

大语言模型(LLM)的发展日新月异,其推理能力已成为衡量其智能水平的关键指标。特别是具备长推理能力的模型,例如 OpenAI 的 o1、DeepSeek-R1、QwQ-32B 和 Kimi K1.5 等,它们通过模拟人类深度思考过程来解决复杂问题,引发了广泛关注。这种能力通常涉及到一种称为“推理时扩展”(Inference-Time Scaling)的技术,允许模型在生成答案的过程中,投入更多时间进行探索和修正。
然而,深入研究发现,这些模型在推理时常陷入两个极端:思考不足 (Underthinking) 和 过度思考 (Overthinking)。
思考不足 指的是模型在推理中频繁切换思路,难以集中于一个有前景的方向进行深入挖掘。模型输出中可能充斥着 “alternatively”、“but wait”、“let me reconsider” 等词语,如同下图所示,导致最终答案错误。这种现象可类比为人类注意力不集中,影响了推理的有效性。

过度思考 则表现为模型在简单问题上生成冗长而不必要的“思维链”。例如,对于 “2+3=?” 这样基础的算术题,某些模型可能耗费数百甚至上千 token 来反复验证或探索多种解法,如下图所示。虽然复杂的思维过程对难题有益,但在简单场景下,这无疑造成了计算资源的浪费。
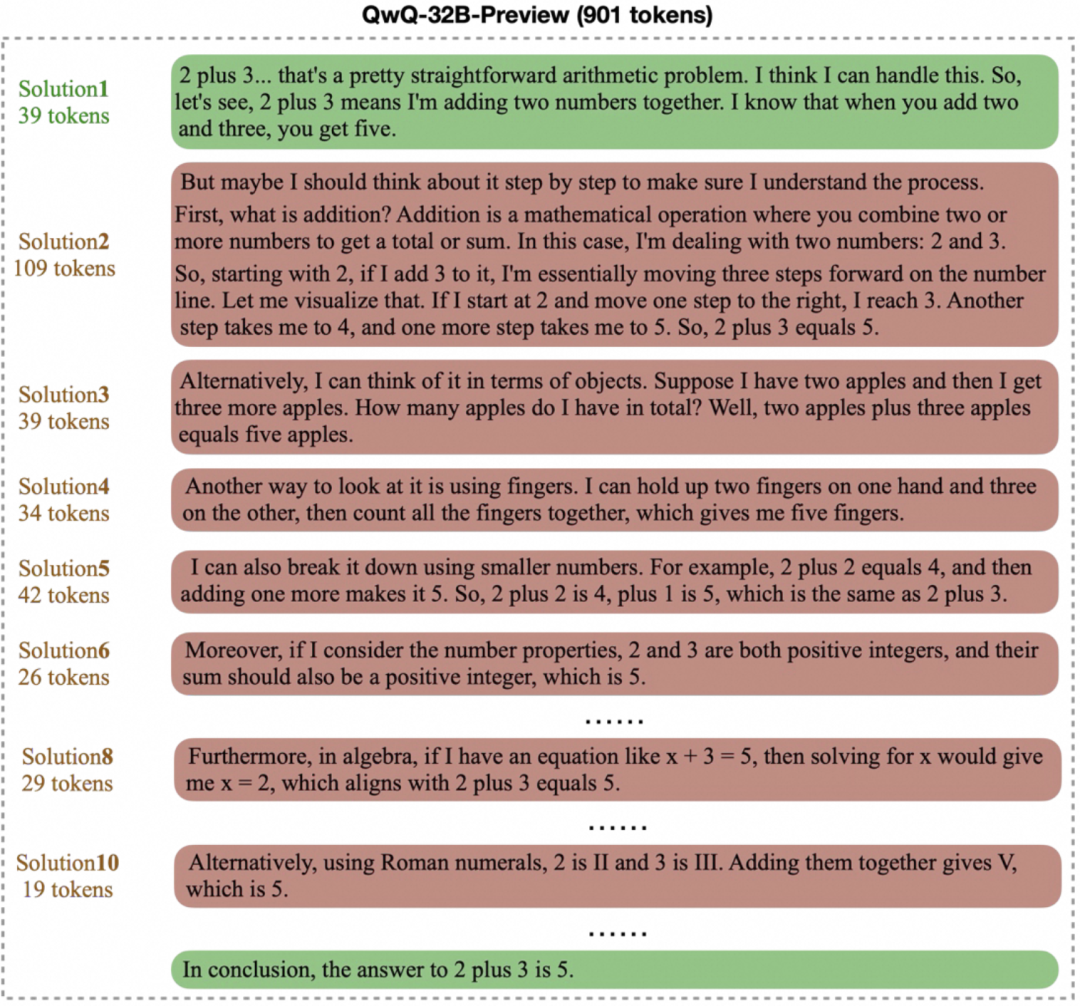
这两个问题共同指向了一个核心挑战:如何在保证答案质量的前提下,提升模型的思考效率?理想的模型应当能在最短的输出内,找到并给出正确答案。
为了应对这一挑战,EvalScope 项目引入了 EvalThink 组件,旨在提供一个标准化的工具来评估模型的思考效率。本文将以 MATH-500 数据集为例,分析包括 DeepSeek-R1-Distill-Qwen-7B 在内的一系列推理模型的表现,重点考察六个维度:模型推理 token 数、首次正确 token 数、剩余反思 token 数、token 效率、子思维链数量和准确率。
评估方法与流程
评估过程主要包含两个阶段:模型推理评估和模型思考效率评测。
模型推理评估
此阶段的目标是获取模型在 MATH-500 数据集上的原始推理结果和基础准确率。MATH-500 数据集包含 500 个不同难度的数学问题(从 Level 1 到 Level 5)。
准备评测环境
