
Статья объемом 10 000 слов об оптимизации RAG в реальных сценариях DB-GPT.

предисловие
За последние два года технология Retrieval-Augmented Generation (RAG, "поиск-дополнение-генерация") постепенно стала одним из основных компонентов расширенного интеллекта. Объединяя двойные возможности поиска и генерации, RAG способна внедрять внешние знания, тем самым предоставляя больше возможностей для применения больших моделей в сложных сценариях. Однако в практических сценариях посадки часто возникают проблемы низкой точности извлечения, шумовых помех, целостности запоминания и недостаточного профессионализма, что приводит к серьезным иллюзиям LLM. В этой статье мы сосредоточимся на деталях обработки знаний и извлечения информации из RAG в реальных сценариях посадки, а также на том, как оптимизировать связь RAG с Pineline, чтобы в конечном итоге повысить точность запоминания.
Быстро создать приложение RAG smart Q&A несложно, но его использование в реальных бизнес-сценариях требует серьезной подготовки.
1.RAG Интерпретация кода источника ключевого процесса
центробработка знанийответить пениемRAGНекоторые из ключевых процессов:
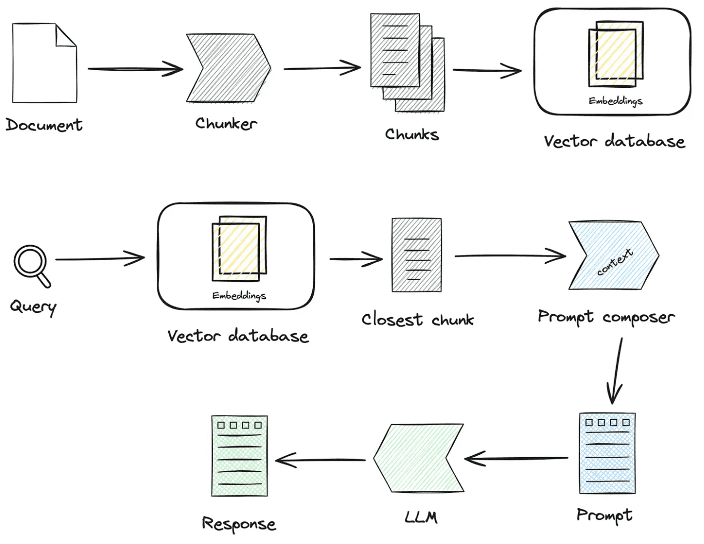
1. обработка знаний
Загрузка знаний -> Нарезка знаний -> Извлечение информации -> Обработка знаний (встраивание/граф/ключевые слова) -> Хранение знаний
- Загрузка знаний
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
Как расширить:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- срез знаний
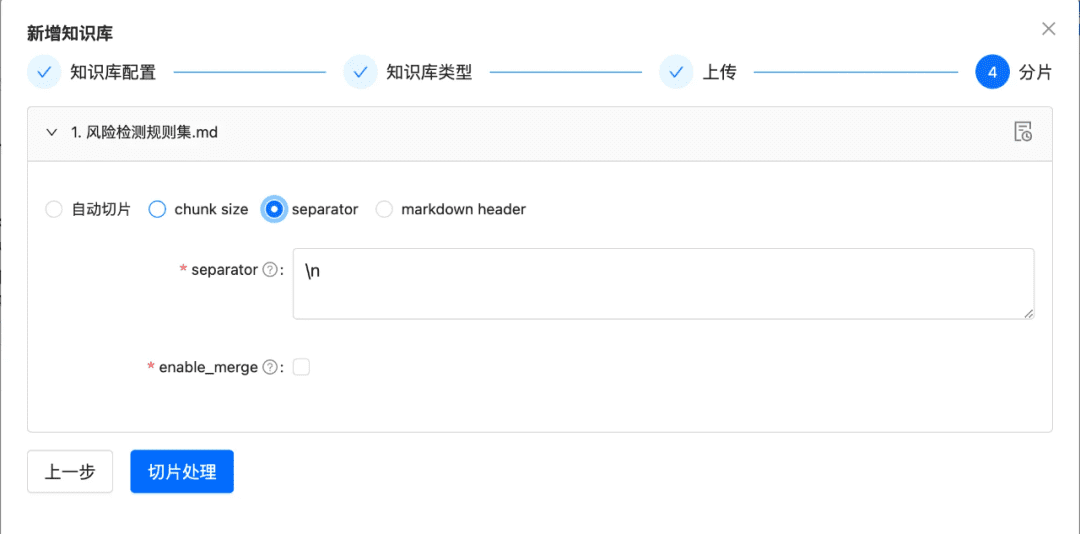
ChunkManager: через загруженные данные знаний они направляются в соответствующий процессор чанков для распределения в соответствии с заданной пользователем политикой чанкинга и параметрами чанкинга.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
Как расширить: если вы хотите настроить новую стратегию нарезки в интерфейсе
- Новая стратегия нарезки
- Новая логика реализации сплиттера
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Извлечение знаний
- Извлечение вектора -> встраивание, реализация
Embeddingsразъем
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Извлечение графа знаний -> граф знаний
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Извлечение обратного индекса -> сегментация ключевых слов
- Вы можете использовать лексикон es по умолчанию или настроить лексикон с помощью режима плагина es.
- Извлечение обратного индекса -> сегментация ключевых слов
- Хранение знаний
Все знания сохраняются равномерноIndexStoreBaseинтерфейс, в настоящее время предоставляет три типа реализаций: векторные базы данных, графовые базы данных, полнотекстовое индексирование

- VectorStore, основная логика векторной базы данных находится в load_document(), включая создание схемы индекса, пакетную запись векторных данных и так далее.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore, конкретное хранилище графов, обеспечивает реализацию троичной записи, которая обычно выполняется путем вызова языка запросов конкретной базы данных графов. Например
TuGraphStoreНа основе троичного оператора будет сгенерирован и выполнен определенный оператор Cypher.
- Интерфейс хранения графов GraphStoreBase обеспечивает единую абстракцию для хранения графов и в настоящее время имеет встроенные
MemoryGraphStoreответить пениемTuGraphStoreреализации, мы также предоставляем разработчикам интерфейс Neo4j для доступа.
