
Статья на 10 000 слов, в которой разбирается процесс разработки Text-to-SQL на основе LLM

OlaChat AI Digital Intelligence Assistant - это 10 000 слов глубокого анализа, который поможет вам понять прошлое и настоящее технологии Text-to-SQL.
Диссертация: Интерфейсы баз данных нового поколения: обзор технологий преобразования текста в SQL на основе LLM
Генерация точного SQL из задач на естественном языке (text-to-SQL) является давней проблемой из-за сложности понимания задач пользователем, понимания схемы базы данных и генерации SQL. Традиционные системы преобразования текста в SQL, включаяИскусственная инженерия и глубокие нейронные сетиВ этом направлении был достигнут значительный прогресс. Впоследствии.Предварительно обученные языковые модели (PLM) были разработаны и использованы для задач преобразования текста в SQL, достигнув многообещающей производительности. По мере усложнения современных баз данных соответствующие пользовательские задачи становятся все более сложными, что приводит к тому, что PLM (предварительно обученные модели), ограниченные параметрами, генерируют некорректный SQL. Это требует более сложных методов оптимизации, что, в свою очередь, ограничивает применение систем на основе PLM.
В последнее время большие языковые модели (Large Language Models, LLM) демонстрируют значительные возможности в понимании естественного языка благодаря росту размера модели. Поэтому интеграция реализаций на основе LLMможет принести уникальные возможности, улучшения и решения для исследований в области text-to-SQL. В данном обзоре представлен всесторонний обзор систем преобразования текста в SQL на основе LLM. В частности, авторы представляют краткий обзор технических проблем и эволюционного процесса преобразования текста в SQL. Затем авторы дают подробное описание наборов данных и оценочных метрик, разработанных для оценки систем преобразования текста в SQL. После этого в статье проводится систематический анализ последних достижений в области преобразования текстов в SQL на основе LLM. Наконец, обсуждаются оставшиеся проблемы в этой области и представляются ожидания относительно будущих направлений исследований.
С работами, на которые в тексте имеются ссылки через "[xx]", можно ознакомиться в разделе "Ссылки" оригинальной статьи.
вводная
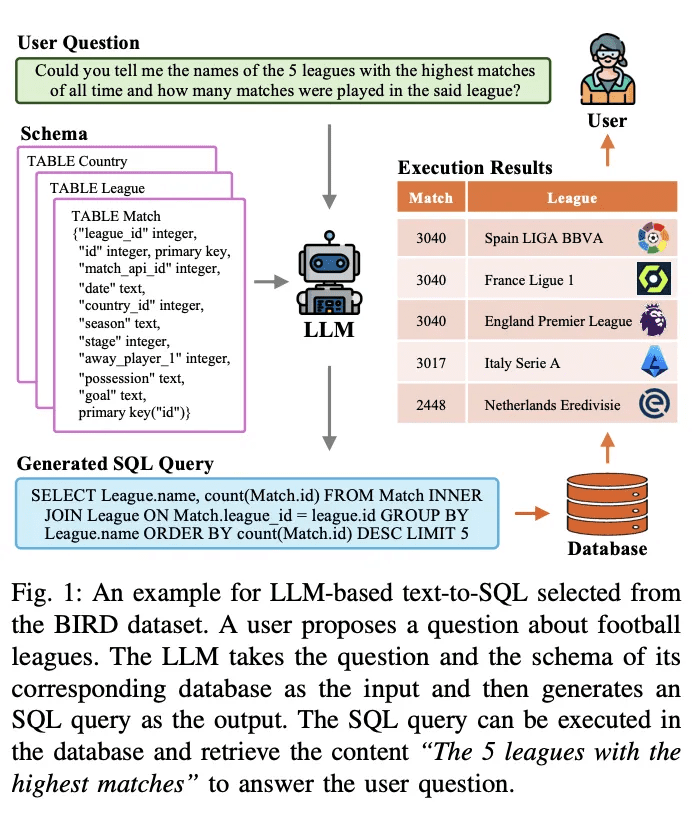
Text-To-SQL - давняя задача в исследованиях по обработке естественного языка. Она направлена на преобразование (перевод) проблем естественного языка в исполняемые в базе данных SQL-запросы. На рисунке 1 приведен пример системы преобразования текста в SQL, основанной на крупномасштабной языковой модели (LLM). Если пользователь задает вопрос, например, "Можете ли вы сказать мне названия 5 самых играемых лиг в истории и сколько игр было сыграно в этой лиге?", LLM переводит вопрос и соответствующий ему запрос в исполняемый SQL-запрос. LLM принимает вопрос и соответствующую ему схему базы данных в качестве входных данных и анализирует их. Затем он генерирует SQL-запрос. Этот SQL-запрос может быть выполнен в базе данных для извлечения релевантного содержимого, отвечающего на вопрос пользователя. Вышеописанная система использует LLM для создания интерфейса естественного языка к базе данных (NLIDB).
Поскольку SQL по-прежнему является одним из самых распространенных языков программирования, а половина (51,52%) профессиональных разработчиков используют SQL в своей работе, и, что примечательно, только около трети (35,29%) разработчиков обучены работе с системой, NLIDB позволяет неквалифицированным пользователям получать доступ к структурированным базам данных, как профессиональные инженеры баз данных [1, 2]. , а также ускоряет взаимодействие человека и компьютера [3]. Кроме того, среди горячих точек исследований в области LLM, text-to-SQL может заполнить пробел в знаниях LLM путем включения реального контента из баз данных, предоставляя потенциальные решения для повсеместной проблемы иллюзий [4, 5] [6]. Большая ценность и потенциал text-to-SQL вызвали ряд исследований по его интеграции и оптимизации с LLM [7-10]; таким образом, text-to-SQL на основе LLM остается широко обсуждаемой областью исследований в сообществах NLP и баз данных.
Предыдущие исследования достигли значительного прогресса в реализации преобразования текста в SQL и прошли долгий эволюционный процесс. Большинство ранних исследований было основано на хорошо разработанных правилах и шаблонах [11], которые особенно подходили для простых сценариев работы с базами данных. В последние годы разработка правил или шаблонов для каждого сценария становится все более сложной и непрактичной из-за высоких трудозатрат, связанных с подходами, основанными на правилах [12], и растущей сложности сред баз данных [13 - 15]. Прогресс в области преобразования текста в SQL был достигнут благодаря разработке глубоких нейронных сетей [16, 17], которые автоматически обучают отображениям вопросов пользователя в соответствующий SQL [18, 19]. Впоследствии предварительно обученные языковые модели (PLM) с мощными возможностями семантического разбора стали новой парадигмой для систем преобразования текста в SQL [20], подняв их производительность на новый уровень [21 - 23]. Прогрессивные исследования по оптимизации на основе PLM (например, кодирование содержимого таблиц [ 19 , 24 , 25 ] и предварительное обучение [ 20 , 26 ]) еще больше продвинули эту область. Недавно.Подход, основанный на LLM, реализует преобразование текста в SQL с помощью парадигм контекстного обучения (ICL) [8] и тонкой настройки (FT) [10].Компания добивается самой современной точности благодаря хорошо продуманной структуре и более глубокому пониманию PLM.
Общие детали реализации преобразования текста в SQL на основе LLM можно разделить на три области:
1) Понимание проблемыВопросы NL являются семантическими представлениями намерений пользователя, и соответствующие генерируемые SQL-запросы должны соответствовать им;
2) Понимание узоров: Схема содержит структуру таблиц и столбцов базы данных, а система преобразования текста в SQL должна определить целевой компонент, соответствующий задаче пользователя;
3) Генерация SQLЭто предполагает комбинирование вышеупомянутого синтаксического анализа и последующее предсказание правильного синтаксиса для генерации исполняемого SQL-запроса для получения желаемого ответа. Было показано, что LLM могут хорошо реализовать функциональность преобразования текста в SQL [7, 27], благодаря более мощным возможностям семантического разбора, обеспечиваемым более богатыми обучающими корпорациями [28, 29]. Дальнейшие исследования по улучшению LLM для понимания проблем [8, 9], понимания паттернов [30, 31] и генерации SQL [32] продолжаются.
Несмотря на значительный прогресс в исследованиях по преобразованию текста в SQL, все еще существует ряд проблем, которые препятствуют разработке надежных систем преобразования текста в SQL общего назначения [ 73 ]. В последние годы в соответствующих исследованиях рассматривались системы преобразования текста в SQL на основе подходов глубокого обучения, а также давались представления о предыдущих подходах глубокого обучения и исследованиях на основе PLM. Цель данного обзора - проследить за последними достижениями и предоставить полный обзор современных моделей и подходов для преобразования текста в SQL на основе LLM. Сначала представлены основные концепции и проблемы, связанные с преобразованием текста в SQL, и подчеркнута важность этой задачи в различных областях. Затем дается подробный обзор эволюции парадигм реализации систем преобразования текста в SQL, обсуждаются основные достижения и прорывы в этой области. За обзором следует подробное описание и анализ последних достижений в области преобразования текста в SQL для интеграции LLM. В частности, этот обзорный документ охватывает ряд тем, связанных с преобразованием текста в SQL на основе LLM, включая:
● Наборы данных и контрольные показатели: Подробное описание широко используемых наборов данных и бенчмарков для оценки систем преобразования текста в SQL на основе LLM. Обсуждаются их характеристики, сложность и проблемы, которые они создают для разработки и оценки систем преобразования текста в SQL.
