

引言
RAPTOR(树结构化检索增强生成的递归摘要处理)是一种先进的检索增强生成(RAG)方法。它通过引入层级文档结构化和摘要技术,增强了传统的 RAG 流程。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/09_RAPTOR
动机
传统的 RAG 系统常常在处理大规模文档集合和复杂查询时遇到困难。RAPTOR 通过创建文档语料库的层级表示,解决这些挑战,从而实现更细致、更高效的检索。
方法细节
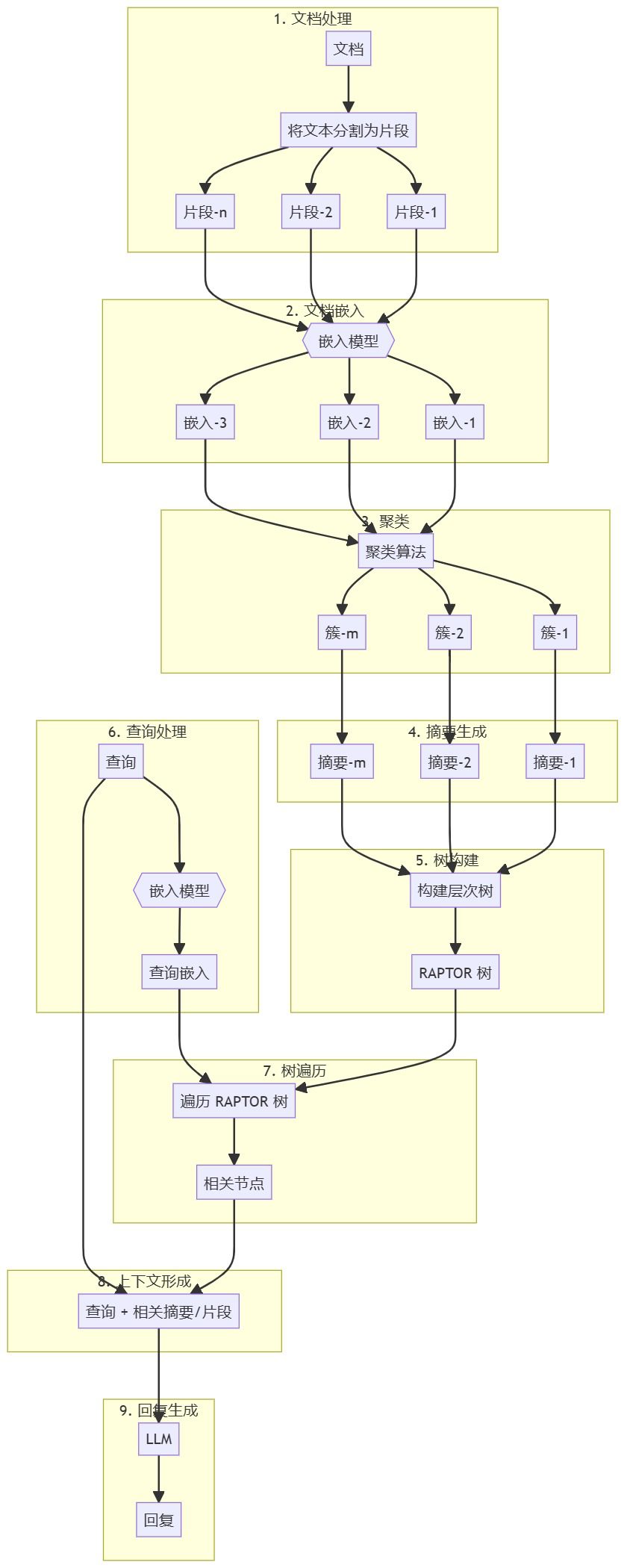
文档预处理和向量存储创建
- 将文档分成易于管理的小块。
- 使用合适的嵌入模型对每个小块进行嵌入。
- 对嵌入向量进行聚类,以分组相似内容。
- 对聚类结果进行摘要,创建更高层次的抽象表示。
- 使用这些摘要和原文块构建层级树结构(RAPTOR 树)。
检索增强生成工作流程
- 用户查询使用相同的嵌入模型进行嵌入。
- 遍历 RAPTOR 树以查找相关节点(摘要或文档块)。
- 将检索结果与用户原始查询合并,形成上下文。
- 将该上下文传递给大语言模型(LLM),生成最终的回复。
RAPTOR 的核心特性
- 层级文档表示:创建文档内容的树状结构。
- 多层次摘要:在不同层级提供摘要信息。
- 高效检索:通过树遍历实现更快、更相关的信息检索。
- 可扩展性:与平面向量存储相比,可更好地处理大规模文档集合。
本方法的优势
- 提高上下文相关性:层级结构更好地匹配查询与相关内容。
- 森林检索更高效:树遍历方式相比于全面搜索更为高效。
- 处理复杂查询:多层次结构有助于处理跨多个文档部分的信息查询。
- 可处理大规模文档集:相比传统方法,具备更好的可扩展性。
结论
RAPTOR 通过引入摘要和树结构化的文档表示与检索机制,增强了 RAG 流程的质量和效率。这种方法有望显著提高信息检索的准确性和上下文相关性,尤其适用于大规模复杂文档集合。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...