Новая модель Microsoft: Phi-4 уже здесь, с параметрами 14B, сравнимыми с более масштабными моделями

Имея всего 14 миллиардов (14B) параметров, Phi-4 демонстрирует производительность, сравнимую или даже превосходящую некоторые более масштабные модели благодаря инновационным методам обучения и высококачественным данным. В этой статье мы подробно описываем архитектуру, особенности, методику обучения и производительность Phi-4 в реальных приложениях и бенчмарках.
https://github.com/xinyuwei-david/david-share.git
I. Изучение показателей для оценки потенциала

Измерьте три вопроса, сравнивая o1 и Phi-4
Первый вопрос:
фи-4

o1

Второй вопрос:
Фи-4.

o1:
Третий вопрос:
Фи-4

o1.
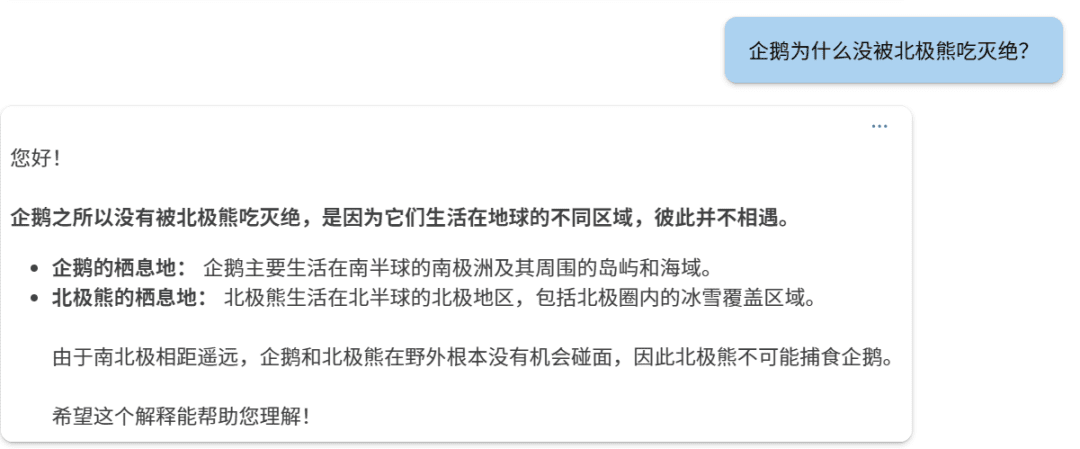
要求五个连续偶数的平均数,已知它们的和为90,下面我们逐步解答。步骤1:设未知数设这五个连续的偶数为:第一个偶数:( n - 4 )第二个偶数:( n - 2 )第三个偶数:( n )第四个偶数:( n + 2 )第五个偶数:( n + 4 )(因为偶数之间相差2,所以相邻的偶数可以这样表示)步骤2:列方程求和根据题目,五个数的和为90:[(n - 4) + (n - 2) + n + (n + 2) + (n + 4) = 90]步骤3:简化方程合并同类项:[5n = 90]步骤4:求解 n[n = frac{90}{5} = 18]步骤5:求出五个偶数第一个偶数:( 18 - 4 = 14 )第二个偶数:( 18 - 2 = 16 )第三个偶数:( 18 )第四个偶数:( 18 + 2 = 20 )第五个偶数:( 18 + 4 = 22 )步骤6:计算平均数平均数等于总和除以数量:[text{平均数} = frac{14 + 16 + 18 + 20 + 22}{5} = frac{90}{5} = 18]答案:这五个连续的偶数的平均数是 18。
Если посмотреть на это с другой стороны, то рассуждения Фи-4 остаются в порядке.
II. Фи-4 архитектура модели
1. Архитектура декодера на основе трансформатора
В Phi-4 используется система, основанная на Трансформатор (используется в форме номинального выражения) Только декодер Эта архитектура похожа на семейство моделей GPT. Эта архитектура использует механизм самовнушения для эффективного отражения долгосрочных зависимостей в текстовых последовательностях и демонстрирует превосходство в задачах генерации естественного языка.