● Оценка показателей: Будут представлены метрики, используемые для оценки производительности систем преобразования текста в SQL на основе LLM, включая примеры, основанные на сопоставлении содержимого и на выполнении. Затем будут кратко описаны характеристики каждой метрики.
● Методы и модели: В данной статье представлен систематический анализ различных подходов и моделей, используемых для преобразования текста в SQL на основе LLM, включая примеры, основанные на контекстном обучении и тонкой настройке. Детали их реализации, преимущества и адаптация к задачам преобразования текста в SQL обсуждаются с различных точек зрения.
● Ожидания и будущие направления: В данной статье рассматриваются оставшиеся проблемы и ограничения преобразования текста в SQL на основе LLM, такие как устойчивость к реальным условиям, вычислительная эффективность, конфиденциальность данных и масштабирование. Также описываются потенциальные направления будущих исследований и возможности для улучшения и оптимизации.
в общих чертах
Text-to-SQL - это задача, целью которой является преобразование вопросов на естественном языке в соответствующие SQL-запросы, которые могут быть выполнены в реляционной базе данных. Формально, учитывая вопрос пользователя Q (также известный как пользовательский запрос, вопрос на естественном языке и т. д.) и схему базы данных S, целью задачи является создание SQL-запроса Y, который извлекает необходимое содержимое из базы данных для ответа на вопрос пользователя. Технология Text-to-SQL способна демократизировать доступ к данным, позволяя пользователям взаимодействовать с базой данных на естественном языке без необходимости знания SQL-программирования [75]. Позволяя неквалифицированным пользователям легко извлекать нужный контент из баз данных и способствуя более эффективному анализу данных, эта технология может принести пользу в таких различных областях, как бизнес-аналитика, поддержка клиентов и научные исследования.
A. Проблемы преобразования текста в SQL
Технические проблемы, связанные с реализацией преобразования текста в SQL, можно свести к следующему:
1)Языковая сложность и двусмысленность: Проблемы естественного языка часто содержат сложные лингвистические представления, такие как вложенные клаузулы, совместные ссылки и эллипсы, что затрудняет их точное сопоставление с соответствующими частями SQL-запроса [41]. Кроме того, естественный язык по своей природе неоднозначен и имеет множество возможных представлений для данной проблемы пользователя [76, 77]. Разрешение этих неоднозначностей и понимание замысла, лежащего в основе проблемы пользователя, требует глубокого понимания естественного языка и способности интегрировать контекстуальные и доменные знания [33].
2)Понимание и представление паттернов: Для создания точных SQL-запросов системам преобразования текста в SQL требуется глубокое понимание схемы базы данных, включая имена таблиц, названия столбцов и связи между отдельными таблицами. Однако схемы баз данных могут быть сложными и сильно различаться в разных областях [13]. Представление и кодирование информации о схеме таким образом, чтобы она могла быть эффективно использована моделями преобразования текста в SQL, является сложной задачей.
3)Редкие и сложные операции SQL: Некоторые SQL-запросы включают редкие или сложные операции и синтаксис в сложных сценариях, такие как вложенные подзапросы, внешние объединения и оконные функции. Эти операции реже встречаются в обучающих данных и представляют собой проблему для точного создания систем преобразования текста в SQL. Разработка моделей, обобщающих различные операции SQL, включая редкие и сложные сценарии, является важным моментом.
4)междоменное обобщение: Системы преобразования текста в SQL часто трудно обобщить на различные сценарии и домены баз данных. Из-за разнообразия словарей, структур схем баз данных и моделей задач модели, обученные в конкретном домене, могут плохо справляться с проблемами, возникающими в других доменах. Разработка систем, которые могут быть эффективно обобщены на новые области с использованием минимального количества обучающих данных для конкретной области или точной адаптации, является серьезной задачей [78].
B. Эволюционные процессы
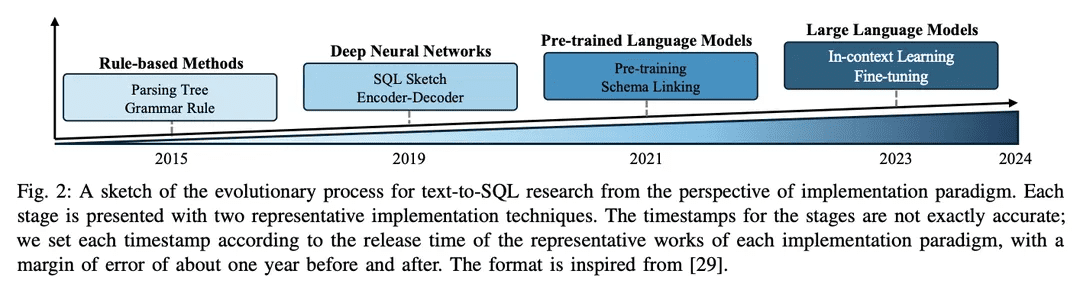
За прошедшие годы область исследований преобразования текста в SQL достигла больших успехов в сообществе NLP, эволюционировав от подходов на основе правил к подходам на основе глубокого обучения, а в последнее время - к интеграции предварительно обученных языковых моделей (PLM) и крупномасштабных языковых моделей (LLM); набросок процесса эволюции показан на рисунке 2.
1) Подход, основанный на правилах: Ранние системы преобразования текста в SQL в значительной степени опирались на подходы, основанные на правилах [11, 12, 26], то есть на использование вручную сформулированных правил и эвристик для отображения проблем естественного языка в SQL-запросы. Эти подходы, как правило, предполагают значительную разработку функций и знание специфики области. Хотя подходы, основанные на правилах, были успешны в конкретных простых областях, им не хватает гибкости и обобщающих возможностей, необходимых для решения широкого спектра сложных проблем.
2)Подход, основанный на глубоком обучении: С развитием глубоких нейронных сетейМоделирование последовательности и архитектура кодера-декодера(например, LSTM [ 79] и преобразователи [17]) используются для генерации SQL-запросов на основе естественного языка [ 19 , 80 ]. Как правило, в RYANSQL [19] используются такие техники, как промежуточные представления и заполнение слотов на основе эскизов для решения сложных задач и улучшения междоменной общности. В последнее время исследователи используют схемно-зависимыеГрафики отражают отношения между элементами базы данныхПервым шагом было внедрение новой задачи преобразования текста в SQL, а именноГрафовые нейронные сети (ГНС)[18,81].
3) Внедрение на основе PLMПредварительно обученные языковые модели (PLM) стали мощным решением для преобразования текста в SQL благодаря использованию обширных лингвистических знаний и семантического понимания, полученных в процессе предварительного обучения. Первые применения PLM в преобразовании текста в SQL были направлены на тонкую настройку готовых PLM на стандартных наборах данных для преобразования текста в SQL, таких как BERT [24] и RoBERTa [82] [13, 14]. Эти PLM предварительно натренированы на большом обучающем корпусе, что обеспечивает богатые семантические представления и возможности понимания языка. Настраивая их в задачах преобразования текста в SQL, исследователи стремятся использовать возможности семантического и лингвистического понимания PLM для генерации точных SQL-запросов [ 20, 80, 83]. Еще одно направление исследований - включение в PLM информации о схемах, чтобы улучшить способ, которым эти системы могут помочь пользователям понять структуру баз данных и генерировать более исполняемые SQL-запросы. PLM, учитывающие схему, разработаны таким образом, чтобы улавливать взаимосвязи и ограничения, присутствующие в структуре базы данных [21].
4) Реализация на основе LLM: Большие языковые модели (LLM), такие как семейство GPT [ 84-86], в последние годы привлекают большое внимание благодаря своей способности генерировать связный и беглый текст. Исследователи начали изучать потенциал преобразования текста в SQL, используя обширную базу знаний и превосходные генеративные возможности LLM [7, 9]. Эти подходы, как правило, включают в себя управление проектированием подсказок собственных LLM во время генерации SQL [47] или тонкую настройку открытых LLM на наборах данных для преобразования текста в SQL [9].
Интеграция LLM в text-to-SQL все еще является развивающейся областью исследований с большим потенциалом для дальнейшего изучения и совершенствования. Исследователи изучают, как лучше использовать знания и возможности рассуждений LLM, включать специфические знания [31, 33] и разрабатывать более эффективные стратегии тонкой настройки [ 10 ]. Ожидается, что по мере развития этой области будут разработаны более совершенные и превосходные реализации на основе LLM, которые поднимут производительность и обобщенность преобразования текста в SQL на новую высоту.
Контрольные показатели и оценки
В этом разделе представлены эталоны преобразования текста в SQL, включая известные наборы данных и метрики оценки.
