

概述
本指南将引导您使用纯 Python 创建一个简单的检索增强生成 (RAG) 系统。我们将使用一个嵌入模型和一个大语言模型 (LLM) 来检索相关文档并基于用户的查询生成回复。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
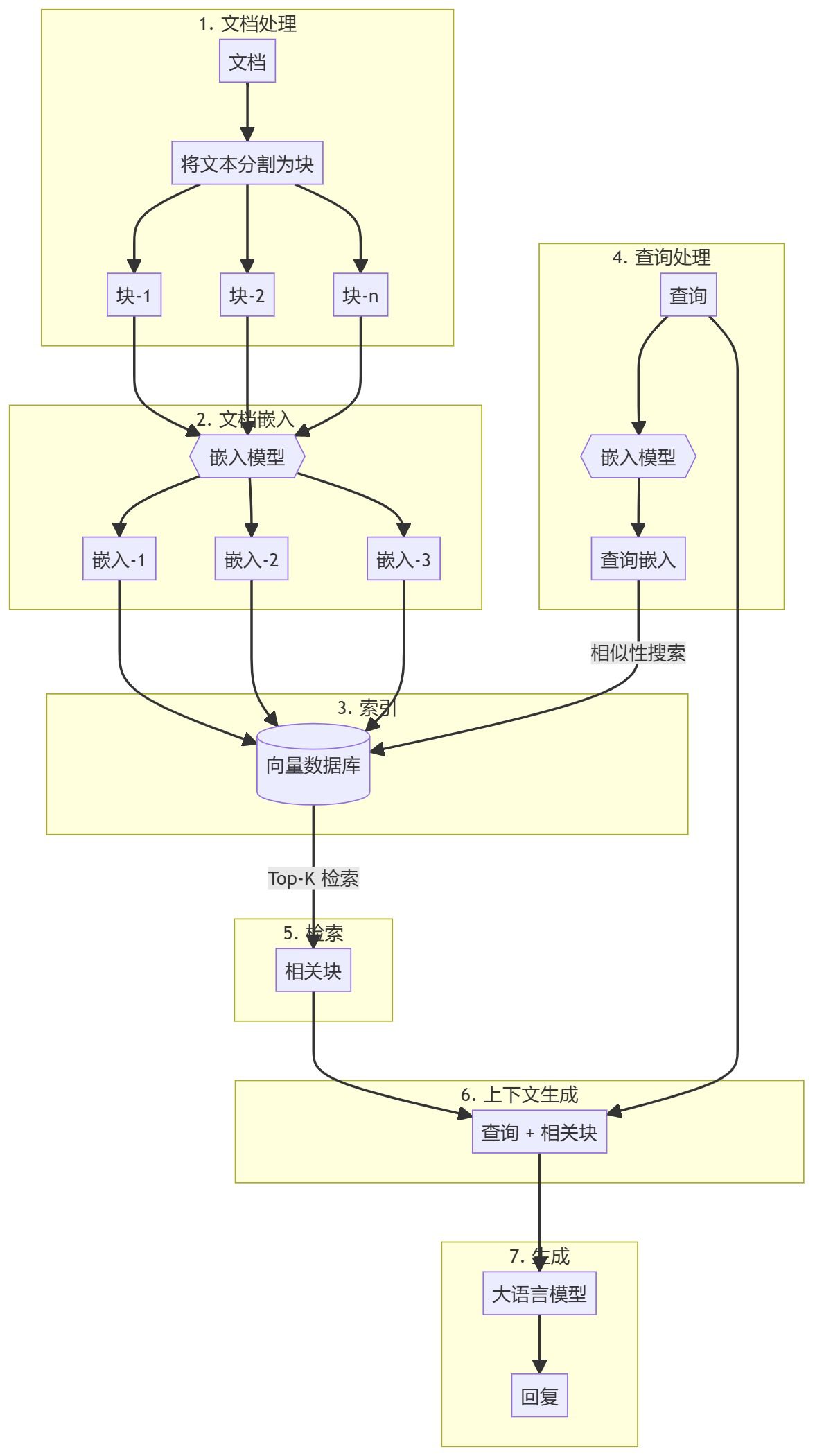
涉及的步骤
整个过程可以分为两个主要步骤:
- 知识库创建
- 生成部分
知识库创建
首先,您需要准备一个知识库(文档、PDF、维基页面)。这些是语言模型 (LLM) 的基础数据。具体过程包括:
- 分块:将文本分成小的子文档块以简化处理。
- 嵌入:为每个子文档块计算数值嵌入,以便理解查询的语义相似性。
- 存储:以能够快速检索的方式存储这些嵌入。虽然通常会使用向量存储/数据库,但本教程表明这并非必需。
生成部分
当用户查询输入时,为查询计算嵌入,并从知识库中检索最相关的子文档块。这些相关块会被附加到用户查询后,形成一个上下文并输入到 LLM 中生成回复。
1. 环境设置
在开始之前,需要安装一些包。
sentence-transformers:用于为文档和查询生成嵌入。numpy:用于相似性比较。scipy:用于高级相似性计算。wikipedia-api:用于将维基百科页面加载为知识库。textwrap:用于格式化输出文本。
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. 加载嵌入模型
让我们加载一个嵌入模型。本教程中使用的是 gte-base-en-v1.5。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
关于模型
gte-base-en-v1.5 模型是由阿里巴巴 NLP 团队提供的开源英语模型。它是 GTE(通用文本嵌入)系列的一部分,专为生成高质量嵌入而设计,适用于各种自然语言处理任务。该模型针对捕捉英语文本的语义意义进行了优化,可用于句子相似性、语义搜索和聚类等任务。trust_remote_code=True 参数允许使用与模型相关的自定义代码,确保其按预期运行。
3. 从维基百科获取文本内容并准备
- 首先加载一个维基百科文章作为知识库。文本将被分割为易于管理的小块(子文档),通常按段落分割。
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - 虽然有许多分块策略可用,但其中很多未必适用。最好检查您的知识库 (KB),确定最适合的策略。在本例中,我们按段落分块。
- 如果想查看这些块的样子,可以导入
textwrap库,并逐段打印出来。import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - 如果文档中包含图片和表格,建议单独提取并使用视觉模型嵌入。
4. 嵌入文档
- 接下来,通过调用模型的
encode方法,将文本数据(例如paragraphs)编码为嵌入。docs_embed = model.encode(paragraphs, normalize_embeddings=True) - 这些嵌入是文本的密集向量表示,捕捉了语义意义,使模型能够以数学形式理解和处理文本。
- 我们在此对嵌入进行了归一化。
- 什么是归一化? 归一化是一个调整嵌入值以使其具有单位范数的过程(即向量长度为 1)。
- 为什么归一化? 归一化的嵌入确保向量之间的距离主要反映方向上的差异,而不是大小上的差异。这可以提高模型在相似性搜索任务中的表现,在这些任务中需要比较文本之间的“接近程度”或“相似性”。