2. размер параметров и количество слоев
- Общее количество параметров: 14 миллиардов (14B) Параметры.
- Количество этажей модели: 40
3. длина контекста
- Начальная длина контекста: 4,096 Жетон.
- Среднесрочное продление обучения: В середине этапа обучения длина контекста Phi-4 была увеличена до 16,000 Token (16K), что улучшает способность модели обрабатывать длинные тексты.
4. Глоссарий и лексер
- Разделители: Использование OpenAI Разделитель тиктоновКомпания поддерживает мультиязычность и обладает лучшим эффектом разделения слов.
- Размер глоссария: 100,352Сюда входят некоторые зарезервированные неиспользуемые Token.
III. Механизмы внимания и кодирование местоположения
1. Глобальные механизмы внимания
Фи-4 использует Механизм полного вниманият.е. самовнимание вычисляется для всей последовательности контекстов. Это отличается от модели-предшественницы, Phi-3-medium, которая использует 2 048 Токен скользящего окна, в то время как Phi-4 выполняет вычисление глобального внимания непосредственно на контекстах 4 096 Token (начальный) и 16 000 Token (расширенный), улучшая способность модели улавливать дальние зависимости.
2. Поворотное позиционное кодирование (RoPE)
Для того чтобы поддерживать более длинные контексты, в середине обучения Фи-4 был адаптирован для Встраивание в поворотное положение (RoPE) базовой частоты:
- Регулировка базовой частоты: Увеличьте базовую частоту RoPE до 250,000чтобы учесть длину контекста 16K.
- Роль: RoPE помогает модели сохранять эффективность позиционного кодирования в длинных последовательностях, что позволяет ей сохранять хорошую производительность при работе с длинными текстами.
IV. Стратегии и методы обучения
1. концепция приоритетности качества данных
Стратегия обучения для Phi-4 основана на Качество данных в ядро. В отличие от других моделей, которые предварительно обучаются, используя в основном органические данные из Интернета (например, веб-контент, код и т. д.), Phi-4 стратегически внедряет в процесс обучения Синтетические данные.
2. Создание и применение синтетических данных
Синтетические данные сыграл ключевую роль в предварительном и среднем обучении Phi-4:
- Многочисленные методы получения данных:
- Многоагентная подсказка: Разнообразие данных обогащается за счет использования нескольких языковых моделей или агентов для совместной генерации данных.
- Рабочие процессы саморевизии: После того как модель генерирует исходный результат, она проводит самооценку и коррекцию, чтобы итеративно улучшить качество результата.
- Инструкция "Обратный ход": Генерирование соответствующих входных инструкций на основе существующих выходных данных повышает способность модели понимать и генерировать инструкции.
- Преимущества синтетических данных:
- Структурированное и прогрессивное обучение: Синтетические данные позволяют точно контролировать сложность и содержание, постепенно направляя модель на обучение сложным рассуждениям и навыкам решения проблем.
- Повышение эффективности обучения: Генерация синтетических данных может обеспечить целевое обучение для выявления слабых мест модели.
- Избегайте загрязнения данных: Поскольку синтетические данные генерируются, риск того, что обучающие данные будут содержать содержимое набора обзоров, исключен.
3. Тонкий отбор и фильтрация органических данных
Помимо синтетических данных, Phi-4 уделяет особое внимание тщательному отбору и фильтрации высококачественных данных из различных источников Органические данные::
- Источники данных: Включает в себя веб-контент, книги, библиотеки кодов, научные статьи и многое другое.
- Фильтрация данных:
- Удалите некачественный контент: Используйте автоматические и ручные методы для отсеивания бессмысленного, неправильного, дублирующего или вредного контента.
- Предотвратите загрязнение данных: Гибридный алгоритм n-грамм (13-грамм и 7-грамм) использовался для дедупликации и деконтаминации, чтобы гарантировать, что обучающие данные не содержат контента из набора рецензий.
4. стратегия смешивания данных
Phi-4 был оптимизирован в составе обучающих данных со следующими соотношениями:
- Синтетические данные: завладеть 40%.