A. Наборы данных
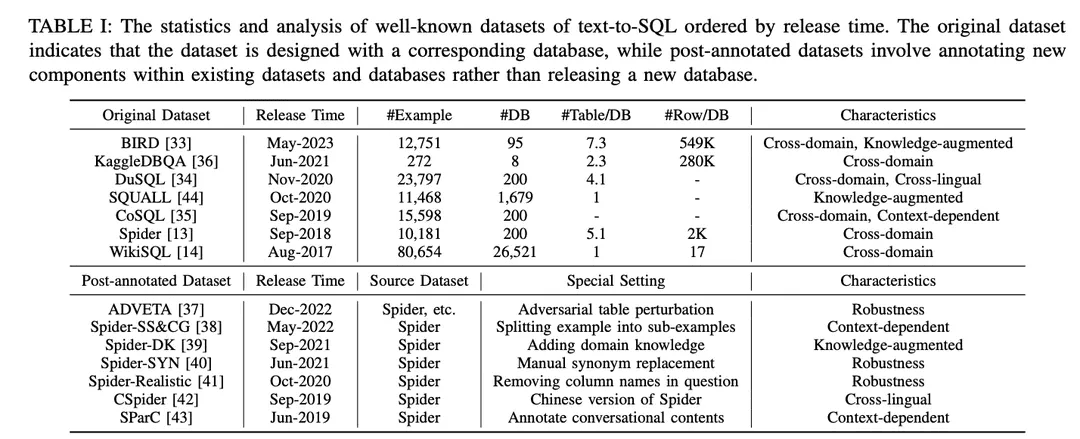
Как показано в таблице I, наборы данных делятся на "оригинальные наборы данных" и "наборы данных после аннотирования". Наборы данных делятся на "оригинальные наборы" и "наборы после аннотирования" в зависимости от того, опубликованы ли они вместе с оригинальными наборами и базами данных или созданы путем внесения специальных настроек в существующие наборы и базы данных. Для оригинальных наборов данных приводится подробный анализ, включая количество примеров, количество баз данных, количество таблиц в базе данных и количество строк в базе данных. Для аннотированных наборов данных указаны их исходные наборы данных и описаны конкретные настройки, примененные к ним. Чтобы проиллюстрировать потенциальные возможности каждого набора данных, он был аннотирован в соответствии с его характеристиками. Аннотации перечислены в крайней правой части таблицы I. Более подробно они рассматриваются ниже.
1) Междоменные наборы данных: относится к наборам данных, в которых исходная информация для разных баз данных поступает из разных доменов. Поскольку реальные приложения для работы с текстом на SQL обычно включают базы данных из нескольких доменов, большинство оригинальных наборов данных для работы с текстом на SQL [13,14,33-36] и наборов данных для пост-аннотирования [37-43] имеют кросс-доменную структуру, что хорошо подходит для кросс-доменных приложений.
2) Наборы данных с расширенными знаниямиBIRD [ 33] использует человеческих экспертов баз данных для аннотирования каждого примера преобразования текста в SQL с помощью внешних знаний, классифицированных как знания о числовых рассуждениях, знания о домене, знания о синонимах и утверждениях о значении. Аналогично, Spider-DK [ 39] вручную отредактировал версию набора данных Spider [13] для редакторов-людей: столбец SELECT был опущен, требовались простые рассуждения, замена синонимов в словах, имеющих значение ячейки, слово, не имеющее значения ячейки, создает условие и склонно к конфликтам с другими доменами. Оба исследования показали, что аннотированные вручную знания значительно улучшают производительность генерации SQL для примеров, требующих внешних знаний о домене. Кроме того, в SQUALL [44] вручную аннотируется выравнивание между словами в задачах NL и сущностями в SQL, что обеспечивает более тонкий контроль, чем в других наборах данных.
3) Контекстно значимые наборы данныхSParC [43] и CoSQL [35] исследуют контекстно-зависимую генерацию SQL, создавая систему запросов для сессионных баз данных. В отличие от традиционных наборов данных text-to-SQL, которые содержат одну пару вопрос SQL с одним примером, SParC декомпозирует примеры вопросов SQL в наборе данных Spider на множество пар подвопросов SQL для построения симулированных и значимых взаимодействий, включая взаимосвязанные подвопросы, которые способствуют генерации SQL, и несвязанные подвопросы, которые увеличивают разнообразие данных. В отличие от этого, CoSQL предполагает диалоговое взаимодействие на естественном языке, которое имитирует реальные сценарии, что повышает сложность и разнообразие. Более того, Spider-SS&CG [38] разбивает проблему NL в наборе данных Spider [13] на множество подпроблем и подSQL, демонстрируя, что обучение на этих подпримерах улучшает распределение образцов обобщающих возможностей системы преобразования текста в SQL.
4) Наборы данных для проверки надежностиОценка точности системы преобразования текста в SQL в присутствии загрязненного или искаженного содержимого базы данных (например, схем и таблиц) имеет решающее значение для оценки надежности.Spider-Realistic [ 41] удаляет из вопросов NL термины, явно связанные со схемой, а Spider-SYN [ 40] заменяет их вручную подобранными синонимами.ADVETA [ 37] представила метод adversarial table perturbation (ATP), который возмущает таблицу, заменяя оригинальные названия столбцов вводящими в заблуждение заменами и вставляя новые столбцы с высокой семантической релевантностью, но низкой семантической эквивалентностью. Такие возмущения могут привести к значительному снижению точности, поскольку менее надежные системы преобразования текста в SQL могут быть введены в заблуждение несоответствием между лексемами и сущностями базы данных в проблемах NL.
5) Межъязыковые наборы данныхКлючевые слова SQL, имена функций, названия таблиц и столбцов часто написаны на английском языке, что создает проблемы для приложений на других языках.CSpider [ 42 ] перевел набор данных Spider на китайский язык и обнаружил новые проблемы в сегментации слов и межъязыковом сопоставлении китайских вопросов и английского содержимого базы данных.DuSQL [34] представляет практический набор данных text-to-SQL, содержащий DuSQL [34] представляет практический набор данных для преобразования текста в SQL с китайскими вопросами и содержимым баз данных на английском и китайском языках.
B. Показатели оценки
Для задач преобразования текста в SQL представлены следующие четыре широко используемые метрики оценки: "Сопоставление компонентов" и "Точное сопоставление", основанные на сопоставлении содержания SQL, "Точность выполнения", основанная на результатах выполнения " и "Эффективная оценка эффективности".
1) Метрики, основанные на сопоставлении контента: Метрика соответствия содержимого SQL основана, прежде всего, на структурном и синтаксическом сходстве предсказанного SQL-запроса с реальным SQL-запросом, лежащим в основе.
Согласование компонентов (CM)[13] Производительность системы преобразования текста в SQL оценивается путем измерения точных совпадений между предсказанными компонентами SQL (SELECT, WHERE, GROUP BY, ORDER BY и KEYWORDS) и реальными компонентами SQL (GROUP BY, ORDER BY и KEYWORDS) с помощью оценок F1. Каждый компонент декомпозируется на наборы подкомпонентов и сравнивается на предмет точного совпадения с учетом компонентов SQL без ограничений порядка.
Точное соответствие (EM))[ 13] измеряет процент примеров, в которых предсказанный SQL-запрос полностью совпадает с истинным SQL-запросом. Предсказанный SQL-запрос считается правильным только в том случае, если все его компоненты (как описано в CM) точно совпадают с компонентами истинного запроса.
2) Показатели, основанные на реализацииМетрика Execution Results оценивает корректность сгенерированного SQL-запроса, сравнивая результаты, полученные при выполнении запроса в целевой базе данных, с ожидаемыми результатами.
Точность исполнения (EX)[13] Правильность предсказанного SQL-запроса измеряется выполнением запроса в соответствующей базе данных и сравнением результатов с результатами, полученными при выполнении истинного запроса.
Показатель эффективности (VES)Определение, данное в [33], заключается в измерении эффективности эффективного SQL-запроса. Эффективный SQL-запрос - это предсказанный SQL-запрос, результат выполнения которого идентичен истинному результату, лежащему в основе. В частности, VES одновременно оцениваетПрогнозирование эффективности и точности SQL-запросов. Для набора текстовых данных, содержащего N примеров, VES рассчитывается как:

R(Y_n, Y_n) обозначает относительную эффективность выполнения предсказанного SQL-запроса по сравнению с реальным запросом.
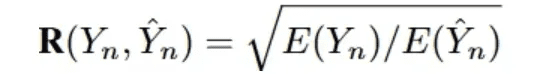
Большинство последних исследований в области преобразования текста в SQL на основе LLM было сосредоточено на этих четырех наборах данных: Spider [13], Spider-Realistic [41], Spider-SYN [40] и BIRD [33]; а также на трех методах оценки - EM, EX и VES, которые будут рассмотрены ниже.
методологии
Современные реализации приложений на основе LLM в значительной степени опираются на парадигмы In-Context Learning (ICL) (Just-in-Time Engineering) [87-89] и Fine-Tuning (FT) [90,91], поскольку мощные проприетарные и хорошо проработанные модели с открытым исходным кодом выпускаются в большом количестве [45,86,92-95]. Системы преобразования текста в SQL на основе LLM следуют этим парадигмам при реализации. В данном обзоре они будут рассмотрены соответствующим образом.