- 结果
docs_embed是一个文本数据的向量表示集合,其中每个向量对应paragraphs列表中的一个段落。 - 使用
shape命令可以查看块的数量和每个嵌入向量的维度(嵌入向量的大小取决于嵌入模型的类型)。docs_embed.shape - 您还可以查看实际嵌入的样子,这是一组归一化的数值。
docs_embed[0]
5. 嵌入查询
以与嵌入文档类似的方式嵌入示例用户查询。
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
您可以检查 query_embed 的形状以确认嵌入查询的维度。
query_embed.shape
6. 找到与查询最接近的段落
检索最相关的内容块最简单的方法之一是计算文档嵌入和查询嵌入的点积。
a. 计算点积
点积是一种数学运算,将两个向量(或矩阵)的对应元素相乘并求和。它通常用于衡量两个向量之间的相似性。
(注意,计算点积时取了 query_embed 向量的转置)。
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. 理解点积及其形状
NumPy 数组的 .shape 属性返回一个表示数组维度的元组。
similarities.shape
在此代码中的预期形状如下:
- 如果
docs_embed的形状为 (n_docs, n_dim):- n_docs 是文档数量。
- n_dim 是每个文档嵌入的维度。
query_embed.T的形状将为 (n_dim, 1),因为我们是针对单个查询进行比较。- 点积后的
similarities数组的形状将为 (n_docs,),表示这是一个 1 维数组(向量),包含 n_docs 个元素。每个元素代表查询与某个文档之间的相似度分数。 - 为什么检查形状? 确保形状为预期的 (n_docs,) 可以确认点积执行正确,并且每个文档的相似度分数已被正确计算。
您可以打印 similarities 数组以检查相似度分数,其中每个值对应一个点积结果:
print(similarities)
c. 点积的解释
两个向量(嵌入)之间的点积衡量其相似性:较高的值表示查询与文档之间的相似性较高。如果嵌入已归一化,这些值直接与向量之间的余弦相似度成正比。如果未归一化,它们仍然表示相似性,但也反映了嵌入的大小。
d. 找出最相似的 3 个文档
要根据相似度分数找出最相似的 3 个文档,可以使用以下代码:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarities, axis=0): 此函数按升序对
similarities数组的索引进行排序。例如,如果similarities = [0.1, 0.7, 0.4],np.argsort将返回[0, 2, 1],其中 0 是最小值的索引,1 是最大值的索引。 - [-3:]: 此切片操作选择相似度分数最高的 3 个索引(排序后的最后 3 个元素)。
- [::-1]: 此操作反转顺序,因此索引按相似度的降序排列。
- tolist(): 将索引数组转换为 Python 列表。结果:
top_3_idx包含最相似的 3 个文档的索引,按相似度降序排列。
e. 提取最相似的文档
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- 列表推导式: 此行创建一个名为
most_similar_documents的列表,其中包含paragraphs列表中对应于top_3_idx索引的实际段落。 - paragraphs[idx]: 对于