- Интерфейс хранения графов GraphStoreBase обеспечивает единую абстракцию для хранения графов и в настоящее время имеет встроенные
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: построение индекса es, использование встроенного алгоритма разбиения слов es для разбиения слов, а затем построение инвертированного индекса keyword->doc_id с помощью es.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. поиск знаний
вопрос -> переписывание -> поиск по сходству -> ранжирование -> контекст_кандидатов
Далее следует поиск знаний, текущая логика поиска сообществ в основном делится на следующие шаги, если вы установите параметры переписывания запроса, в настоящее время даст вам раунд переписывания вопроса через большую модель, а затем он будет направлен на соответствующий ретривер в соответствии с вашим способом обработки знаний, если вы обрабатываете через векторы, он будет извлечен через EmbeddingRetriever, если вы строите способ построен через граф знаний, он будет получен в соответствии с графом знаний, если вы установите модель ранжирования, она предоставит значения кандидатов после грубого отбора в тонкий отбор, чтобы сделать значения кандидатов более релевантными вопросу пользователя.
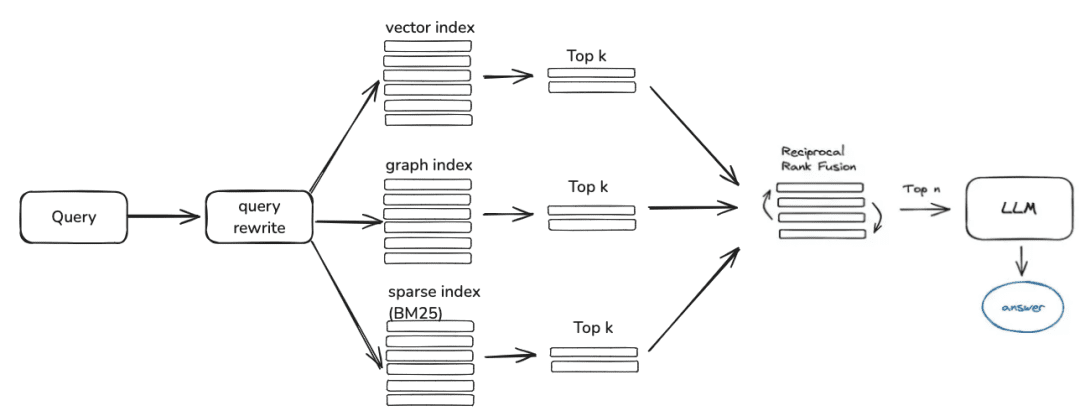
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: специальная база данных векторов
- top_k: количество возвращенных чанков-кандидатов.
- query_rewrite: функция перезаписи запросов
- rerank: функция переупорядочивания
- запрос:Оригинальный запрос
- score_threshold: оценка, по умолчанию мы отфильтровываем контексты с оценкой сходства меньше порога
- фильтры:
Optional[MetadataFilters]Фильтр информации метаданных, в основном, может быть использован для фронтальной проверки информации атрибутов, отсеивая некоторые несоответствия информации кандидатов.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- График RAG
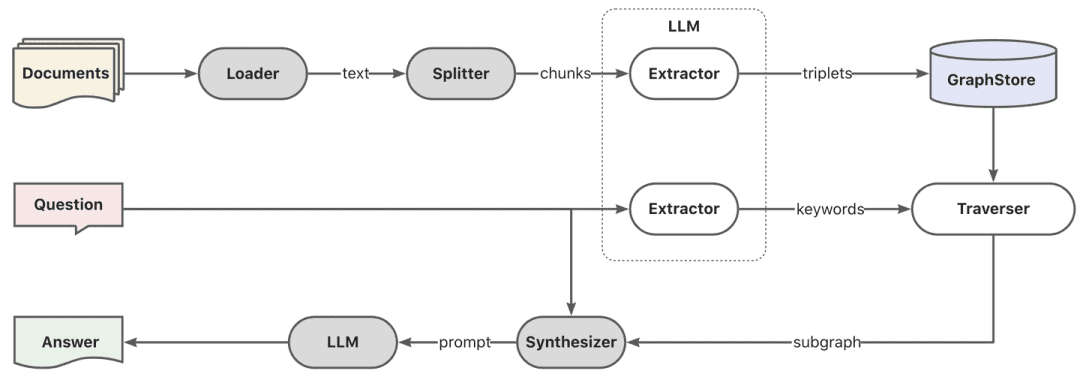
Во-первых, извлечение ключевых слов осуществляется с помощью модели, здесь может быть использована традиционная техника nlp для разбиения слов или большая модель для разбиения слов, затем ключевые слова приводятся в соответствие с синонимами для расширения, чтобы найти список кандидатов на ключевые слова, и лучше вызвать метод explore, чтобы вспомнить локальные подграфы в соответствии со списком кандидатов на ключевые слова.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverЭто частично поиск схемных связей для сценариев ChatData.В основном через схему-связку путем двухэтапного поиска по сходству, сначала находим наиболее релевантную таблицу, затем наиболее релевантную информацию о поле.
Плюсы: этот двухэтапный поиск также разработан с учетом отзывов сообщества об опыте работы с большими широкими столами.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- Коннектор table_vector_store_connector: отвечает за поиск наиболее релевантной таблицы.
- field_vector_store_connector: отвечает за извлечение наиболее релевантных полей.
2. идеи оптимизации обработки знаний, поиска знаний
В настоящее время приложения RAG smart quiz имеют несколько болевых точек:
- После того как в базу знаний попадает все больше и больше документов, поиск становится шумным, а точность запоминания невысокой
- Неполные отзывы и отсутствие полноты
- Отзывы и намерение задать вопрос пользователю имеют малое значение
- Возможность отвечать только на статические данные и отсутствие динамического доступа к знаниям приводит к тому, что приложение для ответов становится скучным и тупым.
1. Оптимизация обработки знаний
Обработка неструктурированных/полуструктурированных/структурированных данных готова определить верхний предел применения RAG, поэтому в первую очередь необходимо проделать много тонкой ETL-работы на этапе обработки знаний, индексирования, основной оптимизации направления идеи:
- Неструктурированные -> Структурированные: организация информации о знаниях в структурированном виде.
- Извлечение более богатой и разнообразной семантической информации.
1.1 Загрузка знаний
Цель: Точный синтаксический анализ документов необходим для более разносторонней идентификации различных типов данных.
Рекомендации по оптимизации:
- Рекомендуется обрабатывать текст в формате docx, txt или других форматах, чтобы можно было использовать некоторые инструменты распознавания для лучшего извлечения содержимого текста.