- Веб-рерайт: завладеть 15%В случае нового обучающего образца он переписывается из высококачественного веб-контента для создания нового обучающего образца.
- Данные об органическом интернете: завладеть 15%Веб-контент представляет собой подборку ценных материалов.
- Кодовые данные: завладеть 20%включая общедоступную кодовую базу и сгенерированные данные синтеза кода.
- Целевые приобретения: завладеть 10%В том числе научные статьи, профессиональные книги и другой ценный контент.
5. многоступенчатый процесс обучения
Предтренировочный этап:
- Цель: Моделирование базового лингвистического понимания и генеративных навыков.
- Объем данных: договориться о встрече 10 триллионов (10T) Жетон.
Среднесрочная фаза обучения:
- Цель: Увеличение длины контекста для улучшения обработки длинных текстов.
- Объем данных: 250 миллиардов (250B) Жетон.
Посттренировочный этап (тонкая настройка):
- Supervised Fine Tuning (SFT): Тонкая настройка с использованием высококачественных многодоменных данных улучшает способность модели следовать инструкциям и качество ответов.
- Прямая оптимизация предпочтений (DPO): использовать Pivotal Token Search (PTS) и другие методы для дальнейшей оптимизации результатов моделирования.
V. Инновационные методы обучения
1. Pivotal Token Search (PTS)
Методология ПТС это главная инновация в процессе обучения Phi-4:
- Принцип: Определяя ключевые токены, которые оказывают значительное влияние на правильность ответа в процессе генерации, модель нацелена на оптимизацию предсказания по этим токенам.
- Преимущество:
- Повышение эффективности обучения: Сосредоточение оптимизации на тех частях, которые оказывают наибольшее влияние на результаты, вдвое эффективнее.
- Улучшенная производительность модели: Помогает модели делать правильный выбор в ключевых точках принятия решений и повышает общее качество результатов.
2. Улучшенная оптимизация прямых предпочтений (DPO)
- Метод DPO: Оптимизация выполняется непосредственно с использованием данных о предпочтениях, чтобы сделать вывод модели более соответствующим предпочтениям человека.
- Инновационные очки:
- В сочетании с PTS: Внедрение в DPO пар обучающих данных, сгенерированных PTS, улучшает оптимизацию.
- Оценка показателей: Более точное измерение оптимизации путем оценки эффективности модели по ключевым показателям Token.
VI. Особенности и преимущества модели
1. отличная производительность
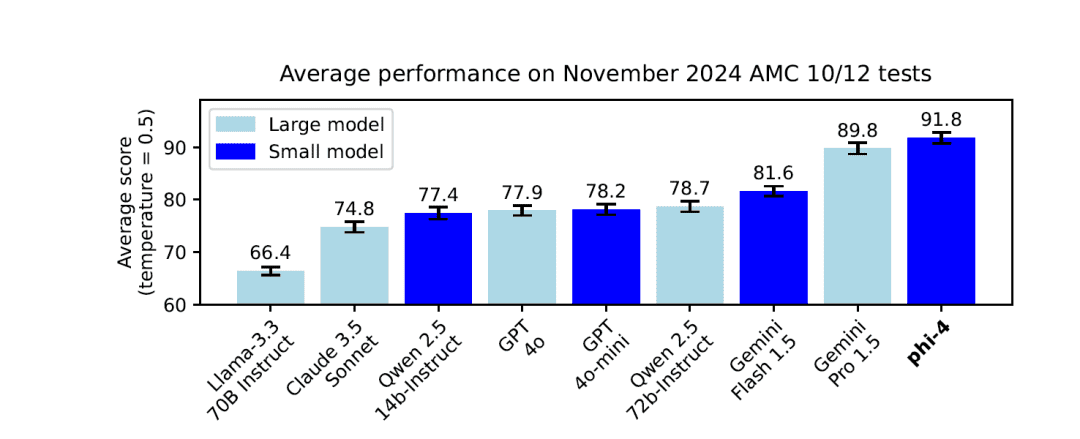
- Маленькие модели, большие возможности: Хотя шкала параметров составляет всего 14BТем не менее, Phi-4 демонстрирует хорошие результаты в нескольких обзорных бенчмарках, особенно в задачах на рассуждение и решение проблем.