评估可通过接入兼容 OpenAI API 的推理服务进行。EvalScope 框架也支持使用 transformers 库在本地进行评测。对于需要处理长思维链(可能超过 10,000 token)的推理模型,使用 vLLM 或 ollama 等高效推理框架部署模型,可以显著加速评测过程。
以 DeepSeek-R1-Distill-Qwen-7B 为例,使用 vLLM 部署服务的示例命令如下:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
执行推理评测
通过 EvalScope 的 TaskConfig 配置模型 API 地址、名称、数据集、批处理大小和生成参数,然后运行评测任务。以下为示例 Python 代码:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
评测完成后,会输出模型在 MATH-500 各难度级别上的准确率(AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
模型思考效率评估
获取推理结果后,EvalThink 组件介入,进行更深入的效率分析。核心评估指标包括:
- 模型推理
token数 (Reasoning Tokens): 模型生成答案过程中,思考链(如 O1/R1 模型中</think>标志前的内容)所包含的token总量。 - 首次正确
token数 (First Correct Tokens): 从模型输出开始,到首次出现可识别正确答案位置的token数量。 - 剩余反思
token数 (Reflection Tokens): 从首次正确答案位置到思考链结束的token数量。这部分反映了模型找到答案后继续验证或探索所花费的代价。 - 子思维链数量 (Num Thought): 通过统计特定标志词(如
alternatively,but wait,let me reconsider)的出现次数来估算模型切换思路的频率。 token效率 (Token Efficiency): 衡量有效思考token占比的指标,计算公式为首次正确token数与总推理token数的比值的平均值(仅计入回答正确的样本):
Token Efficiency = 1⁄N ∑ First Correct Tokensi⁄Reasoning Tokensi
其中 N 为回答正确的问题数量。该值越高,表示模型的思考越“高效”。