A. контекстное обучение
В ходе обширных и признанных исследований было показано, что инженерия подсказок играет решающую роль в производительности LLM [28 , 96 ], а также влияет на генерацию SQL при различных стилях подсказок [9 , 46]. Поэтому разработка методов преобразования текста в SQL в парадигме контекстного обучения (ICL) имеет большое значение для достижения перспективных улучшений. Реализация процесса преобразования текста в SQL на основе LLM, генерирующего исполняемый SQL-запрос Y, может быть сформулирована следующим образом:

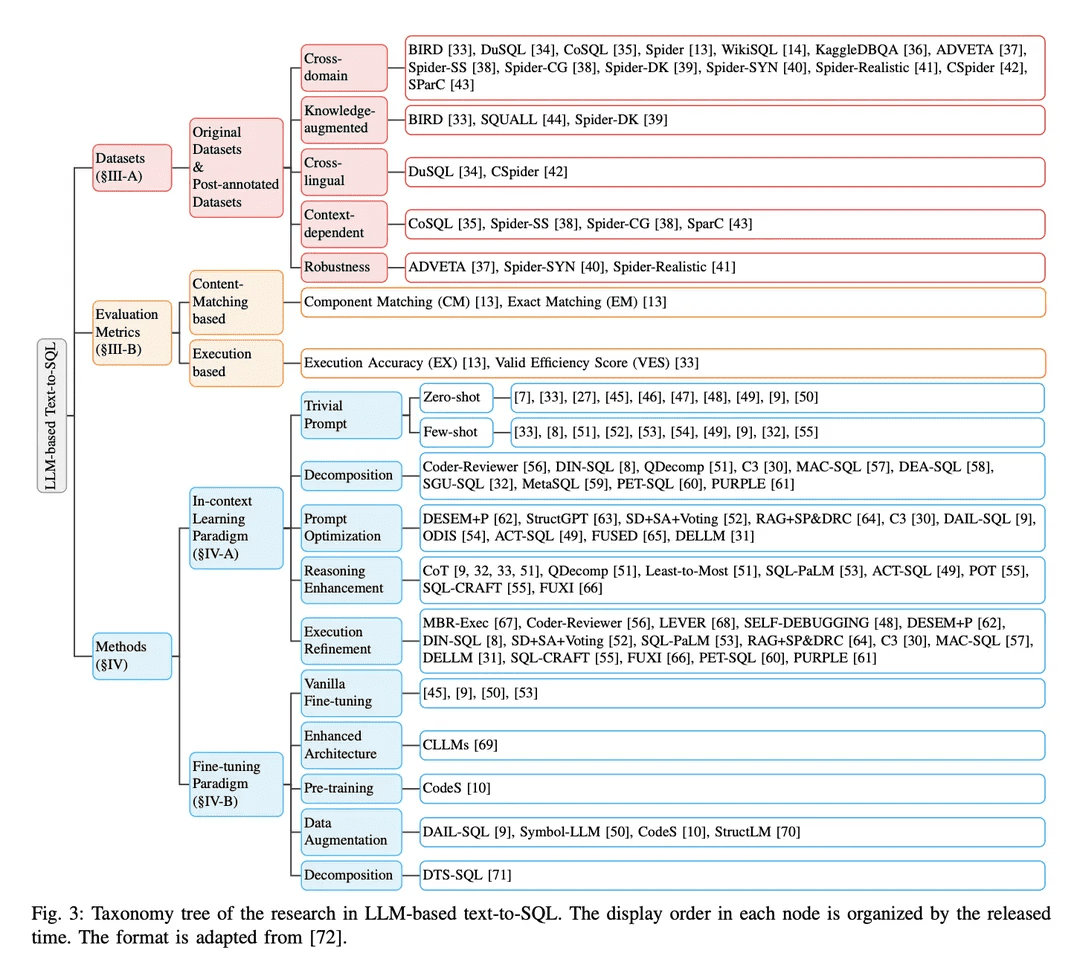
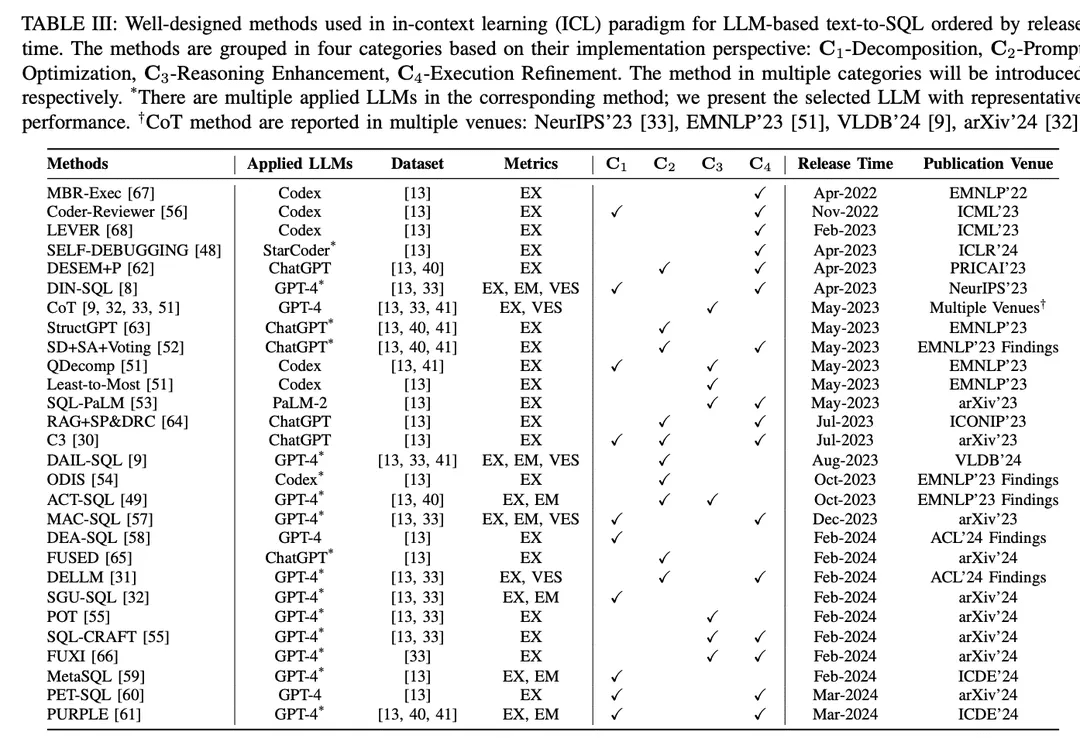
В парадигме контекстного обучения (ICL) готовая модель преобразования текста в SQL (т. е. параметр θ модели заморожен) используется для генерации предсказанных SQL-запросов. В задачах преобразования текста в SQL на основе LLM используется целый ряд хорошо разработанных методов в парадигме ICL. Они делятся на пять категорий C0:4, включая C0-простые подсказки, C1-декомпозиция, C2-оптимизация подсказок, C3-улучшение вывода и C4-уточнение выполнения. В таблице II перечислены представители каждой категории.
C0-Тривиальная подсказка: Обученный на массивных данных, LLM обладает высокой общей квалификацией в различных задачах с нулевой выборкой и малым числом подсказок [90, 97, 98 ], что широко признано и применяется в практических приложениях. В данном исследовании вышеупомянутые методы подсказки без продуманного обрамления были отнесены к категории тривиальных подсказок (ложная инженерия подсказок). Как упоминалось выше, уравнение 3 описывает процесс преобразования текста в SQL на основе LLM, который также можно обозначить как подсказку с нулевой выборкой. Общий вход P0 получается путем конкатенации I, S и Q. Вход P0 совпадает с общим входом P0:
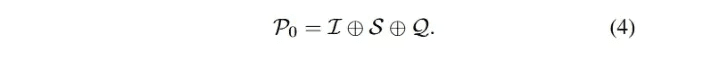
Чтобы стандартизировать процесс подсказки, в OpenAI demo2 была установлена стандартная (простая) подсказка для преобразования текста в SQL [30].
нулевой образец: Многие исследовательские работы [7,27,46] используют подсказки с нулевой выборкой, фокусируясь на влиянии стилей построения подсказок и различных LLM на производительность text-to-SQL с нулевой выборкой. В качестве эмпирической оценки в [7] оценивалась производительность различных ранних LLM [85, 99, 100] для базовой функциональности text-to-SQL, а также для различных стилей построения подсказок. Результаты показывают, что проектирование "на лету" имеет решающее значение для производительности, а анализ ошибок показал, что большее количество содержимого базы данных может ухудшить общую точность. Поскольку ChatGPT с впечатляющими возможностями диалоговых сценариев и генерации кода [101], в [27] была проведена оценка его производительности преобразования текста в SQL. Результаты показали, что при нулевой выборке ChatGPT демонстрирует впечатляющую производительность преобразования текста в SQL по сравнению с современными системами на базе PLM. Для справедливого сравнения в работе [47] были выявлены эффективные конструкции подсказок для преобразования текста в SQL на основе LLM; они исследовали различные стили конструкций подсказок и на основе сравнения сделали вывод о конструкции подсказок с нулевой выборкой.
Первичные и внешние ключи несут в себе непрерывную информацию о различных таблицах. В работе [49] изучалось их влияние путем включения этих ключей в различные стили представления подсказок для разных баз данных и анализа результатов работы подсказок с нулевой выборкой. Влияние внешних ключей также изучалось в эталонной оценке [9], где было включено пять различных стилей представления подсказок, каждый из которых можно рассматривать как перестановку директив, значений правил и внешних ключей. В дополнение к внешним ключам в данном исследовании также изучалась комбинация подсказок с нулевой выборкой и "неинтерпретируемых" последствий правил для получения краткого вывода. В работе [33 ] при поддержке аннотирования внешних знаний человеческих экспертов использовались стандартные подсказки и достигались улучшения за счет комбинирования предоставленных аннотированных знаний оракула.