2. Отличные навыки рассуждения
- Решение задач по математике и естественным наукам: существовать GPQA, иMATH В эталонных тестах, таких как этот, Phi-4 показывает даже лучшие результаты, чем его модель для учителей. GPT-4o.
3. возможности длительной обработки контекста
- Увеличение длины контекста: Увеличив длину контекста в середине обучения до 16,000 Токен, Phi-4 способен более эффективно обрабатывать длинные тексты и зависимости на больших расстояниях.
4. Многоязычная поддержка
- Охват нескольких языков: Обучающие данные состояли из Немецкий, испанский, французский, португальский, итальянский, хинди, японский и многие другие языки.
- Кросс-лингвистическая компетенция: Отлично справляется с такими задачами, как перевод и межъязыковые тесты.
5. безопасность и соответствие
- Принципы ответственного искусственного интеллекта: В процессе разработки строго соблюдаются Принципы ответственного искусственного интеллекта Microsoft, в которых основное внимание уделяется безопасности и этичности модели.
- Обеззараживание данных и защита конфиденциальности: Строгие стратегии дедупликации и фильтрации данных используются для предотвращения попадания конфиденциального контента в обучающие данные.
VII. Контрольные показатели и производительность
1. внешний бенчмаркинг
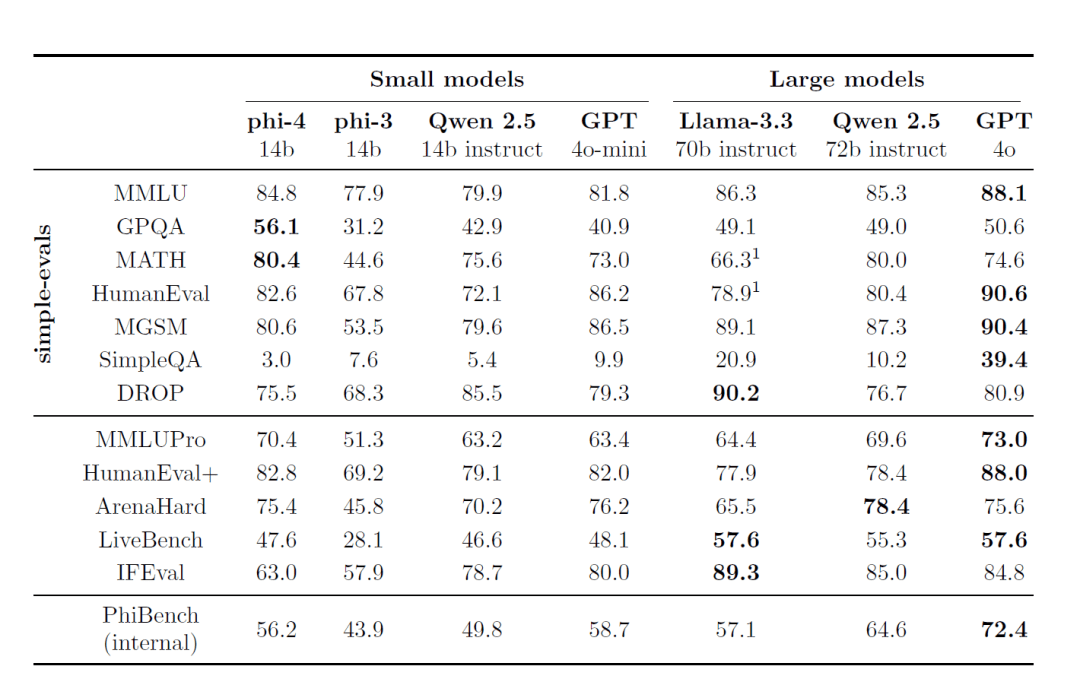
Phi-4 демонстрирует лучшие показатели по нескольким общедоступным контрольным показателям:
- MMLU (Multitasking Language Understanding): Достиг отличных результатов в сложных многозадачных тестах на понимание.
- GPQA (Graduate level STEM quiz): отлично справился с непростой STEM-викториной, набрав больше баллов, чем некоторые масштабные модели.
