
综合介绍
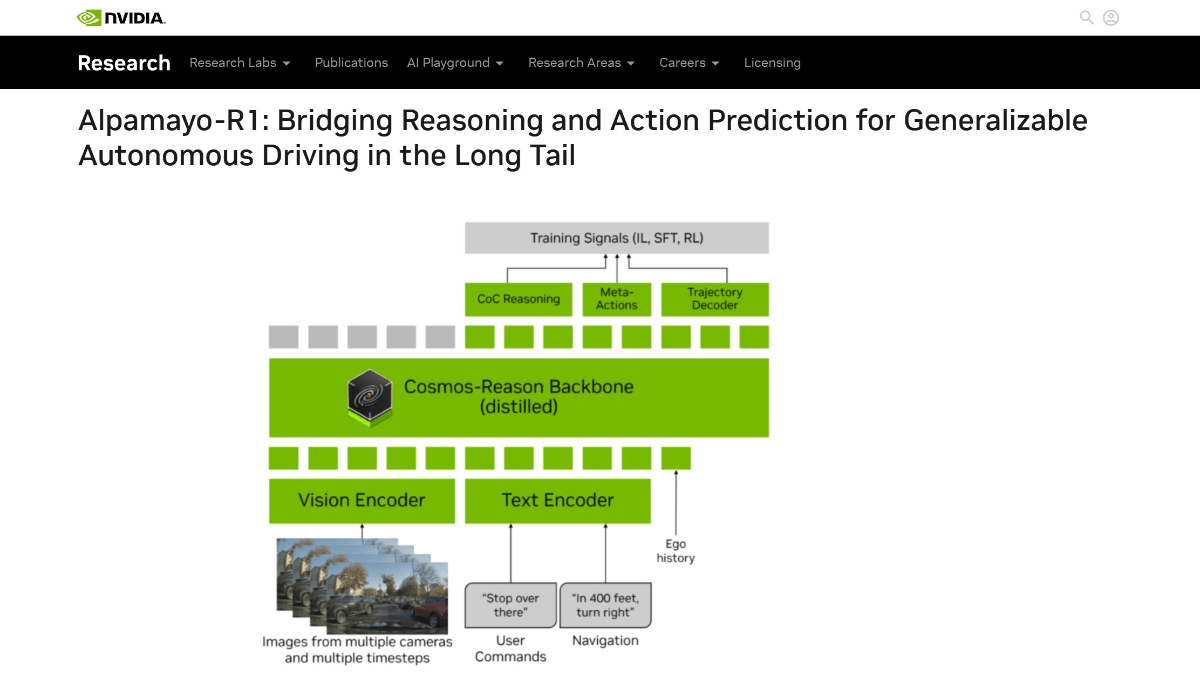
AudioX 是一个由 Zeyue Tian 等人在 GitHub 上开源的项目,官方论文发布于 arXiv(编号 2503.10522)。它基于扩散变换器(Diffusion Transformer)技术,能从文本、视频、图片、音频等多种输入生成高质量音频和音乐。AudioX 的独特之处在于,它不仅支持单一输入,还能统一处理多种模态数据,并通过自然语言控制生成结果。项目提供了两个数据集:vggsound-caps(19 万音频描述)和 V2M-caps(600 万音乐描述),解决了训练数据不足的问题。AudioX 开源了代码和预训练模型,适合开发者、研究者和创作者使用。

功能列表
- 支持多种输入生成音频:可以用文本、视频、图片或音频生成对应的音频或音乐。
- 自然语言控制:通过文字描述调整音频内容或风格,比如“轻快的钢琴曲”。
- 高质量输出:生成的音频和音乐音质高,接近专业水平。
- 多模态统一处理:能同时处理不同类型输入,生成一致的结果。
- 开源资源:提供完整代码、预训练模型和数据集,方便二次开发。
- 本地演示支持:通过 Gradio 提供交互式界面,方便测试功能。
使用帮助
AudioX 需要一定的编程基础,适合有 Python 经验的用户。以下是详细的安装和使用指南,帮助你快速上手。
安装流程
- 下载代码
在终端输入以下命令,克隆 AudioX 仓库:
git clone https://github.com/ZeyueT/AudioX.git
然后进入项目目录:
cd AudioX
- 创建环境
AudioX 需要 Python 3.8.20。使用 Conda 创建虚拟环境:
conda create -n AudioX python=3.8.20
激活环境:
conda activate AudioX
- 安装依赖
安装项目所需库:
pip install git+https://github.com/ZeyueT/AudioX.git
再安装音频处理工具:
conda install -c conda-forge ffmpeg libsndfile
- 下载预训练模型
创建模型文件夹:
mkdir -p model
下载模型和配置文件:
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/model.ckpt -O model/model.ckpt
wget https://huggingface.co/HKUSTAudio/AudioX/resolve/main/config.json -O model/config.json
- 验证安装
测试环境是否正常:
python -c "import audiox; print('AudioX installed successfully')"
如果没有报错,安装成功。
主要功能操作
AudioX 支持多种生成任务,包括文本转音频(T2A)、视频转音乐(V2M)等。以下是具体操作方法。
用文本生成音频
- 创建一个 Python 文件,比如
text_to_audio.py。 - 输入以下代码:
from audiox import AudioXModel
model = AudioXModel.load("model/model.ckpt", "model/config.json")
text = "敲击键盘的声音"
audio = model.generate(text=text)
audio.save("keyboard.wav")
- 运行脚本:
python text_to_audio.py
- 生成的音频保存为
keyboard.wav,可以用播放器检查效果。
用视频生成音乐
- 准备一个视频文件,比如
sample.mp4。 - 创建脚本
video_to_music.py,输入:
from audiox import AudioXModel
model = AudioXModel.load("model/model.ckpt", "model/config.json")