- Извлечение информации о таблице из текста.
- Сохраните информацию об иерархии заголовков в формате markdown и pdf для подготовки следующего дерева иерархических отношений и других методов индексирования.
- Сохраняйте ссылки на изображения, формулы и другую информацию, также единообразно обработанную в формате markdown.
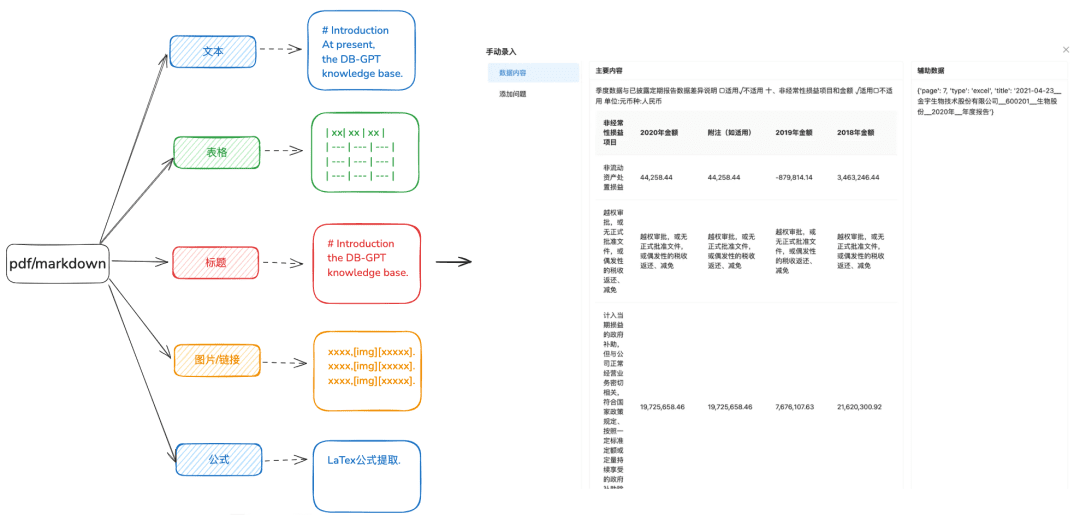
1.2 Нарежьте чанк как можно более целым
Цель: сохранить целостность и релевантность контекста, что напрямую связано с точностью ответа.
Оставаясь в рамках контекстуальных ограничений более крупной модели, разбиение на части гарантирует, что текст, вводимый в LLM, не превысит предельного количества лексем.
Рекомендации по оптимизации:
- Изображения + таблицы извлекаются как отдельные фрагменты, сохраняя подписи к таблицам и изображениям в метаданных
- Содержимое документа разбивается по возможности в соответствии с иерархией заголовков или Markdown Header, максимально сохраняя целостность фрагмента.
- Если есть пользовательский разделитель, вы можете нарезать по нему.
1.3 Диверсифицированное извлечение информации
Помимо извлечения вектора Embedding из документов, извлечение другой разнообразной информации может расширить данные о документах и значительно улучшить эффект RAG recall.
- карта знаний
- Преимущества: 1. Решение проблемы неполноты NativeRAG, все еще существует проблема иллюзии, а точность знаний, включая полноту границ знаний, ясность структуры и семантики знаний, является семантическим дополнением к способности поиска по сходству.
- Сценарии: Для строгих профессиональных областей (здравоохранение, O&M и т.д.), где подготовка знаний должна быть ограничена и где могут быть четко установлены иерархические отношения между знаниями.
- Как достичь:
1. зависимость от большой модели для извлечения троичных отношений (сущность, отношения, сущность).
2. опираться на предварительное качество, структурированную подготовку знаний, их очистку, извлечение, использование бизнес-правил с помощью ручного или пользовательского процесса SOP для построения графа знаний.
- Док Три
- Применимые сценарии: решает проблему недостаточной целостности контекста, а также обеспечивает соответствие исключительно на основе семантики и ключевых слов и может снизить уровень шума
- Способ достижения: постройте дерево узлов на уровне заголовка, чтобы сформировать многочленную древовидную структуру, где каждый узел уровня должен хранить только заголовок документа, а узлы листьев - конкретное текстовое содержимое. Таким образом, используя алгоритм обхода дерева, если вопрос пользователя попадает на релевантный узел заголовка, не являющийся листом, можно вызвать данные соответствующего дочернего узла. Таким образом, не возникает проблем с нарушением целостности кусков.
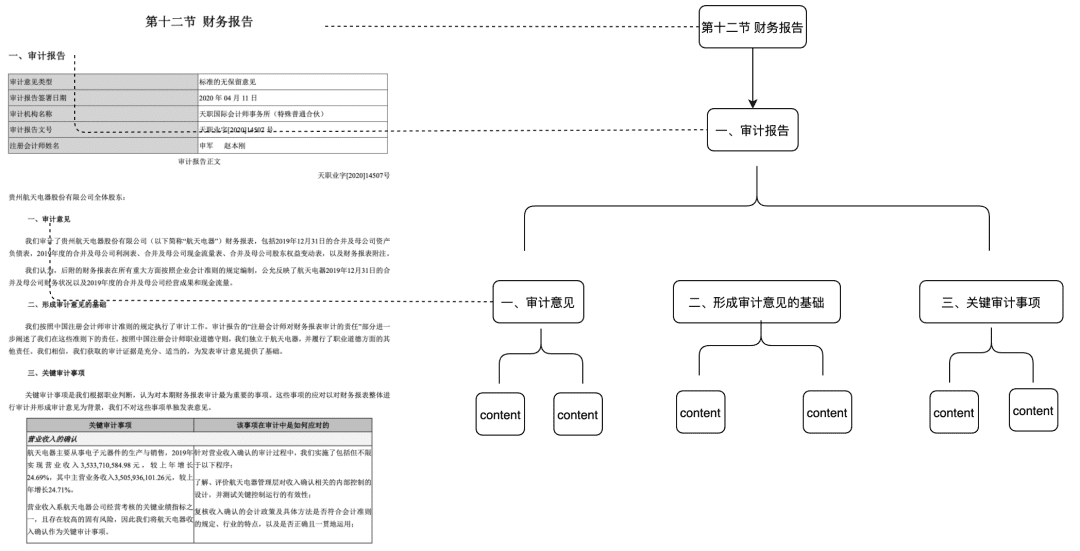
Эту часть Feature мы также выложим в сообщество в начале следующего года.
