

简介
自动合并检索器是增强检索生成(RAG)框架的一种高级实现。该方法旨在通过将可能分散且较小的上下文合并成更大且更全面的上下文,从而增强 AI 生成响应的上下文感知能力和连贯性。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
背景动机
传统的增强检索生成系统通常难以在较大的上下文中保持连贯性,或者处理跨多个文本片段的信息时表现较差。自动合并检索器通过递归地合并引用超出特定阈值的父节点的子节点集合,解决了这一限制,从而在检索和生成过程中提供更全面、更具连贯性的上下文。
方法详情
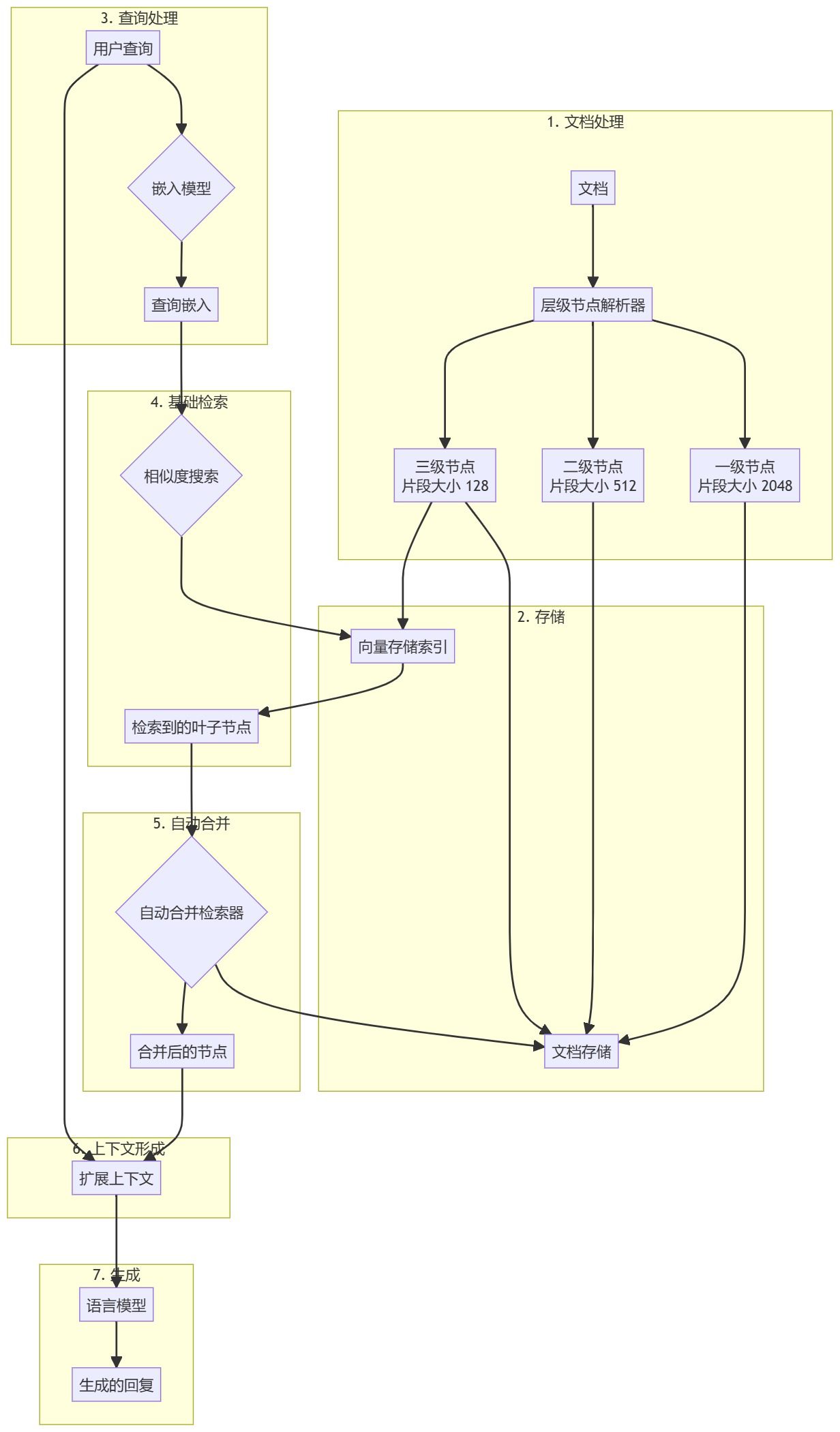
文档预处理与层级创建
- 文档加载:加载并处理输入文档(例如 PDF 文件)。
- 层级解析:使用
HierarchicalNodeParser从文档中创建节点层级:- 第一级:块大小 2048
- 第二级:块大小 512
- 第三级:块大小 128
- 节点存储:将所有节点存储到文档存储中,叶子节点也被索引到向量存储中。
增强检索生成工作流程
- 查询预处理:使用与文档块相同的嵌入模型处理用户查询。
- 基础检索:基础检索器进行初步相似性搜索,以找到相关的叶子节点。
- 自动合并:
AutoMergingRetriever会分析检索到的叶子节点集合,并递归地“合并”超出给定阈值的引用父节点的叶子节点子集。 - 上下文扩展:合并后的节点形成一个扩展的上下文,并与原始查询合并。
- 生成响应:将扩展上下文和查询输入到大语言模型(LLM)中生成响应。
自动合并检索器的关键特性
- 层级化文档表示:维护文档块的多级层级结构。
- 高效基础检索:利用向量相似性搜索实现快速、准确的初步信息检索。
- 动态上下文扩展:自动将相关文本块合并为更大且更具连贯性的上下文。
- 灵活的实现方式:可用于多种文档类型和语言模型。
本方法的优势
- 增强上下文连贯性:通过合并相关的文本块,为大语言模型提供更具连贯性且完整的上下文。
- 灵活的检索适应性:合并过程会根据查询和检索结果自动调整,提供与上下文相关的信息。
- 高效存储结构:在维持层级结构的同时,快速实现叶子节点的基础检索。
- 提升响应质量的可能性:扩展的上下文有望带来更准确、更详细的语言模型响应。
实验结果
实验结果显示,将自动合并检索器与基础检索器进行对比:
- 在正确性、相关性、准确性和语义相似性指标上表现相近。
- 在配对比较中,有 52.5% 的用户更偏好自动合并检索器的响应。
这些结果表明,自动合并检索器的表现与传统检索方法相当,甚至略有优势。
结论
自动合并检索器提供了一种先进的方法,可改善 RAG 系统中的检索过程。通过动态合并相关文本块为更大、更具连贯性的上下文,它解决了传统基于文本块的检索方法的某些局限性。虽然初步结果显示出积极前景,但进一步研究和优化有望显著提升响应质量和连贯性。
前提条件
要实现此系统,您需要:
- 一个能够生成文本的大语言模型(例如 GPT-3.5-turbo、GPT-4)。
- 一个嵌入模型,用于将文本块和查询转换为向量表示。
- 用于高效相似性搜索的向量数据库(例如 FAISS)。
- 一个文档存储,用于存储完整的节点层级结构。
- 提供
LlamaIndex库,它包含HierarchicalNodeParser和AutoMergingRetriever实现。 - 足够的计算资源,用于处理和存储大量文档集合。
- 熟悉 Python 编程语言,用于实现和测试。
使用示例
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...