audio = model.generate(video="sample.mp4", text="为视频生成音乐")
audio.save("video_music.wav")
- 运行:
python video_to_music.py
- 生成的音乐保存为
video_music.wav。
运行 Gradio 本地演示
- 在终端输入:
python3 run_gradio.py --model-config model/config.json --share
- 命令运行后,会生成一个本地链接(比如 http://127.0.0.1:7860)。打开链接,就能通过网页界面测试 AudioX。
- 在界面上输入文本(如“钢琴和提琴的音乐”)或上传视频,点击生成即可听到结果。
脚本推理示例
官方提供了一个详细的推理脚本,用于更复杂的生成任务:
- 创建文件
generate.py,输入:
import torch
from stable_audio_tools import get_pretrained_model, generate_diffusion_cond
device `Truncated`torch.torch.torch.torch.torch.torch.torch.torch.torch_torch.torch.torch_torch.torch.torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model, config = get_pretrained_config("HKUSTAudio/AudioX")
model = model.to(device)
sample_rate = config["sample_rate"]
sample_size = config["sample_size"]
video_path = "sample.mp4"
text_prompt = "为视频生成钢琴音乐"
conditioning = [{"video_prompt": [read_video(video_path, 0, 10, config["video_fps"]).unsqueeze(0)],
"text_prompt": text_prompt,
"seconds_start": 0,
"seconds_total": 10}]
output = generate_diffusion_cond(model, steps=250, cfg_scale=7, conditioning=conditioning, sample_size=sample_size, device=device)
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)
- 运行:
python generate.py
- 生成的音频保存为
output.wav。
配置示例
以下是不同任务的输入配置:
- 文本转音频:
text="敲击键盘的声音",video=None - 视频转音乐:
video="sample.mp4",text="为视频生成音乐" - 混合输入:
video="sample.mp4",text="海浪声和笑声"
注意事项
- GPU 能显著提升生成速度,推荐使用。
- 视频格式需为 mp4,音频输出为 wav。
- 确保网络稳定,模型下载可能需要几分钟。
应用场景
- 音乐创作
输入文字描述,如“悲伤的小提琴曲”,快速生成音乐片段。 - 视频配乐
上传视频,生成匹配的背景音乐或音效。 - 研究开发
使用开源代码和数据集,改进音频生成技术。
QA
- 支持中文吗?
是的,支持中文输入,比如“轻快的钢琴曲”。 - 需要多少存储空间?
代码和模型约 2-3GB,完整数据集需额外几十GB。 - 生成时间多长?
GPU 上几秒到一分钟,CPU 可能需要几分钟。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...