定的工作流对象中提取所有知识检索节点的相关数据集 ID。具体步骤如下:
- 初始化一个空的 dataset_ids 集合,用于存储数据集 ID。
- 获取工作流的图结构 graph。
- 如果图结构为空,返回空的 dataset_ids 集合。
- 获取图中的所有节点 nodes。
- 筛选出所有类型为 KNOWLEDGE_RETRIEVAL 的节点 knowledge_retrieval_nodes。
- 遍历这些知识检索节点,提取其数据集 ID 并更新到 dataset_ids 集合中。
- 返回包含所有提取的数据集 ID 的集合。
5.工作流其它接口
这部分接口不再阐述,工作流编排对话型应用API已经描述的非常清晰。
| 序号 | 接口名称 | 接口链接 | 接口功能解释 |
|---|---|---|---|
| 1 | 发送对话消息 | POST /chat-messages | 创建会话消息,发送用户输入或提问内容。 |
| 2 | 上传文件 | POST /files/upload | 上传文件(目前仅支持图片)以便在发送消息时使用。 |
| 3 | 停止响应 | POST /chat-messages/:task_id/stop | 停止流式响应(仅支持流式模式)。 |
| 4 | 消息反馈(点赞) | POST /messages/:message_id/feedbacks | 对消息进行用户反馈、点赞,方便优化输出结果。 |
| 5 | 获取下一轮建议问题列表 | GET /messages/{message_id}/suggested | 获取下一轮建议的问题列表。 |
| 6 | 获取会话历史消息 | GET /messages | 获取会话的历史消息记录。 |
| 7 | 获取会话列表 | GET /conversations | 获取当前用户的会话列表。 |
| 8 | 删除会话 | DELETE /conversations/:conversation_id | 删除指定的会话。 |
| 9 | 会话重命名 | POST /conversations/:conversation_id/name | 对会话进行重命名。 |
| 10 | 语音转文字 | POST /audio-to-text | 将语音文件转换为文字。 |
| 11 | 文字转语音 | POST /text-to-audio | 将文字转换为语音。 |
| 12 | 获取应用配置信息 | GET /parameters | 获取应用的配置信息,如功能开关、输入参数等。 |
| 13 | 获取应用Meta信息 | GET /meta | 获取应用的 Meta 信息,用于获取工具图标。 |
参考文献
[1] 会话变量:https://docs.dify.ai/v/zh-hans/guides/workflow/variables[2] 变量赋值:https://docs.dify.ai/v/zh-hans/guides/workflow/node/variable-assignment[3] 变量聚合:https://docs.dify.ai/v/zh-hans/guides/workflow/node/variable-assigner[4] React Flow中文网:https://reactflow-cn.js.org/[5] React Flow英文网:https://reactflow.dev/[6] Chatflow创建、更新、执行和删除操作的过程实现:https://z0yrmerhgi8.feishu.cn/wiki/FFzxwdF4PijlhjkLUoecOv6Vn8a© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...