- Извлечение пар QA требует предварительного извлечения информации о парах QA с помощью предопределенных или модельных методов извлечения
- Применимые сценарии:
- Способность попасть в вопрос при поиске и прямом вызове, непосредственно получить ответ, который хочет пользователь, применима к некоторым сценариям FAQ, целостность отзыва не является достаточным сценарием.
- Как достичь:
- Предустановленные: заранее добавьте несколько вопросов для каждого блока.
- Извлечение модели: учитывая контекст, позвольте модели выполнить извлечение пары QA.
- Извлечение метаданных
- Как достичь: В соответствии с характеристиками собственных бизнес-данных, извлеките характеристики данных для хранения, такие как теги, категории, время, версия и другие атрибуты метаданных.
- Применимые сценарии: поиск может быть предварительно отфильтрован на основе атрибутов метаданных, чтобы отсеять большую часть шума.
- Обобщение и извлечение
- Применимые сценарии: разрешение
这篇文章讲了个啥(математика) род总结一下и другие сценарии глобальных проблем. - Как реализовать: сегментированное извлечение с помощью mapreduce и т. д., извлечение суммарной информации для каждого фрагмента с помощью модели.
- Применимые сценарии: разрешение
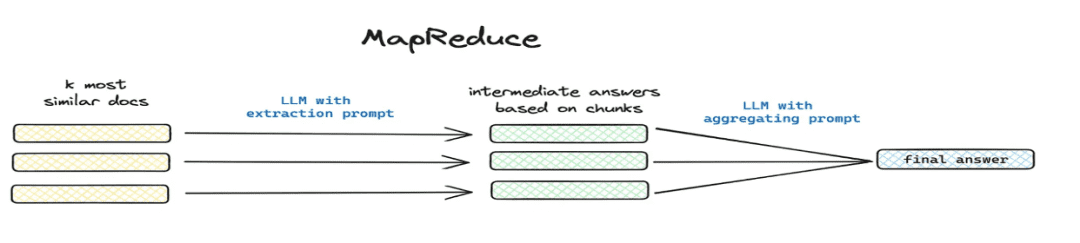
1.4 Рабочий процесс обработки знаний
в настоящее время DB-GPT База знаний предоставляет возможности обработки знаний, такие как загрузка документов -> синтаксический анализ -> нарезка -> встраивание -> извлечение триады графа знаний -> хранение векторной базы данных -> хранение базы графов и т.д., но она не имеет возможности извлекать сложную и персонализированную информацию из документов, поэтому есть надежда, что путем построения шаблона рабочего процесса обработки знаний можно завершить сложные, визуальные, определяемые пользователем процессы извлечения, преобразования и обработки знаний. Поэтому мы надеемся создать шаблон рабочего процесса обработки знаний для завершения сложного, визуального, определяемого пользователем процесса извлечения, преобразования и обработки знаний.
Рабочий процесс обработки знаний:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. оптимизация процесса RAG оптимизация процесса RAG мы подразделяемся на статический документ RAG и динамические данные сбора RAG, большинство текущих RAG участвует только охватывает неструктурированный документ статических активов, но фактический бизнес многих сценариев вопросов и ответов является через инструмент, чтобы получить динамические данные + статические данные знаний вместе, чтобы ответить на сценарий, не только нужно получить статические знания, но и должны быть RAG получить информацию об инструментах в библиотеке инструментальных активов и выполнить приобретение динамических данных.
2.1 Оптимизация RAG на основе статических знаний
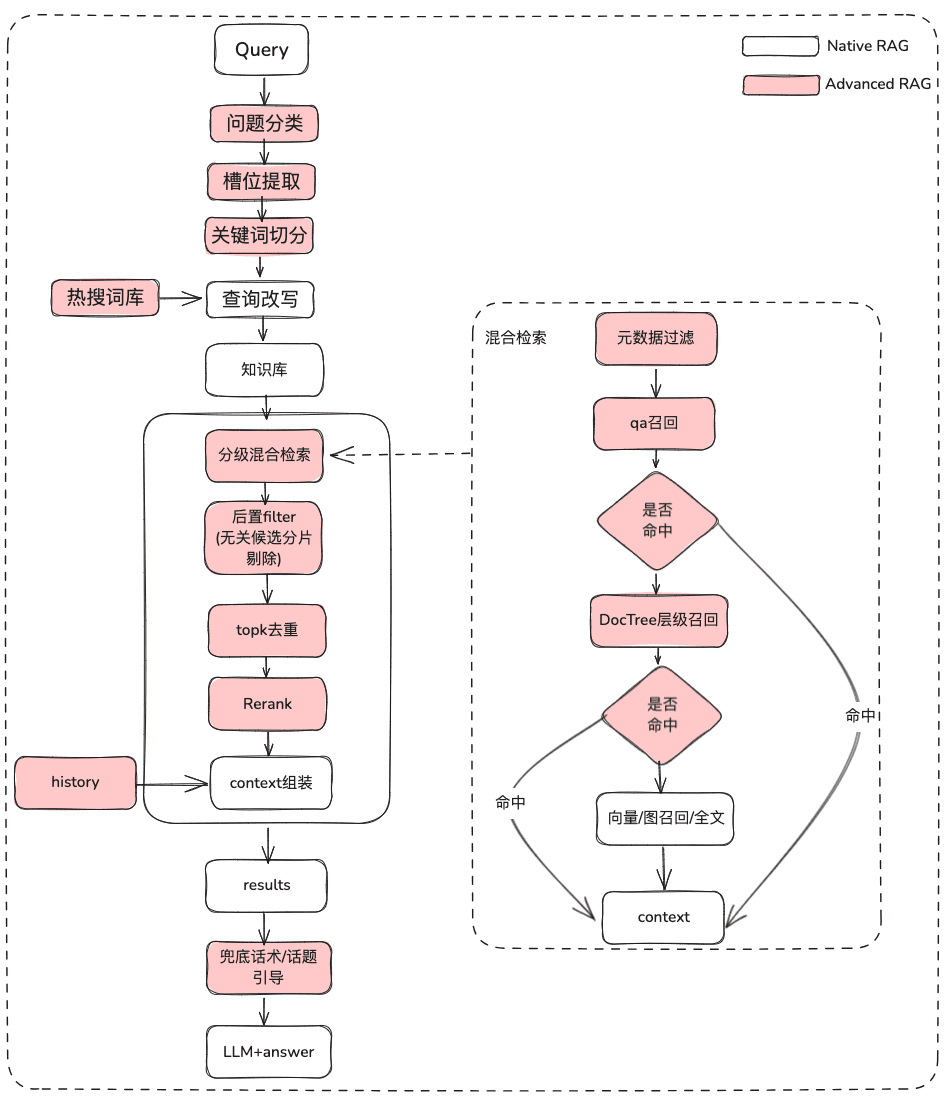
(1) Лечение исходной проблемы
Цель: прояснить семантику пользователя и оптимизировать его первоначальный вопрос, превратив его из нечеткого, плохо сформулированного запроса в более богатый по смыслу запрос.