С ростом числа LLM с открытым исходным кодом эти модели, согласно аналогичным оценкам [45, 46, 50], также способны решать задачи преобразования текста в SQL на нулевой выборке, особенно модели генерации кода [46, 48]. В работе [46], посвященной оптимизации подсказок для нулевой выборки, была поставлена задача разработки эффективных шаблонов подсказок для LLM; предыдущим конструкциям подсказок не хватало структурного единства, что затрудняло определение конкретных элементов в шаблонах конструкций подсказок, которые влияют на производительность LLM. Чтобы решить эту проблему, они исследовали серию более единообразных шаблонов подсказок, настроенных на различные префиксы, суффиксы и префиксы-постфиксы.
Несколько советов: Техника малого числа подсказок широко используется как в практических приложениях, так и в хорошо спланированных исследованиях, и она показала свою эффективность в улучшении производительности LLM [ 28 , 102 ]. Общая входная подсказка метода подсказки текста к SQL на основе LLM для малого числа подсказок может быть сформулирована как расширение уравнения 3:

В качестве эмпирического исследования подсказки несколькими выстрелами для преобразования текста в SQL были оценены на нескольких наборах данных и различных LLM [8, 32] и показали хорошую производительность по сравнению с подсказками с нулевой выборкой. В [33] приводится подробный пример одномоментного запуска модели преобразования текста в SQL для генерации точного SQL. В [55] исследуется влияние небольшого числа примеров. В [52] основное внимание уделяется стратегиям выборки: изучается сходство и разнообразие между различными примерами, проводится сравнительный анализ случайной выборки, а также оцениваются различные стратегии8 и их комбинации для сравнения. Кроме того, в дополнение к отбору на основе сходства в [9] оцениваются верхние границы отбора по сходству для проблем маскировки и методы сходства с различным числом меньших образцов. В исследовании, посвященном выбору образцов на уровнях сложности [51], сравнивается производительность Codex [100] со случайным и основанным на сложности отбором экземпляров с малой выборкой на наборе категориальных данных сложности [13, 41]. Были разработаны три стратегии отбора на основе сложности, основанные на количестве образцов, отобранных на разных уровнях сложности. В [49] для отбора образцов использовалась гибридная стратегия, сочетающая статические примеры и динамические примеры на основе сходства для небольшого числа подсказок. В своей установке они также оценили влияние различных стилей входных шаблонов и различных размеров статических и динамических образцов.
Также изучается влияние небольшого количества примеров в разных доменах [54 ]. При включении различного количества примеров в домене и вне домена примеры в домене превосходили примеры нулевого порядка и примеры вне домена, а примеры в домене превосходили примеры в нулевом порядке и вне домена.По мере увеличения количества примеров производительность примеров, находящихся в домене, становится все выше.. Чтобы изучить детальное построение входных подсказок, в [53] сравниваются подходы к проектированию кратких и многословных подсказок. В первом случае схема, имена столбцов, первичные и внешние ключи разбиваются по записям, а во втором они организуются в виде описаний на естественном языке.
C1-РазложениеКак интуитивное решение, декомпозиция сложных пользовательских проблем на более простые подпроблемы или их реализация с использованием нескольких компонентов может снизить сложность общей задачи преобразования текста в SQL [8, 51]. При решении менее сложных задач LLM обладает потенциалом для генерации более точного SQL. Методы декомпозиции текста в SQL, основанные на LLM, делятся на две парадигмы:(1) Разбивка подзадачКроме того, разбивая всю задачу преобразования текста в SQL на более управляемые и эффективные подзадачи (например, связывание схем [71], классификация доменов [54]), можно обеспечить дополнительный синтаксический анализ, который поможет в окончательном создании SQL.(2) Декомпозиция подпроблемы: Декомпозиция проблемы пользователя на подпроблемы для уменьшения сложности и трудности проблемы, а затем получение окончательного SQL-запроса путем решения этих проблем для генерации под-SQL.
DIN-SQLВ [8] предложен метод декомпозированного контекстного обучения, включающий четыре модуля: связывание схем, классификация и декомпозиция, генерация SQL и самокоррекция. DIN-SQL сначала генерирует схемную связь между проблемой пользователя и целевой базой данных; последующий модуль декомпозирует проблему пользователя на связанные подпроблемы и классифицирует их сложность. На основе этой информации модуль генерации SQL генерирует соответствующий SQL, а модуль самокоррекции выявляет и исправляет потенциальные ошибки в предсказанном SQL. В данном подходе декомпозиция подпроблем рассматривается как модуль декомпозиции подзадач. Фреймворк Coder-Reviewer [56] предлагает подход к переупорядочиванию, который объединяет модель Coder для генерации инструкций и модель Reviewer для оценки вероятности инструкций.
Ссылаясь на Chain-of-Thought [103] и Least-to-Most [104], подсказкиQDecompВ [51] введена подсказка декомпозиции проблемы, которая следует за фазой редукции проблемы от последней к последней подсказке и предписывает LLM выполнить декомпозицию исходной сложной проблемы в качестве промежуточного шага рассуждения
C3 [ 30] состоит из трех ключевых компонентов: подсказки ясности, подсказки смещения калибровки и согласованности; эти компоненты реализуются путем постановки различных задач перед ChatGPT. Сначала компонент подсказок для ясности генерирует ссылки на схемы и уточненные схемы, связанные с вопросом, в качестве подсказок для ясности. Затем в качестве калибровочных подсказок используются несколько раундов диалога о подсказках "текст - SQL", которые, в сочетании с ясными подсказками, направляют генерацию SQL-запросов. Сгенерированные SQL-запросы фильтруются с помощью голосования по согласованности и выполнению для получения окончательного SQL.
MAC-SQLВ [57] предложена многоагентная совместная структура; процесс преобразования текста в SQL выполняется в сотрудничестве с такими агентами, как селекторы, декомпозиторы и рафинеры. Селектор хранит соответствующие таблицы для пользовательской задачи; декомпозитор разбивает пользовательскую задачу на подпроблемы и предлагает решения; наконец, рафинер проверяет и оптимизирует дефектный SQL.
DEA- SQL В работе [58] представлена парадигма рабочего процесса, направленная на улучшение внимания и объема решения проблем при преобразовании текста в SQL на основе LLM за счет декомпозиции. Подход декомпозирует общую задачу таким образом, что модуль генерации SQL имеет соответствующие предварительные (определение информации, классификация проблемы) и последующие (самокоррекция, активное обучение) подзадачи. Парадигма рабочего процесса позволяет LLM генерировать более точные SQL-запросы
SGU-SQL [ 32] - это фреймворк для преобразования структуры в SQL, который использует встроенную структурную информацию для помощи в генерации SQL. В частности, фреймворк строит графовые структуры для вопросов пользователя и соответствующих баз данных, соответственно, а затем использует закодированные графы для построения структурных связей [105, 106]. Метаоператоры используются для декомпозиции проблем пользователя с помощью синтаксических деревьев, и, наконец, метаоператоры в SQL используются для разработки подсказок ввода.
MetaSQL В [ 59] представлен трехфазный подход к генерации SQL: декомпозиция, генерация и сортировка. На этапе декомпозиции используется комбинация семантической декомпозиции и метаданных для решения проблем пользователя. Используя ранее обработанные данные в качестве входных данных, генерируются несколько SQL-запросов-кандидатов с использованием модели преобразования текста в SQL, созданной на основе условий метаданных. Наконец, для получения глобального оптимального SQL-запроса применяется двухступенчатый конвейер сортировки.
PET-SQL В [ 60] представлена двухэтапная схема с использованием подсказок. Сначала хорошо продуманные подсказки инструктируют LLM сгенерировать предварительный SQL (PreSQL), где несколько небольших демонстраций выбираются на основе сходства. Затем на основе PreSQL находятся связи между схемами, которые объединяются и побуждают LLM генерировать окончательный SQL (FinSQL). Наконец, FinSQL генерируется с помощью нескольких LLM для обеспечения согласованности по результатам выполнения.
Оптимизация C2-Prompt: Как было описано ранее, обучение по нескольким порядкам для подсказок LLM было широко изучено [85]. Для преобразования текста в SQL (text-to-SQL) и контекстного обучения на основе LLM тривиальные маломинутные методы дали многообещающие результаты [8, 9, 33], и дальнейшая оптимизация маломинутных подсказок может привести к улучшению производительности. Поскольку точность генерации SQL в готовых LLM сильно зависит от качества соответствующих входных подсказок [107], многие факторы, влияющие на качество подсказок, находятся в центре внимания современных исследований [9] (например, качество и количество организации олиго-подсказок, сходство между задачей пользователя 9 и экземплярами олиго-подсказок, внешние знания/подсказки).
