
ColBERT(基于 BERT 的上下文化后交互)与传统的密集嵌入模型有所不同。以下是 ColBERT 工作原理的简要说明:
- Token 层级嵌入:不同于直接为整个文档或查询创建单个向量,ColBERT 为每个 Token 创建嵌入向量。
- 后交互:计算查询和文档之间的相似性时,每个查询 Token 与每个文档 Token 进行比较,而不是直接比较整体向量。
- MaxSim 操作:对于每个查询 Token,ColBERT 找到其与文档中任何 Token 的最大相似性,并求和,最终得到相似性得分。
笔记:https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/10_ColBERT_RAG
接下来将通过图示详细展示 ColBERT 如何在 RAG 流程中工作,强调其 Token 层级处理和后交互机制。
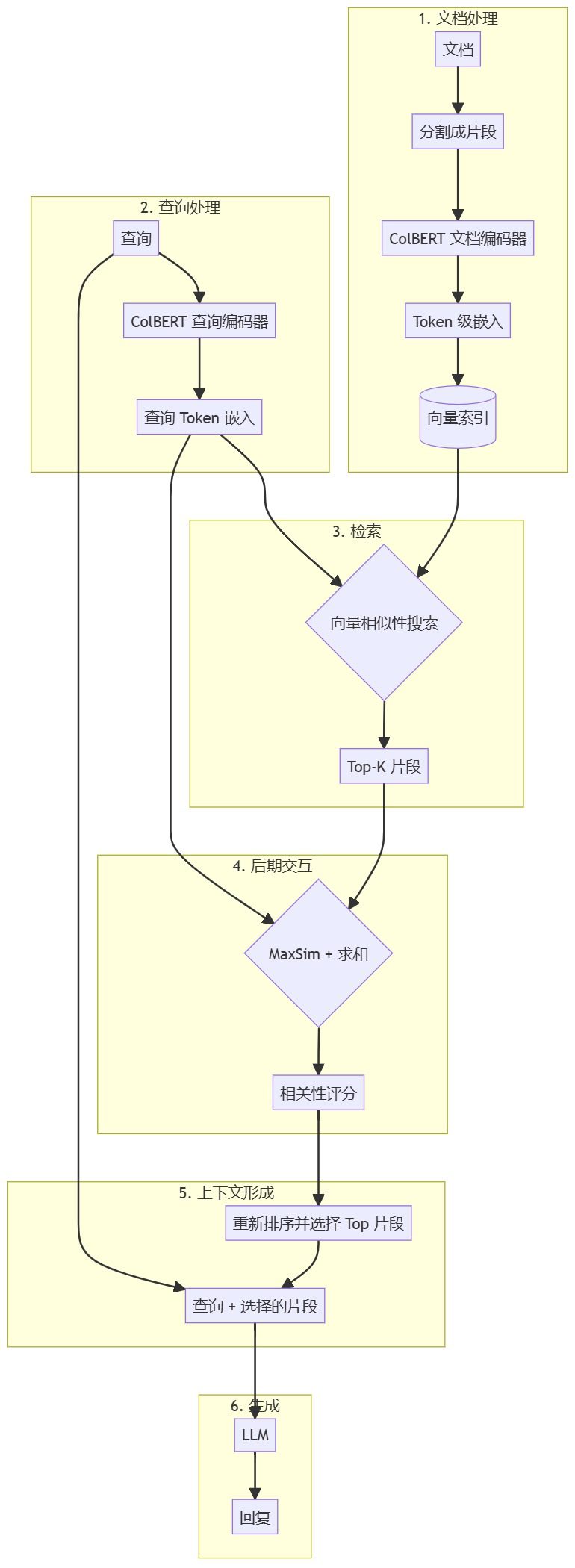
此图展示了基于 ColBERT 的 RAG 流水线的整体架构,强调了 ColBERT 方法中的 Token 级处理和后期交互。
现在,让我们创建一个更详细的图表,重点展示 ColBERT 的 Token 级嵌入和后期交互机制:

此图说明了:
- 文档和查询如何通过 BERT 和线性层处理为 Token 级嵌入。
- 在后期交互机制中,每个查询 Token 如何与每个文档 Token 进行比较。
- MaxSim 操作及其后续的求和步骤以生成最终的相关性评分。
这些图表更准确地展示了 ColBERT 在 RAG 流水线中的工作方式,突出了其 Token 级方法和后期交互机制。此方法使 ColBERT 能够从查询和文档中保留更细粒度的信息,从而实现更细致的匹配,相较于传统的稠密嵌入模型可能具有更优的检索性能。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...