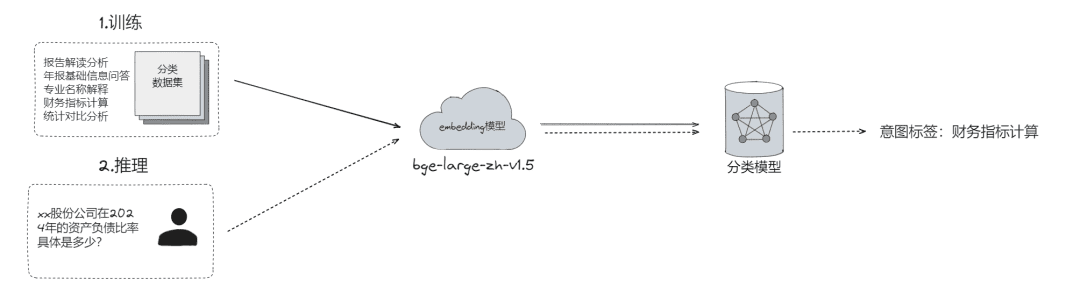
- Сырая классификация проблем, с помощью которой проблемы могут быть
- Классификация LLM (
LLMExtractor) - Построение вкрапления + логистической регрессии для реализации двухбашенной модели, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- Классификация LLM (
- совет: Необходимо высокое качество модели встраивания, рекомендуем bge-v1.5-large
- Переспросите пользователя, и если семантика не ясна, верните вопрос обратно пользователю для уточнения, через несколько раундов взаимодействия.
- Предлагает пользователю короткий список вопросов на основе семантической релевантности с использованием поискового тезауруса.
- Извлечение слотов, целью которого является получение ключевой информации о слотах в вопросе пользователя, такой как намерение, бизнес-атрибуты и т.д.
- Добыча LLM (
LLMExtractor)
- Добыча LLM (
- Переформулируйте вопрос
- Пересмотр тезауруса горячего поиска
- многоуровневое взаимодействие
(2) Фильтрация метаданных
Когда мы делим индекс на множество фрагментов, хранящихся в одном пространстве знаний, эффективность поиска становится проблемой. Например, когда пользователи запрашивают информацию о "Zhejiang I Wu Technology Company", они не хотят вспоминать информацию о других компаниях. Поэтому, если вы можете сначала отфильтровать информацию по атрибуту метаданных "название компании", это значительно повысит эффективность и релевантность.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
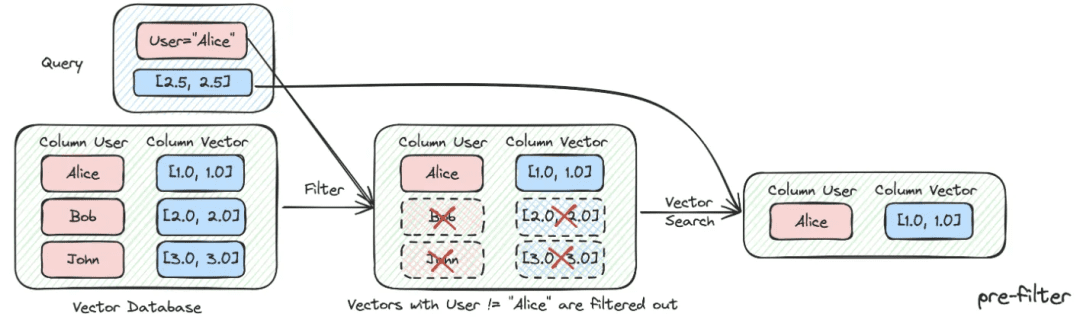
(3) Гибридный отзыв с несколькими стратегиями
- Определите приоритеты для различных ретриверов в зависимости от приоритета отзыва и возвращайте контент сразу после его получения
- Определите различные извлечения, такие как qa_retriever, doc_tree_retriever, которые будут записываться в очередь, и добейтесь приоритетного извлечения благодаря свойству очереди "первым пришел - первым ушел".
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- Многозначное индексирование/пространственное параллельное запоминание
- Полнота запоминания обеспечивается за счет получения списков кандидатов путем параллельного запоминания с помощью различных форм индексирования знаний
(4) Постфильтрация
Пройдя через список кандидатов для грубого отбора, как отфильтровать шум через тонкий отбор?
- Отсеивание нерелевантных кандидатов
- Отказ от своевременности
- Атрибуты бизнеса не удовлетворяют требованиям отбора
- дедупликация топиков
- Переупорядочивание Недостаточно полагаться на отзыв грубого отбора, в это время нам нужно иметь некоторые стратегии для переупорядочивания полученных результатов, например, для корректировки таких факторов, как релевантность комбинации, соответствие и так далее, чтобы получить упорядочивание, более соответствующее нашим бизнес-сценариям. Ведь после этого шага мы отправим результаты в LLM для окончательной обработки, поэтому результаты этой части очень важны.
- Тонкий отбор с использованием релевантных моделей переупорядочивания, либо моделей с открытым исходным кодом, либо моделей с тонкой настройкой бизнес-семантики.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- Взвешенная по RRF композитная оценка бизнеса, основанная на различных индексированных отзывах
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) Оптимизация показов + таутинг / лидерство по темам
- Получение модели для вывода с использованием форматирования в формате markdown
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Динамическая оптимизация RAG
Документальные знания относительно статичны, не могут отвечать на персонализированную и динамическую информацию, необходимо полагаться на некоторые инструменты сторонних платформ для ответа, исходя из этой ситуации, нам нужны некоторые динамические методы RAG, через определение актива инструмента -> выбор инструмента -> проверка инструмента -> выполнение инструмента для получения динамических данных.