DESEM [ 62] - это фреймворк для разработки подсказок с де-семантизацией и извлечением скелетов. Сначала система использует модуль маскировки слов, специфичный для данной области, для удаления семантических лексем, которые сохраняют намерение в вопросах пользователя. Затем используется настраиваемый модуль подсказок для получения небольшого количества примеров с тем же смыслом, что и в вопросе, и в сочетании с фильтрацией релевантности шаблонов направляет генерацию SQL для LLM.
QDecomp [ 51 ] Фреймворк представляет механизм InterCOL, который инкрементально объединяет декомпозированные подпроблемы с соответствующими именами таблиц и столбцов. С помощью отбора по сложности небольшое количество примеров QDecomp отбирается на предмет сложности. В дополнение к выборке по сходству-разнообразию в [ 52 ] была предложена стратегия выборки SD+SA+Voting (сходство-разнообразие+наращивание шаблонов+голосование). Сначала они отбирают небольшое количество примеров, используя семантическое сходство и разнообразие кластеризации k-Means, а затем дополняют подсказки знанием паттерна (семантическое или структурное дополнение).
C3 Система [ 30] состоит из компонента прозрачной подсказки, который принимает вопросы и схемы в качестве входных данных для LLM, и компонента калибровки, предоставляющего подсказки, который генерирует прозрачную подсказку, включающую схему, удаляющую избыточную информацию, не связанную с вопросом пользователя, и ссылку на схему. LLM используют их композицию в качестве контекстно-усиленной подсказки для генерации SQL. В рамках улучшения поиска используются подсказки с учетом образцов [64], которые упрощают исходную задачу и извлекают из нее скелет задачи, а затем выполняют поиск образцов в хранилище на основе сходства скелетов. Полученные образцы объединяются с исходной задачей для небольшого числа подсказок.
ODIS В [54] представлен отбор образцов с использованием внедоменных презентаций и внутридоменных синтетических данных, который извлекает небольшое количество презентаций из различных источников для улучшения характеристики подсказки
DAIL- SQLВ [9] предложен новый подход к решению проблемы выборки и организации небольшого количества примеров, позволяющий достичь лучшего баланса между качеством и количеством небольшого количества примеров. DAIL Selection сначала маскирует специфическую для домена лексику пользователей и небольшое количество примеров проблем, а затем ранжирует примеры-кандидаты на основе встроенного евклидова расстояния. В то же время вычисляется сходство между заранее предсказанными SQL-запросами. Наконец, механизм выбора получает примеры-кандидаты, отсортированные по сходству на основе заранее заданных критериев. При таком подходе гарантируется, что небольшое количество примеров имеет хорошее сходство как с проблемой, так и с SQL-запросом.
ACT-SQLВ [49] представлены динамические примеры выбора на основе оценок сходства.
FUSED[65] предлагает создать пул презентаций с высоким разнообразием путем многократного синтеза без ручного управления, чтобы улучшить разнообразие презентаций, сделанных несколькими выстрелами. Конвейер FUSED выбирает презентации для объединения с помощью кластеризации, а затем объединяет выбранные презентации, чтобы создать пул презентаций для повышения эффективности обучения несколькими выстрелами.
Знания на SQL [31] Эта система направлена на создание экспертов по данным (Data Expert LLMs, DELLMs), которые предоставляют знания для генерации SQL.
DELLM DELLM генерирует четыре типа знаний, и хорошо разработанные методы (например, DAIL-SQL [9], MAC-SQL [57 ]) используют сгенерированные знания для достижения лучшей производительности при преобразовании текста в SQL на основе LLM за счет контекстного обучения.
C3-Reasoning Enhancement:LLM показали хорошие способности в задачах, связанных с рассуждениями на основе здравого смысла, символическими рассуждениями и арифметическими рассуждениями [108]. В задачах преобразования текста в SQL числовые рассуждения и синонимичные рассуждения часто встречаются в реалистичных сценариях [ 33 , 41 ]. Стратегии подсказок для рассуждений с помощью LLM имеют потенциал для улучшения генерации SQL. Последние исследования были сосредоточены на интеграции хорошо разработанных методов улучшения аргументации для адаптации текста к SQL, улучшении LLM для решения сложных задач, требующих сложных рассуждений3 , и самосогласованности при генерации SQL.
Техника подсказок Chain-of-Thoughts (CoT) [103] представляет собой комплексный процесс рассуждений, который направляет LLM к точным рассуждениям и стимулирует способность LLM к рассуждениям. В исследованиях, основанных на преобразовании текста LLM в SQL, подсказки CoT используются в качестве подсказок к правилам [9], при этом в конструкцию подсказки заложены инструкции "давайте думать шаг за шагом" [9, 32, 33, 51]. Однако прямолинейная (примитивная) стратегия CoT для задач text-to-SQL не показала того потенциала, который она имеет для других задач рассуждения; исследования по адаптации CoT все еще продолжаются [51]. Поскольку подсказки CoT всегда демонстрируются на статичных примерах с ручными аннотациями, это требует эмпирической оценки для эффективного отбора небольшого числа примеров, для которых ручные аннотации необходимы.
В качестве решения.ACT-SQL В [ 49] предлагается метод автоматической генерации примеров CoT. В частности, ACT-SQL, получив задачу, усекает набор фрагментов задачи, а затем перечисляет каждый столбец, который встречается в соответствующем SQL-запросе. Каждый столбец будет связан с наиболее релевантным срезом с помощью функции сходства и добавлен к подсказке CoT.
QDecomp [51] В результате систематического исследования усовершенствования генерации SQL для LLM в сочетании с подсказками CoT была предложена новая структура для решения проблемы того, как CoT предлагает шаги рассуждения для предсказания SQL-запросов. Система использует каждый фрагмент SQL-запроса для построения логических шагов рассуждений CoT, а затем использует шаблоны естественного языка для детализации каждого фрагмента SQL-запроса и расположения их в логическом порядке выполнения.
От наименьшего к наибольшему [ 104 ] - еще одна техника подсказки, которая разбивает задачу на подзадачи и затем последовательно решает их. Пилотные эксперименты [51] показывают, что для синтаксического анализа текста на SQL этот подход может и не понадобиться. Использование подробных шагов рассуждений, как правило, создает больше проблем с распространением ошибок.
Как вариант CoT, вПрограмма мыслей (PoT)Для улучшения арифметических рассуждений в LLM были предложены стратегии подсказок [109].
По оценке [55], PoT улучшает SQL-генерируемые LLM, особенно в сложных наборах данных [33].
SQL-CRAFT В [ 55 ] предлагается дополнить генерацию SQL на основе LLM подсказками PoT для рассуждений с использованием Python. Политика PoT требует от модели генерировать как Python-код, так и SQL-запросы, заставляя модель включать Python-код в процесс рассуждений.
Самосогласованность[110] - это стратегия подсказок для улучшения LLM-рассуждений, которая использует интуицию, что сложная проблема рассуждения обычно допускает несколько различных способов мышления, чтобы прийти к единственно правильному ответу. В задачах преобразования текста в SQL самосогласованность применяется для выборки набора различных SQL и голосования за согласованные SQL с помощью обратной связи [30, 53 ].
Аналогично.SD+SA+голосование [52] Фреймворк отбрасывает ошибки выполнения, выявленные детерминированной системой управления базами данных (СУБД), и выбирает предсказание, получившее большинство голосов.
Кроме того, благодаря недавним исследованиям в области использования инструментов для расширения функциональности LLM, в рамках проектаFUXI В [66] предлагается улучшить генерацию SQL для LLM, эффективно вызывая хорошо разработанные инструменты.
C4-Execution Refinement: При разработке стандартов для точной генерации SQL приоритет всегда отдается тому, может ли сгенерированный SQL быть успешно выполнен и извлечь содержимое для правильного ответа на вопрос пользователя [13]. Как сложная задача программирования, генерация правильного SQL за один раз является очень сложной. Интуитивно понятно, что учет обратной связи/результатов выполнения при генерации SQL помогает согласовать его с соответствующей средой базы данных, что позволяет LLM собирать потенциальные ошибки и результаты выполнения, чтобы либо доработать сгенерированный SQL, либо принять решение большинством голосов [30]. Подходы, учитывающие особенности выполнения Text-to-SQL, включают в себя обратную связь по выполнению двумя основными способами:
1) Повторное генерирование обратной связи с помощью второго раунда подсказокДля каждого SQL-запроса, сгенерированного в первом ответе, он будет выполнен в соответствующей базе данных, чтобы получить от нее ответ. Эта обратная связь может представлять собой ошибки или результаты, которые будут добавлены ко второму раунду запросов. Изучая эту обратную связь в контексте, LLM может уточнить или регенерировать исходный SQL-запрос для повышения точности.
2) Использование политики выбора на основе выполнения для сгенерированного SQLВыбираем несколько сгенерированных SQL-запросов из LLM и выполняем каждый запрос в базе данных. На основе результатов выполнения каждого SQL-запроса используется стратегия выбора (например, самосогласованность, голосование по большинству голосов [60]) для определения SQL-запроса из набора SQL, удовлетворяющего условиям, в качестве окончательного прогнозируемого SQL.
MRC-EXEC [ 67 ] предложила систему перевода с естественного языка на код (NL2Code) с выполнением, которая ранжирует каждый выбранный SQL-запрос и выбирает пример с наименьшим результатом выполнения на основе риска Байеса [111].LEVER В [68] предлагается метод проверки NL2Code путем выполнения, при котором модули генерации и выполнения собирают образцы SQL-набора и результаты его выполнения соответственно, а затем с помощью обучающего валидатора выводят вероятность корректности.