为了确定“首次正确 token 数”,该评估框架借鉴了 ProcessBench 的思路,采用一个独立的“裁判”模型(Judge Model),例如 Qwen2.5-72B-Instruct,来检查推理步骤,定位最早出现正确答案的位置。实现方式涉及将模型输出按步骤分解(策略可选:按特定分隔符 separator、按关键词 keywords、或由 LLM 辅助重写并切分 llm),然后让裁判模型逐一判断。
执行思考效率评估的示例代码:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
评估结果会详细列出模型在各难度级别上的六个维度指标。
结果分析与讨论
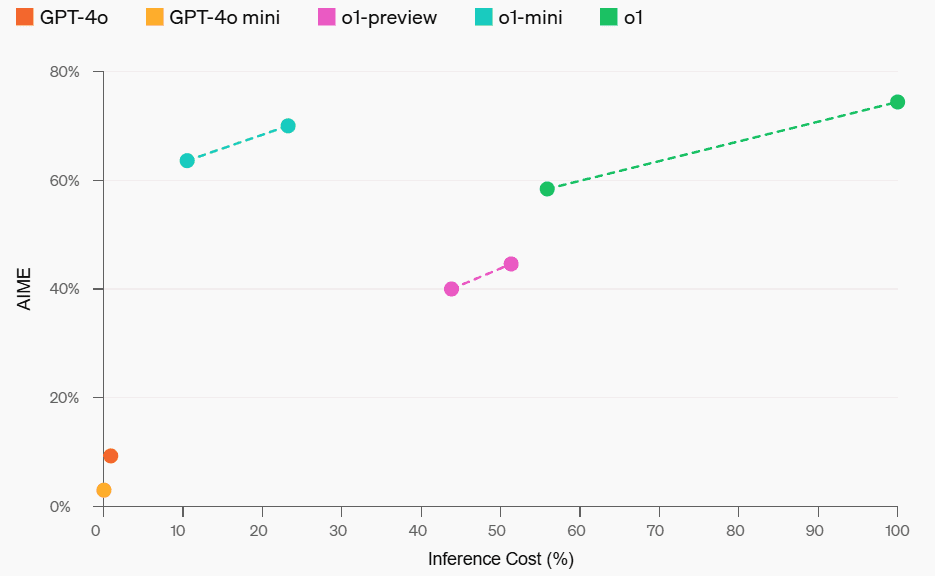
研究团队使用 EvalThink 对 DeepSeek-R1-Distill-Qwen-7B 及其他几个模型(QwQ-32B、QwQ-32B-Preview、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B)进行了评估,并加入了一个非推理的数学专用模型 Qwen2.5-Math-7B-Instruct 作为对比。
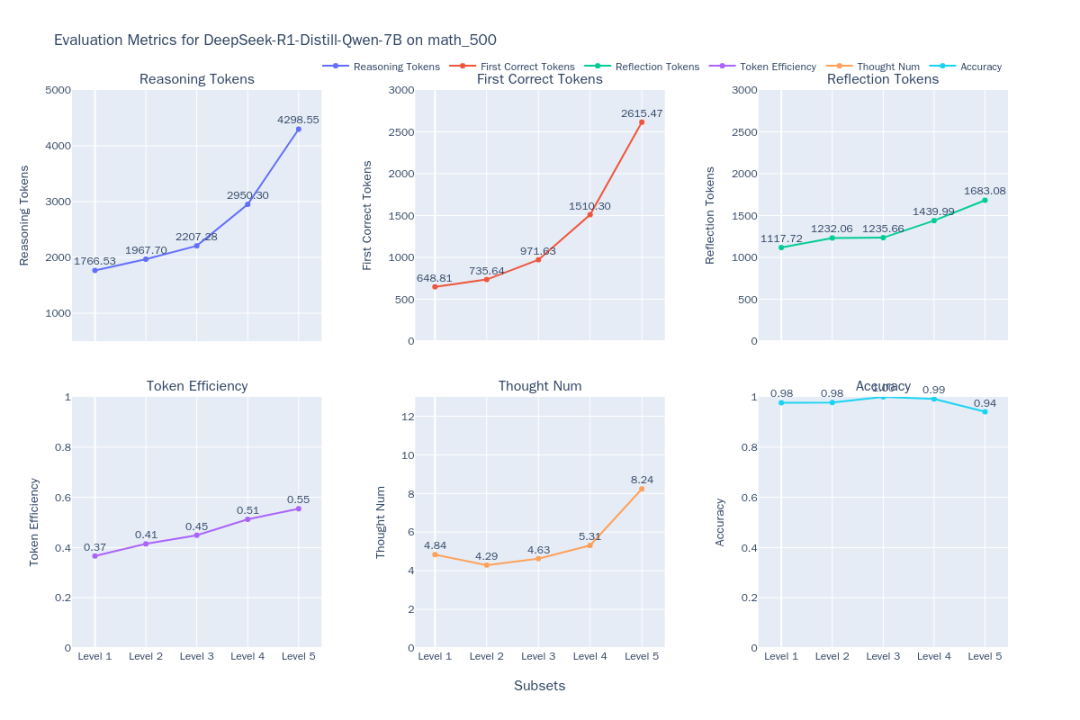
图1:DeepSeek-R1-Distill-Qwen-7B 思考效率指标
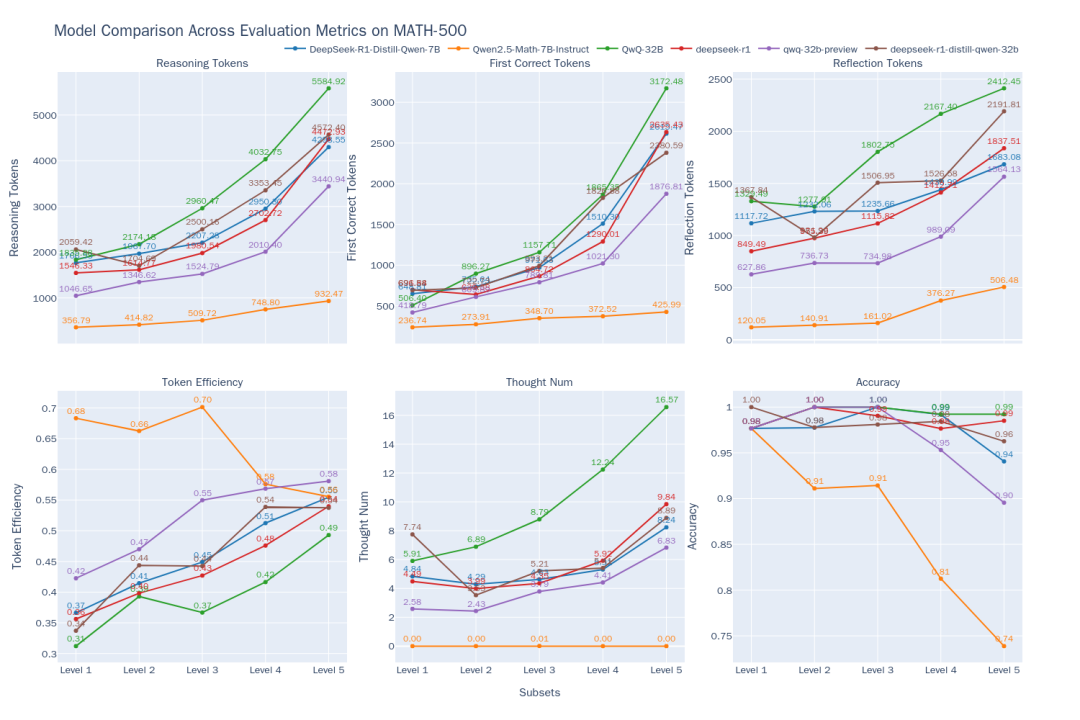
图2:6个模型在 MATH-500 不同难度级别上的思考效率对比
从对比结果(图2)中可以观察到以下趋势:
- 难度与表现关联: 随着问题难度(Level 1 到 Level 5)增加,大部分模型准确率下降。然而,
QwQ-32B和DeepSeek-R1在高难度问题上表现突出,QwQ-32B在 Level 5 准确率最高。同时,所有模型的输出token数都随难度增加而变长,这符合“推理时扩展”的预期——模型需要更多“思考”来解决难题。 - O1/R1 类推理模型特性:
- 效率提升: 有趣的是,对于
DeepSeek-R1和QwQ-32B这类推理模型,虽然输出变长,但token效率(有效token占比)也随难度提升(DeepSeek-R1从 36% 到 54%,QwQ-32B从 31% 到 49%)。这表明它们在难题上的额外思考更具“性价比”,而在简单问题上可能存在一定的“过度思考”,例如不必要的反复验证。QwQ-32B的token消耗量整体偏高,这或许是其能在 Level 5 保持高准确率的原因之一,但也暗示了其过度思考的倾向。 - 思维路径:
DeepSeek系列模型在 Level 1-4 的子思维链数量相对稳定,但在最难的 Level 5 急剧增加,表明 Level 5 对这些模型构成了显著挑战,需要多次尝试。相比之下,QwQ-32B系列模型的思维链数量增长更平滑,反映了不同的应对策略。
- 效率提升: 有趣的是,对于
- 非推理模型局限: 数学专用模型
Qwen2.5-Math-7B-Instruct在处理高难度问题时准确率大幅下降,且其输出token数远少于推理模型(约三分之一)。这显示,虽然这类模型在普通问题上可能更快、更省资源,但缺乏深度思考过程使其在复杂推理任务上存在明显的性能“天花板”。
方法学考量与局限性
在应用 EvalThink 进行评估时,需要注意以下几点:
- 指标定义:
- 本文提出的
token效率指标,借鉴了文献中关于“过度思考”和“思考不足”的概念,主要关注token数量,是对思考过程的一种简化度量,未能捕捉思考质量的全部细节。 - 子思维链数量的计算依赖于预定义的关键词,可能需要针对不同模型调整关键词列表才能准确反映其思考模式。
- 本文提出的
- 适用范围:
- 当前指标主要在数学推理数据集上验证,其在开放问答、创意生成等其他场景的有效性有待检验。
- 考虑到
DeepSeek-R1-Distill-Qwen-7B是基于数学模型蒸馏而来,其在MATH-500数据集上的表现可能存在天然优势。评估结果需结合模型背景进行解读。
- 裁判模型依赖:
token效率的计算依赖裁判模型(Judge Model)准确判断推理步骤的正确性。正如ProcessBench4研究所指出的,这对现有模型而言是一项挑战性任务,通常需要能力很强的模型才能胜任。- 裁判模型的误判会直接影响
token效率指标的准确性,因此选择合适的裁判模型至关重要。
总而言之,EvalThink 提供了一套量化评估 LLM 思考效率的框架和指标,揭示了不同模型在准确性、token 消耗和思考深度之间的权衡。这些发现对于指导模型训练(如 GRPO 和 SFT),开发出更高效、能根据问题难度自适应调整思考深度的下一代模型,具有重要的参考价值。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...