(1) Библиотека инструментальных средств
Создайте библиотеку инструментальных активов домена предприятия, чтобы интегрировать API-интерфейсы инструментов, скрипты инструментов, разбросанные по различным платформам, и таким образом обеспечить сквозные возможности использования интеллекта. Например, в дополнение к статической базе знаний мы можем обрабатывать инструменты, импортируя библиотеку инструментов.

(2) Отзыв инструментов
Вспоминание инструментов соответствует идее вспоминания RAG для статических знаний, а затем полный жизненный цикл выполнения инструмента используется для получения результатов выполнения инструмента.
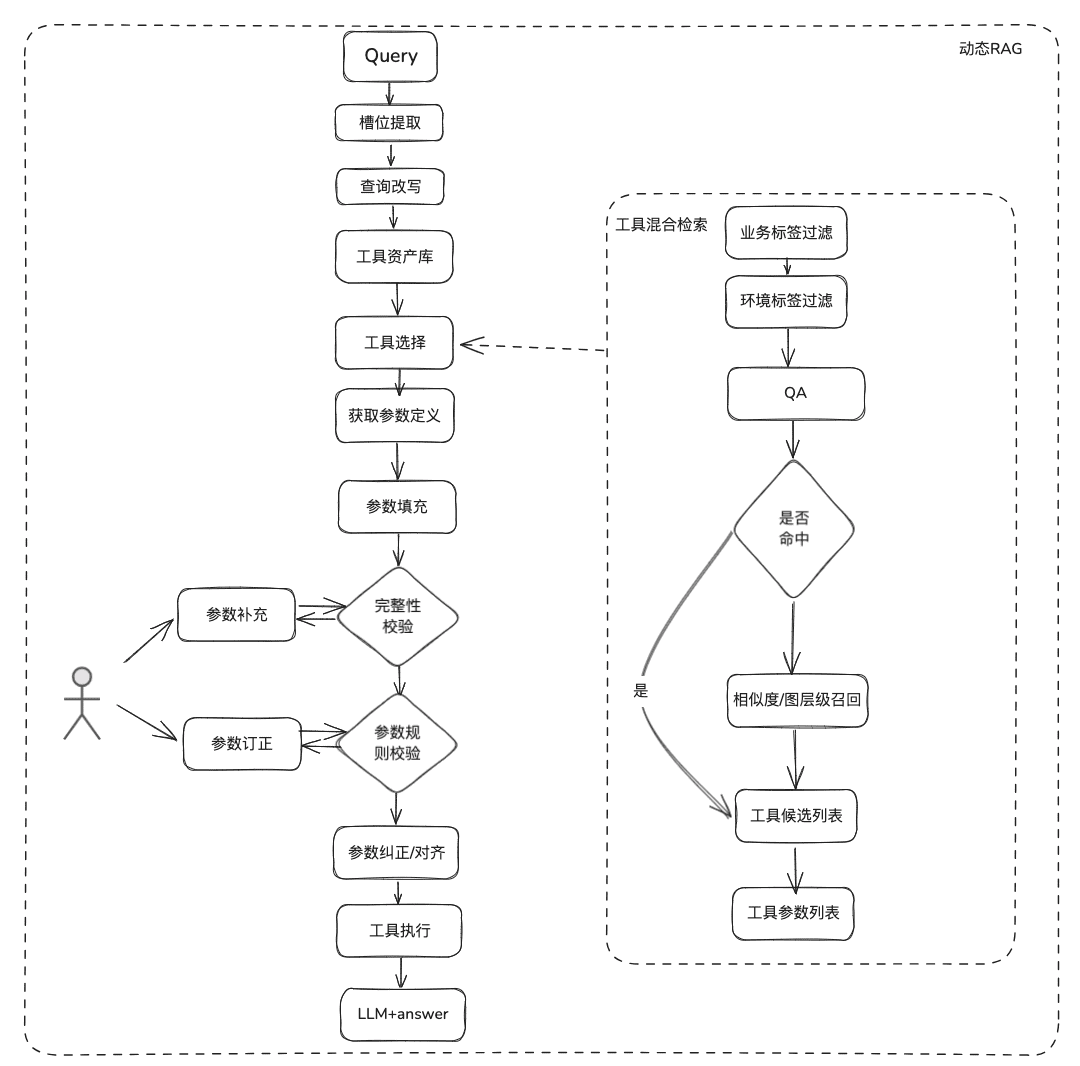
- Извлечение слотов: Получение LLM с помощью традиционного nlp для разбора проблемы пользователя, включая общие типы бизнеса, маркеры среды, параметры доменной модели и т. д.
- Выбор инструмента: вызов по принципу статического RAG с двумя основными уровнями: вызов названия инструмента и вызов параметров инструмента.
- Вызов параметров инструмента, аналогичный идее TableRAG, сначала вызывает имя таблицы, а затем имя поля.
- Заполнение параметров: необходимо сопоставить параметры, извлеченные из пазов, с определениями параметров инструмента в отзывах
- Вы можете заполнить его кодом, а можете попросить модель заполнить его.
- Идеи оптимизации: Поскольку названия одних и тех же параметров в различных инструментах платформы не унифицированы, а обращаться к руководству неудобно, предлагается сначала провести раунд расширения данных доменной модели, а после получения всей доменной модели необходимые параметры будут присутствовать.
- калибровка параметров
- Проверка целостности: выполняет проверку целостности по количеству параметров
- Проверка правил параметров: выполняет проверку правил для типа имени параметра, значения параметра, перечисления и так далее.
- Корректировка/выравнивание параметров, эта часть в основном предназначена для сокращения количества взаимодействий с пользователем, автоматического завершения исправления ошибок параметров пользователя, включая правила регистров, правила перечисления и т.д. Например.
