
zChunk: общая стратегия семантического чанкинга на основе Llama-70B

Общее введение
zChunk - это новая стратегия чанкинга, разработанная компанией ZeroEntropy для решения задачи семантического чанкинга общего назначения. Стратегия основана на модели Llama-70B, которая оптимизирует процесс разбиения документа на фрагменты, предлагая создать фрагмент, обеспечивая высокое соотношение сигнал/шум при поиске информации. zChunk особенно подходит для приложений RAG (Retrieval Augmentation Generation), требующих высокоточного поиска, и решает ограничения традиционных методов разбиения на фрагменты при работе со сложными документами. С помощью zChunk пользователи могут более эффективно сегментировать документы на значимые фрагменты, повышая тем самым точность и эффективность поиска информации.
Ваша задача - выступить в роли чанкера.
Вы должны вставить "абзац" по всему вводу.
Ваша цель - разделить контент на семантически релевантные группы.
методология и Ограничения LLM OCR: проблемы разбора документов под гламуром Упомянутые PROMPT имеют некоторые общие черты.

Список функций
- Алгоритм разбиения на части на основе Llama-70B: Генерирование подсказок для семантического расщепления с помощью модели Llama-70B.
- Рассечение с высоким соотношением сигнал/шум: Оптимизируйте стратегию разбивки на части, чтобы обеспечить высокое соотношение сигнал/шум в найденной информации.
- Несколько стратегий разбивки на части: Поддерживает различные стратегии, такие как разбиение на части с фиксированным размером, разбиение на части на основе сходства вкраплений и т. д.
- настройка гиперпараметров: Обеспечивает конвейер настройки гиперпараметров, пользователи могут регулировать размер куска и параметры перекрытия в соответствии с конкретными потребностями.
- открытый исходный код: Предоставляется полный открытый исходный код, который может свободно использоваться и модифицироваться пользователем.
Использование помощи
Процесс установки
- склад клонов::
git clone https://github.com/zeroentropy-ai/zchunk.git
cd zchunk
- Установка зависимостей::
pip install -r requirements.txt
Использование
- Подготовка входного файла: Сохраните документ, который нужно разбить на части, в виде текстового файла, например.
example_input.txt. - Запустите скрипт разбивки на части::
python test.py --input example_input.txt --output example_output.txt
- Просмотр выходного файла: Результаты разбивки будут сохранены в
example_output.txtСредний.
Подробный порядок работы функций
- Выбор стратегии разбивки на части::
- NaiveChunk: Куски фиксированного размера для простых документов.
- SemanticChunk: Распределение на основе сходства вкраплений для документов, которые должны сохранять семантическую целостность.
- Алгоритм zChunk: Генерируйте фрагменты на основе подсказок из модели Llama-70B для сложных документов.
- Настройка гиперпараметров::
- Размер куска: Это можно сделать с помощью настройки параметра
chunk_sizeчтобы задать размер каждого чанка. - коэффициент перекрытия: через параметр
overlap_ratioУстановите процент перекрытия между фрагментами, чтобы обеспечить непрерывность информации.
- Размер куска: Это можно сделать с помощью настройки параметра
- Запуск настройки гиперпараметров::
python hyperparameter_tuning.py --input example_input.txt --output tuned_output.txt
Сценарий автоматически настраивает размер кусков и коэффициент перекрытия на основе входного документа для получения оптимальных результатов разбиения на куски.
- Оценка эффектов разбивки на части::
- Оцените результаты разбивки на части, используя предоставленный сценарий оценки, чтобы убедиться в эффективности стратегии разбивки на части.
python evaluate.py --input example_input.txt --output example_output.txt
типичный пример
Предположим, у нас есть текст Конституции США, который необходимо разбить на фрагменты:
Оригинальный текст:
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.
Распределение по частям с помощью алгоритма zChunk:
- Выберите слова для подсказки: Выберите специальную лексему (например, "параграф"), которой нет в корпусе.