В том же духе.САМООТЛАДКА [Фреймворк также учит LLM отлаживать предсказанный SQL с помощью небольшого количества демонстраций. Модель способна исправлять ошибки без вмешательства человека, исследуя результаты выполнения и интерпретируя сгенерированный SQL на естественном языке.
Как упоминалось ранее, двухэтапная импликация широко использовалась для того, чтобы объединить хорошо разработанную структуру с обратной связью по реализации:1. выборка набора SQL-запросов. 2. голосование по большинству голосов (самосогласованное).В частности.C3[30] Фреймворк устраняет ошибки и определяет наиболее последовательный SQL;Система Retrieval Enhancement Framework [64] вводит динамические цепочки ревизий.Библиотека SQL была разработана как самокорректирующийся модуль, который сочетает в себе сообщения о выполнении с содержанием базы данных, чтобы побудить LLM преобразовать сгенерированные SQL-запросы в интерпретации на естественном языке; LLM было предложено выявить семантические пробелы и модифицировать свой собственный сгенерированный SQL. DIN-SQL [8] разработал общие и щадящие подсказки в своем модуле самокоррекции; общие подсказки требуют от LLM выявления и исправления ошибок, а щадящие подсказки требуют от модели проверки на наличие потенциальных проблем.
мультиагентная системаMAC-SQL[57] включает агент уточнения, который обнаруживает и автоматически исправляет ошибки SQL, использует классы ошибок и исключений SQLite для регенерации исправленного SQL. поскольку разные проблемы могут потребовать разного количества ревизий.SQL-CRAFT [55] В системе предусмотрена интерактивная калибровка и автоматическое управление процессом определения, чтобы избежать чрезмерной или недостаточной коррекции. FUXI В [66] рассматривается обратная связь по ошибкам в инструментальных рассуждениях для генерации SQL. Знания на SQL В [31] была представлена система обучения предпочтениям, которая сочетает в себе обратную связь по выполнению базы данных и прямую оптимизацию предпочтений [112] для улучшения предложенного DELLM.PET-SQLВ [60] предложено перекрестное согласование, которое состоит из двух вариантов: 1) обычное голосование: нескольким LLM дается указание сгенерировать SQL-запрос, а затем большинством голосов принимается окончательный вариант SQL на основе различных результатов выполнения, и 2) мелкозернистое голосование: обычное голосование уточняется на основе уровня сложности для уменьшения предвзятости голосования.
B. Тонкая настройка
Так как контролируемая тонкая настройка (SFT) является доминирующим подходом для обучения LLM [29, 91], для открытых LLM (например, LLaMA-2 [94 ], Gemma [113]) наиболее простым способом быстро адаптировать модель к конкретной области является выполнение SFT для модели с использованием собранных доменных меток. Фаза SFT обычно является начальной фазой хорошо разработанного механизма обучения [112, 114], а фаза тонкой настройки от текста к SQL. 114], а также фаза тонкой настройки преобразования текста в SQL.Процесс генерации авторегрессии для SQL-запроса Y можно сформулировать следующим образом:

Подход SFT также является фиктивным методом тонкой настройки для преобразования текста в SQL и широко применяется различными LLM с открытым исходным кодом в исследованиях преобразования текста в SQL [9, 10, 46 ]. Парадигма тонкой настройки отдает предпочтение стартовым точкам преобразования текста в SQL на основе LLM по сравнению с подходами контекстного обучения (ICL). Было опубликовано несколько исследований, посвященных поиску лучших методов тонкой настройки. Хорошо разработанные методы тонкой настройки делятся на различные группы в соответствии с их механизмами, как показано в таблице IV:
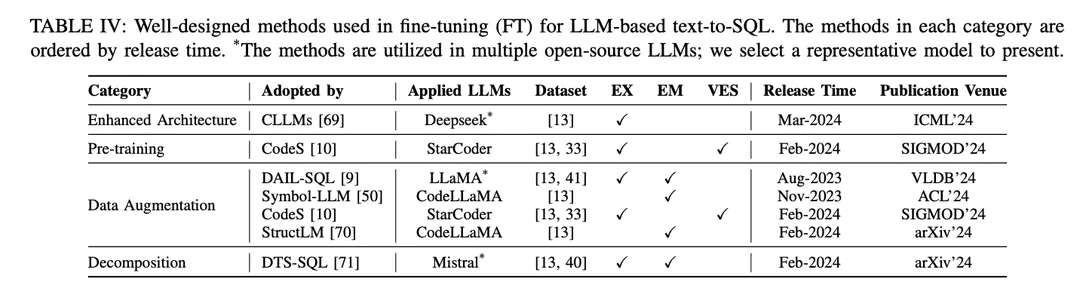
Улучшенная архитектура: Широко используемый фреймворк Generative Pretrained Transformer (GPT) использует архитектуру трансформатора, состоящего только из декодера, и традиционное авторегрессионное де-кодирование для генерации текста. Недавние исследования эффективности LLM выявили общую проблему: задержка LLM высока из-за необходимости включать механизм внимания при генерации длинных последовательностей с использованием шаблонов авторегрессии [115, 116 ]. При преобразовании текста в SQL на основе LLM генерация SQL-запросов происходит значительно медленнее, чем при традиционном моделировании языка [21, 28 ], что становится проблемой для создания эффективных локальных NLIDB. В качестве одного из решений CLLM [ 69 ] стремится решить вышеуказанные проблемы и ускорить генерацию SQL-запросов за счет усовершенствованной архитектуры модели.
Расширение данных: В процессе тонкой настройки самым непосредственным фактором, влияющим на производительность модели, является качество обучающих меток [117]. Тонкая настройка при низком качестве или отсутствии обучающих меток не имеет смысла, а тонкая настройка на высококачественных или дополненных данных всегда превосходит хорошо разработанные методы тонкой настройки на низкокачественных или необработанных данных [29, 74]. Значительный прогресс был достигнут в области тонкой настройки с помощью данных, начиная с текста и заканчивая SQL, с акцентом на улучшение качества данных в процессе SFT.
[117] "Обучение на зашумленных метках с помощью глубоких нейронных сетей: обзор".[74] Последние достижения в области преобразования текста в SQL: обзор того, что мы имеем и чего ожидаем[29] "Обзор больших языковых моделей"DAIL-SQL [9] разработан как фреймворк контекстного обучения, использующий стратегию выборки для получения лучшего количества экземпляров. Включение выборочных экземпляров в процесс SFT улучшает производительность открытого LLM.Symbol-LLM [50] предлагает инструкции по расширению данных, настроенные на фазы инжекции и инфузии.CodeS [10] улучшает обучающие данные путем двунаправленной генерации с помощью ChatGPT.StructLM [70] обучается на нескольких задачах структурных знаний для улучшения общих возможностей.
предтренировочный курс: Предварительное обучение - это фундаментальный этап всего процесса тонкой настройки, направленный на получение возможностей генерации текста путем автоматического регрессионного обучения на большом количестве данных [118]. Традиционно современные мощные собственные LLM (например, ChatGPT [119], GPT-4 [86], Claude [120]) предварительно обучаются на гибридных корпорациях, которые в основном используют диалоговые сценарии, демонстрирующие возможности генерации текста [85]. Кодоспецифичные LLM (например, CodeLLaMA [ 121 ], StarCoder [ 122 ]) предварительно обучаются на данных о коде [100 ], а смешение различных языков программирования позволяет LLM генерировать код, соответствующий инструкциям пользователя [123 ]. Основной проблемой для методов предварительного обучения, ориентированных на SQL как подзадачу генерации кода, является то, что контент, связанный с SQL/базами данных, составляет лишь небольшую часть всего корпуса, прошедшего предварительное обучение.
В результате открытые LLM с относительно ограниченными возможностями синтеза (по сравнению с ChatGPT, GPT-4) не очень хорошо понимают, как преобразовывать NL-задачи в SQL во время предварительного обучения. Фаза предварительного обучения в модели CodeS [10] состоит из трех этапов инкрементального предварительного обучения. Начиная с базового кодово-специфического LLM [122 ], CodeS выполняет инкрементное предварительное обучение на смешанном учебном корпусе (включая данные, связанные с SQL, данные, связанные с NL, и данные, связанные с NL). Значительно улучшается понимание текста на SQL и производительность.
разложение: Декомпозиция задачи на несколько шагов или использование нескольких моделей для решения задачи - это интуитивное решение для решения сложных сценариев, как показывает парадигма ICL, представленная ранее в главе IV-A. Собственные модели, используемые в подходах на основе ICL, имеют большое количество параметров, которые находятся на другом уровне параметров, чем модели с открытым исходным кодом, используемые в подходах с тонкой настройкой. Эти модели изначально способны хорошо выполнять поставленные подзадачи (благодаря таким механизмам, как обучение на меньшем количестве образцов) [30, 57]. Поэтому, чтобы повторить успех этой парадигмы в подходе ICL, важно рационально назначить соответствующие подзадачи (например, генерирование внешних знаний, связывание схем и уточнение схем) моделям с открытым исходным кодом, чтобы точно настроить их на выполнение конкретных подзадач, и построить соответствующие данные для использования в тонкой настройке, чтобы помочь в создании окончательного SQL.