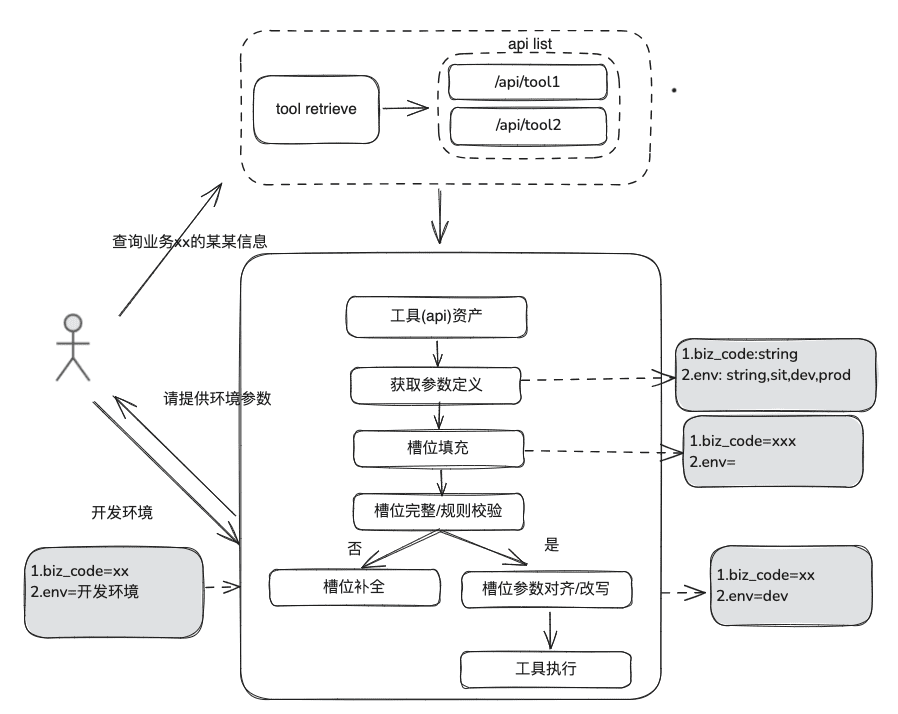
2.3 Обзор RAG
При оценке процесса Smart Q&A необходимо отдельно оценить точность запоминания и релевантность модели вопросов и ответов, а затем рассмотреть их вместе, чтобы определить, где процесс RAG еще нуждается в улучшении.
Оценка показателей:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetric:: Коэффициент попадания измеряет RAGretrieverДоля отзывов, встречающихся в топ-к документах найденных результатов.RetrieverMRRMetric:Mean Reciprocal RankТочность каждого запроса рассчитывается путем анализа ранжирования наиболее релевантных документов в результатах поиска. Точнее, это среднее значение обратного ранга релевантных документов для всех запросов. Например, если наиболее релевантный документ занимает первое место, его обратный ранг равен 1, если второе - 1/2 и так далее.RetrieverSimilarityMetricМетрики сходства вычисляются для определения сходства между вспомненным контентом и предсказанным контентом.
模型生成Индикатор ответа.
AnswerRelevancyMetric:: Метрика релевантности ответа интеллектуального тела, определяющая, насколько хорошо ответ интеллектуального тела соответствует вопросу пользователя. Высокая релевантность ответа требует от модели не только понимания вопроса пользователя, но и генерации ответа, тесно связанного с вопросом. Это напрямую влияет на удовлетворенность пользователей и полезность модели.
3.RAG Landing Case Sharing
1. RAG в области инфраструктуры данных
1.1 Справочная информация об органах разведки и управления
В сфере инфраструктуры данных есть много Ops SRE, которые ежедневно получают большое количество оповещений, поэтому много времени уходит на реагирование на аварийные ситуации, что, в свою очередь, приводит к устранению неполадок, а затем к анализу неполадок, что, в свою очередь, приводит к накоплению опыта. Еще одна часть времени уходит на ответы на запросы пользователей, требуя от них отвечать на вопросы, опираясь на свои знания и опыт использования инструментов.
Поэтому мы надеемся решить эти проблемы диагностики тревог и ответов на вопросы путем создания общего интеллекта для инфраструктуры данных.
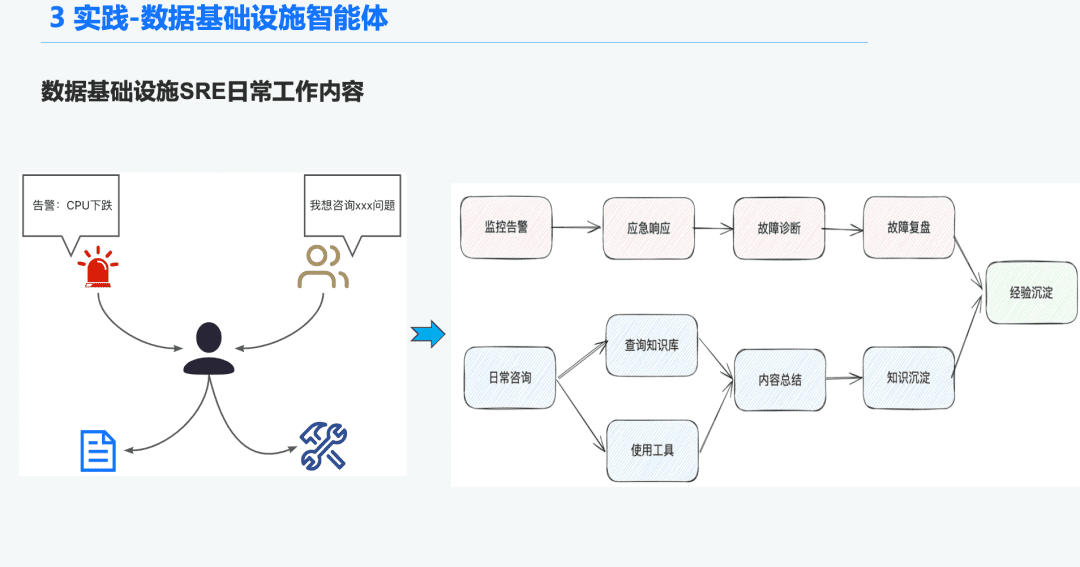
1.2 Строгий и профессиональный RAG
Традиционная технология RAG + Agent позволяет решать одношаговые задачи общего назначения, менее детерминированные. Однако при решении профессиональных сценариев в области инфраструктуры данных весь процесс поиска должен быть детерминированным, профессиональным и реалистичным, требующим пошагового рассуждения.