- Вставные сигналы: Пусть Llama вставит токен в сообщение пользователя.
SYSTEM_PROMPT (简化版):
你的任务是作为一个分块器。
你应该在输入中插入“段”标记。
你的目标是将内容分成语义相关的组。
- Создавайте фрагменты::
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.段
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.段
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.段
Таким образом, мы можем сегментировать документы на семантически связанные блоки, каждый из которых может быть извлечен независимо, что повышает соотношение сигнал/шум и точность поиска информации.
оптимизация
- С помощью локальных выводов Llama можно эффективно обрабатывать целые отрывки и исследовать логпробы для определения местоположения фрагментов.
- На обработку 450 000 символов уходит около 15 минут, но это время можно значительно сократить, если оптимизировать код.
бенчмаркинг
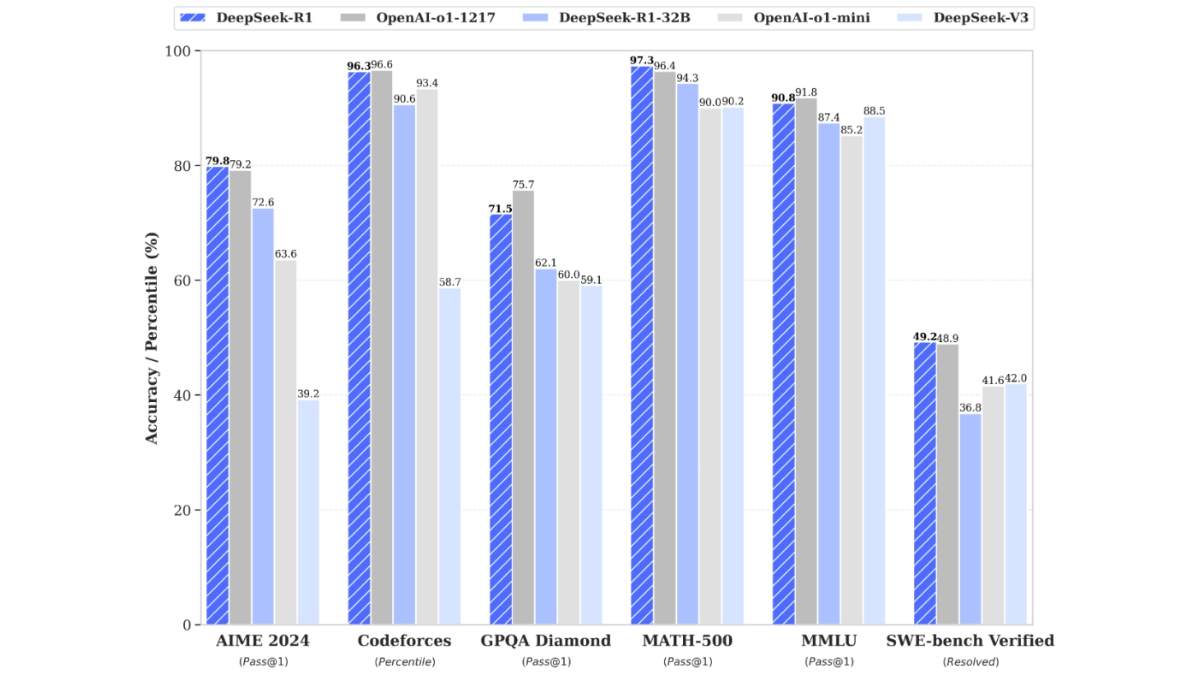
- zChunk имеет более высокие показатели коэффициента извлечения и коэффициента сигнала по сравнению с NaiveChunk и методами семантического чанкинга на наборе данных LegalBenchConsumerContractsQA.
С помощью алгоритма zChunk мы можем легко сегментировать документы любого типа, не прибегая к регулярным выражениям или правилам, созданным вручную, что повышает эффективность и точность приложений RAG.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...