- MATH (математический конкурс): При решении математических задач Фи-4 демонстрирует сильные способности к рассуждениям и вычислениям.
- HumanEval / HumanEval+ (генерация кода): В задачах генерации и понимания кода Phi-4 превосходит модели своего размера и даже приближается к более крупным моделям.
2. Набор для внутренней оценки (PhiBench)
Чтобы получить представление о возможностях и недостатках модели, команда разработала специальный набор для внутренней оценки PhiBench::
- Задача диверсификации: Включает отладку кода, завершение кода, математические рассуждения и выявление ошибок.
- Руководство по оптимизации моделей: Проанализировав результаты PhiBench, команда смогла наметить пути улучшения модели.
VIII. Безопасность и ответственность
1. стратегия строгого соблюдения безопасности
Разработка Phi-4 последовала за проектом Microsoft Принципы ответственного искусственного интеллектаПри этом основное внимание уделяется безопасности и этике модели во время обучения и тонкой настройки:
- Защита от вредного содержимого: Уменьшите вероятность того, что модель сгенерирует неподходящий контент, включив данные о тонкой настройке безопасности на этапе после обучения.
- Тестирование "красной команды" и автоматизированная оценка: Было проведено обширное тестирование "красной команды" и автоматизированная оценка безопасности, охватывающая десятки категорий потенциальных рисков.
2. обеззараживание данных и предотвращение перебора
- Усовершенствованные стратегии обезвреживания данных: Гибридный 13-граммовый и 7-граммовый алгоритм используется для устранения возможного пересечения обучающих данных с эталонами обзора и предотвращения переподгонки модели.
IX. Ресурсы и время на обучение
1. Время обучения
Хотя в официальном отчете не указано общее время обучения Phi-4, подумайте:
- Масштаб модели: 14B Параметры.
- Объем обучающих данных: Предтренировочный этап - 10T жетонов, середина тренировки - 250B жетонов.
Можно предположить, что весь процесс обучения занял значительное количество времени.
2. потребление ресурсов GPU
| Графические процессоры | 1920 H100-80G |
| Время обучения | 21 день |
| Учебные данные | 9.8T жетоны |
X. Применение и ограничения
1. сценарии применения
- Система вопросов и ответов: Phi-4 отлично справляется со сложными задачами викторины и подходит для всех видов интеллектуальных приложений викторины.
- Генерация и понимание кода: Отлично справляется с задачами программирования и может использоваться в таких сценариях, как обучение коду, автоматическая генерация и отладка.
- Многоязычный перевод и обработка: Многоязычная поддержка для глобализированных языковых служб.
2. потенциальные ограничения
- Отбор знаний: Знания модели обрываются на обучающих данных, и она может ничего не знать о событиях, происходящих после обучения.
- Задача длинной последовательности: Хотя длина контекста увеличена до 16 Кбайт, при работе с более длинными последовательностями все равно могут возникнуть проблемы.
- Контроль рисков: Несмотря на строгие меры безопасности, модели все равно могут быть подвержены атакам противника или случайной генерации неприемлемого контента.
Успех Phi-4 демонстрирует важность качества данных и стратегии обучения при разработке крупномасштабных языковых моделей. Благодаря инновационным методам создания синтетических данных, тщательной стратегии смешивания обучающих данных и передовым методам обучения Phi-4 достигает превосходной производительности при сохранении небольшого размера параметров:
- Навыки рассуждения выдающиеся: Превосходно разбирается в математике, естественных науках и программировании.
- Обработка длинных текстов: Увеличенная длина контекста дает модели преимущество в задачах обработки длинных текстов.
- Безопасность и ответственность: Строгое следование принципам ответственного искусственного интеллекта гарантирует безопасность и этичность моделей.
Phi-4 устанавливает новую планку в разработке малопараметрических количественных моделей, демонстрируя, что, уделяя особое внимание качеству данных и стратегиям обучения, можно добиться превосходной производительности даже при небольших параметрах.
Ссылки: /https://www.microsoft.com/en-us/research/uploads/prod/2024/12/P4TechReport.pdf
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...