DTS-SQL [71] предлагает двухэтапную декомпозиционную структуру для тонкой настройки преобразования текста в SQL и разрабатывает задачу предварительной генерации схемы (schema link 12) перед окончательной генерацией SQL.
считаться
Несмотря на значительный прогресс в исследованиях по преобразованию текста в SQL, все еще существуют некоторые проблемы, которые необходимо решить. В этом разделе обсуждаются оставшиеся проблемы, которые, как ожидается, будут преодолены в будущей работе.
А. Устойчивость в практических приложениях
Преобразование текста в SQL, реализованное с помощью LLM, обещает быть универсальным и надежным в реальных сложных сценариях применения. Несмотря на недавний значительный прогресс в создании наборов данных, специфичных для робастности [ 37 , 41], их производительность все еще недостаточна для реальных приложений [ 33]. В будущих исследованиях еще предстоит решить некоторые проблемы. Со стороны пользователя существует такое явление, как то, что пользователь не всегда явно задает вопрос, а это значит, что его вопрос может не иметь точных значений в базе данных или отличаться от стандартного набора данных, в который могут быть включены синонимы, опечатки и нечеткие выражения [40].
Например, в парадигме тонкой настройки модель обучается на явно индикативных проблемах с конкретными представлениями. Поскольку модель не обучается отображению проблем реального мира на соответствующие базы данных, при применении к реальным сценариям возникает пробел в знаниях [33]. Как показано в соответствующих оценках на наборах данных с синонимами и неполными инструкциями [7 , 51], SQL-запросы, сгенерированные ChatGPT, содержат около 40% неправильных выполнений, что на 10% меньше, чем в оригинальной оценке [51]. В то же время тонкая настройка с использованием исходного текста для SQL-данных может содержать нестандартизированные образцы и метки. Например, названия таблиц или столбцов не всегда точно отражают их содержимое, что приводит к несоответствиям при построении обучающих данных.
B. Вычислительная эффективность
Вычислительная эффективность определяется скоростью рассуждений и стоимостью вычислительных ресурсов, что стоит учитывать как в приложениях, так и в исследовательских работах [49, 69]. С увеличением сложности баз данных в последних бенчмарках text-to-SQL [15, 33], базы данных будут содержать больше информации (включая больше таблиц и столбцов) и соответственно увеличится длина схемы базы данных, что создаст ряд проблем. При работе со сверхсложными базами данных использование соответствующей схемы в качестве входных данных может столкнуться с тем, что стоимость обращения к собственным LLM значительно возрастет, потенциально превышая максимальную длину лексем модели, особенно при реализации моделей с открытым исходным кодом и малой длиной контекста.
Другая очевидная проблема заключается в том, что в большинстве исследований в качестве исходных данных для модели используются полные паттерны, что приводит к появлению большого количества избыточности [57]. Предоставление LLM точных отфильтрованных паттернов, относящихся к проблеме, непосредственно со стороны пользователя для снижения затрат и избыточности является потенциальным решением для повышения эффективности вычислений [30]. Разработка точного метода фильтрации паттернов остается перспективным направлением. Хотя парадигма контекстного обучения достигла многообещающей точности, хорошо продуманные многоступенчатые фреймворки или расширенные контекстные методы увеличивают количество вызовов API, что улучшает производительность с точки зрения вычислительной эффективности, но также приводит к значительному увеличению стоимости [8].
В смежных подходах [49] необходимо тщательно учитывать компромисс между производительностью и вычислительной эффективностью, и разработка сопоставимого (или даже лучшего) подхода к контекстному обучению с меньшей стоимостью интерфейса прикладного программирования была бы практической реализацией, которая все еще находится в стадии изучения. По сравнению с подходами, основанными на PLM, подходы, основанные на LLM, работают значительно медленнее [ 21, 28]. Ускорение процесса рассуждений за счет сокращения длины входных данных и уменьшения количества этапов в процессе реализации интуитивно понятно для парадигмы контекстного обучения. Для локального LLM, начиная с исходной точки [69], можно исследовать больше стратегий ускорения, чтобы улучшить архитектуру модели в будущих исследованиях.
Для решения этой проблемы необходимо скорректировать LLM с учетом преднамеренного смещения и разработать стратегии обучения для шумных сценариев. Между тем, объем данных в реальных приложениях относительно меньше, чем в эталонных исследованиях. Поскольку масштабирование большого количества данных путем ручного аннотирования требует больших трудозатрат, разработка методов расширения данных для получения большего количества пар вопрос-SQL обеспечит поддержку LLM в условиях нехватки данных. Кроме того, потенциально полезной является тонкая настройка LLM с открытым исходным кодом для локальных исследований адаптации на небольших наборах данных. Кроме того, в будущих исследованиях следует всесторонне изучить расширения для многоязычных [ 42 , 124 ] и мультимодальных сценариев [ 125 ], что принесет пользу большему числу лингвистических сообществ и поможет создать более общие интерфейсы баз данных.
C. Конфиденциальность и интерпретируемость данных
Как часть исследования LLM, основанный на LLM text-to-SQL также сталкивается с некоторыми общими проблемами, которые существуют в исследованиях LLM [4 , 126 , 127 ]. С точки зрения text-to-SQL, эти проблемы также ведут к потенциальным улучшениям, которые могут принести большую пользу исследованиям LLM. Как уже упоминалось в главе IV-A, парадигмы контекстного обучения доминируют в последних исследованиях как по объему, так и по производительности, причем в большинстве работ используются собственные модели [8, 9]. Сразу же возникает проблема конфиденциальности данных, поскольку использование проприетарных API для обеспечения конфиденциальности локальных баз данных может представлять риск утечки данных. Использование парадигм локальной тонкой настройки может частично решить эту проблему.
Тем не менее, производительность ванильной тонкой настройки в настоящее время является неоптимальной [9], а продвинутые механизмы тонкой настройки могут полагаться на собственные LLM для расширения данных [10]. Исходя из текущего положения дел, более адаптированные фреймворки в парадигме локальной тонкой настройки текста на SQL заслуживают пристального внимания. В целом, развитие глубокого обучения всегда сталкивалось с проблемами интерпретируемости [127, 128 ].
Как давняя проблема, для ее решения было проведено множество исследований [ 129 , 130 ]. Однако интерпретируемость реализаций на основе LLM остается нерассмотренной в исследованиях по преобразованию текста в SQL, как в парадигме контекстного обучения, так и в парадигме тонкой настройки. Подходы с этапами декомпозиции объясняют реализацию text-to-SQL с точки зрения пошаговой генерации [8, 51]. В перспективе - включение передовых исследований в области интерпретируемости [131, 132] для повышения производительности преобразования текста в SQL, а также объяснение локальных архитектур моделей с точки зрения знаний о базе данных.
D. Расширение
Как подполе исследований в области LLM и понимания естественного языка, большая часть исследований в этих областях была подкреплена использованием задач преобразования текста в SQL [103 , 110 ]. Однако исследования в области преобразования текста в SQL можно распространить и на более широкие исследования в этих областях. Например, генерация SQL является частью генерации кода. Хорошо разработанные методы генерации кода также могут достигать высокой производительности при преобразовании текста в SQL [48, 68] и могут быть обобщены на широкий спектр языков программирования. Также можно обсудить возможность расширения некоторых специализированных фреймворков text-to-SQL на исследования NL-to-code.
Например, фреймворки, интегрирующие вывод результатов выполнения в NL-to-code, также достигают отличной производительности при генерации SQL [8]. Попытки распространить подход, учитывающий особенности выполнения в text-to-SQL, с помощью других модулей продвижения [30, 31] на генерацию кода заслуживают обсуждения. С другой стороны, ранее обсуждалось, что преобразование текста в SQL может улучшить ответы на вопросы (QA) на основе LLM за счет предоставления фактической информации. Базы данных могут хранить реляционные знания в виде структурной информации, и структурные QA потенциально могут выиграть от преобразования текста в SQL (например, ответы на вопросы на основе знаний, KBQA [ 133 , 134 ]). Использование структур баз данных для построения фактических знаний и их последующее объединение с системой преобразования текста в SQL для обеспечения поиска информации может помочь в дальнейшем QA в получении более точных фактических знаний [ 135 ]. Ожидается, что в дальнейшей работе будут проведены более широкие исследования преобразования текста в SQL.
Представление продукта OlaChat Digital Intelligence Assistant

OlaChat Digital Intelligence Assistant - это новый интеллектуальный продукт для анализа данных, созданный департаментом платформы больших данных PCG компании Tencent на основе использования больших моделей в области анализа данных в практике посадки, и интегрированный в DataTalk, OlaIDE и другие внутренние платформы данных Tencent, чтобы обеспечить интеллектуальную поддержку всего процесса анализа данных. Он содержит ряд возможностей, таких как text2sql, анализ показателей, интеллектуальная оптимизация SQL и т.д. От анализа данных (drag-and-drop анализ, SQL-запрос), визуализации данных, до интерпретации и атрибуции результатов, OlaChat всесторонне помогает сделать работу по анализу данных проще и эффективнее!
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...