

介绍
检索增强生成 (RAG) 是一种强大的技术,它将大型语言模型的优势与从知识库中检索相关信息的能力相结合。这种方法通过将生成的响应建立在特定的检索信息上来提高生成响应的质量和准确性。a 本笔记本旨在提供清晰简洁的 RAG 介绍,适合想要了解和实施这项技术的初学者。
RAG 流程
开始
Notebook
您可以运行此仓库中提供的 Notebook。https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
聊天应用程序
- 安装依赖项:
pip install -r requirements.txt - 运行应用程序:
python app.py - 动态导入数据:
python app.py --ingest --data_dir /path/to/documents
服务器
使用以下命令运行服务器:
python server.py
服务器提供两个端点:
/api/ingest/api/query
动机
传统语言模型根据训练数据中学到的模式生成文本。然而,当面对需要特定、更新或专业信息的查询时,它们可能难以提供准确的回复。RAG 通过引入检索步骤,向语言模型提供相关上下文,从而生成更准确的答案,解决了这一限制。
方法详情
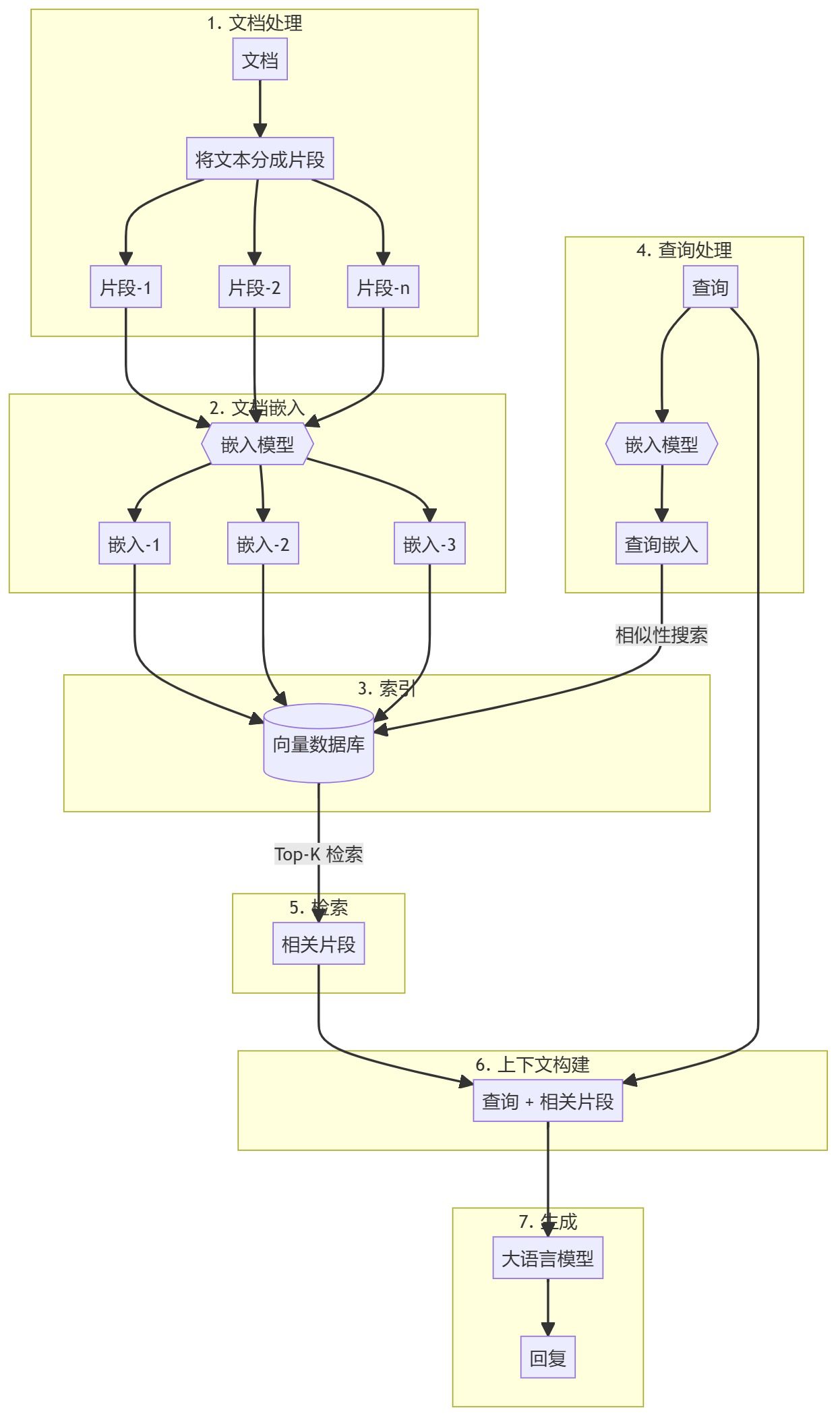
文档预处理和向量存储创建
- 文档分块: 将知识库文档(例如 PDF、文章)预处理并拆分为可管理的块。这样可以创建一个可搜索的语料库,用于高效检索过程。
- 生成嵌入: 使用预训练的嵌入(例如 OpenAI 的嵌入)将每个块转换为向量表示。这些文档随后被存储在向量数据库(如 Qdrant)中,以实现高效的相似性搜索。
检索增强生成 (RAG) 工作流
- 查询输入: 用户提供需要回答的查询。
- 检索步骤: 使用与文档相同的嵌入模型将查询嵌入为向量。然后在向量数据库中执行相似性搜索,以找到最相关的文档块。
- 生成步骤: 将检索到的文档块作为附加上下文传递给大语言模型(例如 GPT-4)。模型利用这些上下文生成更准确且相关的回复。
RAG 的关键特性
- 上下文相关性: 通过基于实际检索信息生成回复,RAG 模型可以生成更具上下文相关性和准确性的答案。
- 可扩展性: 检索步骤可以扩展以处理大型知识库,使模型能够从海量信息中提取内容。
- 用例灵活性: RAG 可以适配于各种应用场景,包括问答、摘要生成、推荐系统等。
- 准确性提高: 结合检索与生成的方式通常能产生更精确的结果,尤其是针对需要特定或冷门信息的查询。
此方法的优势
- 结合检索和生成的优点:RAG 有效融合了基于检索的方法与生成模型,既可以精确查找事实,又能进行自然语言生成。
- 增强对长尾查询的处理:对于需要特定且不常见信息的查询,该方法表现尤为出色。
- 领域适应性:检索机制可以针对特定领域进行调优,确保生成的回答基于最相关和准确的领域特定信息。
结论
检索增强生成(Retrieval-Augmented Generation,RAG)是一种将检索与生成技术创新融合的方式,通过将输出内容基于相关外部信息,有效增强语言模型的能力。这种方法在需要精准且具上下文意识的回答场景中(如客户支持、学术研究等)尤其有价值。随着 AI 的不断发展,RAG 在构建更可靠和上下文敏感的 AI 系统中脱颖而出,展现了其强大的潜力。
前置条件
- 优选 Python 3.11
- Jupyter Notebook 或 JupyterLab
- LLM API Key
- 可使用任意 LLM。在本 notebook 中,我们使用了 OpenAI 和 GPT-4o-mini。
通过这些步骤,您可以实现一个基础的 RAG 系统,结合真实世界的最新信息,提升语言模型在各种应用中的效率。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...