top_3_idx中的每个索引,此操作检索相应的段落。
f. 格式化并显示最相似的文档
CONTEXT 变量最初被初始化为空字符串,随后将在一个枚举循环中附加最相似文档的换行文本。
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. 生成一个回复
现在我们有了一个查询和相关内容块,它们将一起传递给大语言模型(LLM)。
a. 声明查询
query = "What was Studio Ghibli's first film?"
b. 创建一个提示
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. 设置 OpenAI
- 安装 OpenAI 以访问和使用大语言模型(LLM)。
!pip install -q openai - 启用对 OpenAI API 密钥的访问(可以在 Google Colab 的 secrets 中设置)。
from google.colab import userdata userdata.get('openai') import openai - 创建一个 OpenAI 客户端。
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. 调用 API 生成回复
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create: 此方法调用一个基于聊天的大语言模型创建新的回复(生成)。
- client: 表示连接到服务(此处为 OpenAI)的 API 客户端对象。
- chat.completions.create: 指定您正在请求创建基于聊天的生成。
关于传递给方法的参数的更多信息
- model="gpt-4o": 指定用于生成回复的模型。"gpt-4o" 是 GPT-4 模型的一个特定变体。不同的模型可能具有不同的行为、微调方式或能力,因此指定模型对于确保获得所需的输出非常重要。
- messages: 此参数是一个消息对象的列表,用于表示对话历史。这使模型能够理解聊天的上下文。在本例中,我们在列表中仅提供了一条消息:
{"role": "user", "content": prompt}。 - role: "user" 表示消息发送者的角色,即与模型交互的用户。
- content: 包含用户发送的消息的实际文本。变量 prompt 保存了此文本,模型将使用该文本作为输入来生成回复。
e. 关于接收到的回复
当您向类似 OpenAI GPT 模型的 API 发出请求以生成聊天回复时,响应通常以结构化格式返回,通常是一个字典。
这种结构通常包括:
- choices: 一个列表(数组),其中包含模型生成的多个可能的回复。此列表中的每个项目代表一个可能的回复或完成。
- message: 每个选择中的一个对象或字典,包含模型生成的消息的实际内容。
- content: 消息的文本内容,即模型生成的实际回复或完成。
f. 打印回复
print(response.choices[0].message.content)
我们选择 choices 列表中的第一个项目,然后访问其中的 message 对象。最后,我们访问 message 中的 content 字段,它包含模型生成的实际文本。
结论
至此,我们完成了从零开始构建 RAG 系统的讲解。强烈建议您首先使用纯 Python 构建初始 RAG 设置,以更好地理解这些系统的工作原理。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...