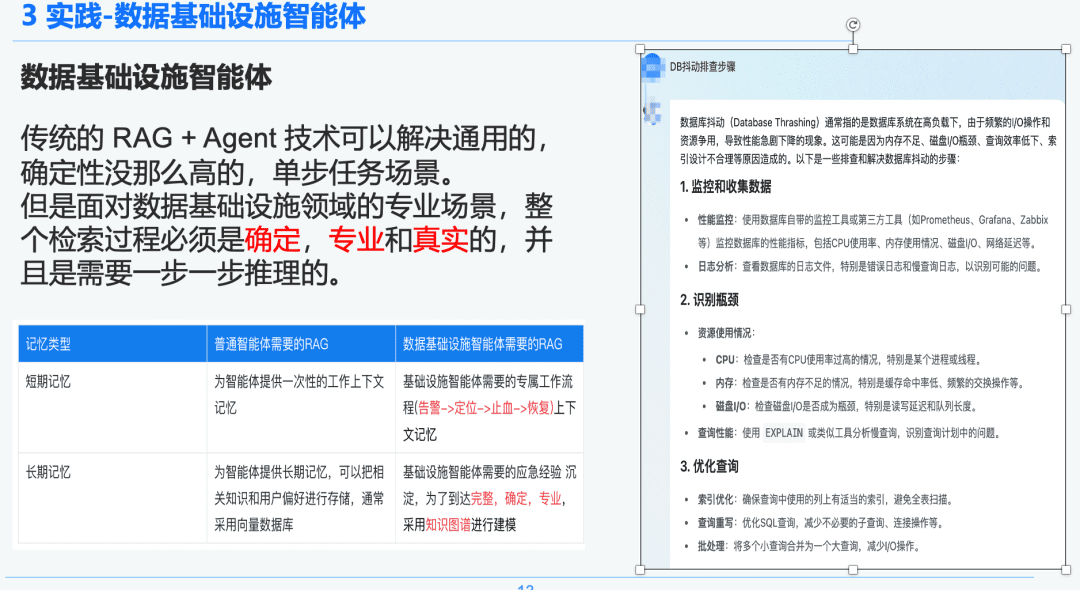
Справа - обобщенная информация с помощью NativeRAG, которая может быть полезной для руководителя высшего звена, не обладающего столь обширными знаниями в этой области, а для профессионала эта часть ответа не будет иметь особого смысла.
Поэтому мы сравниваем разницу между общими интеллектами и интеллектами инфраструктуры данных по RAG:
- Интеллекты общего назначения: традиционные RAG не требуют столь глубоких интеллектуальных знаний и опыта и подходят для некоторых бизнес-сценариев, таких как обслуживание клиентов, туризм и боты для платформы вопросов и ответов.
- Инфраструктура данных Орган интеллекта: Процесс RAG является строгим и профессиональным, требующим эксклюзивных рабочих процессов RAG с контекстами, включающими (оповещение -> обнаружение -> остановка кровотечения -> восстановление) и структурированного извлечения вопросов и ответов и опыта реагирования на чрезвычайные ситуации, накопленного экспертами для установления иерархических связей. Поэтому в качестве носителя данных мы выбрали Knowledge Graph.
1.3 Обработка знаний
Исходя из детерминизма и специфики инфраструктуры данных, мы решили использовать ее в качестве носителя знаний для диагностики аварийных ситуаций путем объединения графов знаний. Наши знания об опыте устранения аварийных ситуаций, спровоцированных SRE В сочетании с процессом анализа аварийных ситуаций мы создали граф знаний о чрезвычайных ситуациях в БД, взяв в качестве примера джиттер БД, несколько событий, влияющих на джиттер БД, включая проблемы с медленным SQL, проблемы с пропускной способностью, мы установили взаимосвязи между каждым аварийным событием.
Наконец, мы создали стандартизированную систему обработки знаний из множества источников -> структурированное извлечение знаний -> извлечение аварийных отношений -> экспертная оценка -> хранение знаний шаг за шагом путем стандартизации правил аварийных событий.

1.4 Поиск знаний
На этапе интеллектуального поиска мы используем GraphRAG в качестве носителя статического поиска знаний, поэтому после идентификации аномалии джиттера БД мы находим узлы, связанные с узлом аномалии джиттера БД, в качестве основы для нашего анализа, поскольку каждый узел также сохраняет некоторую информацию метаданных для каждого события на этапе извлечения знаний, включая название события, описание события, связанные инструменты, параметры инструмента и так далее.
Таким образом, мы можем получить результаты возврата через ссылку жизненного цикла выполнения инструмента выполнения, чтобы получить динамические данные, которые можно использовать в качестве основы для экстренной диагностики для устранения неполадок. Благодаря такому гибридному подходу, основанному на динамическом и статическом отзыве, уверенность, профессионализм и строгость исполнения интеллекта инфраструктуры данных гарантированы в большей степени, чем при простом и чистом отзыве RAG.
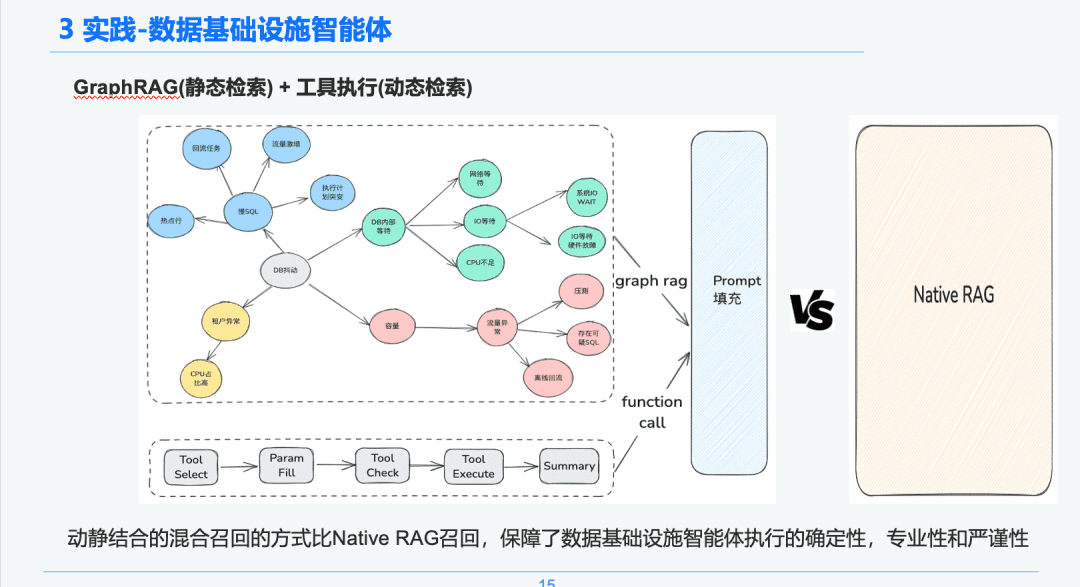
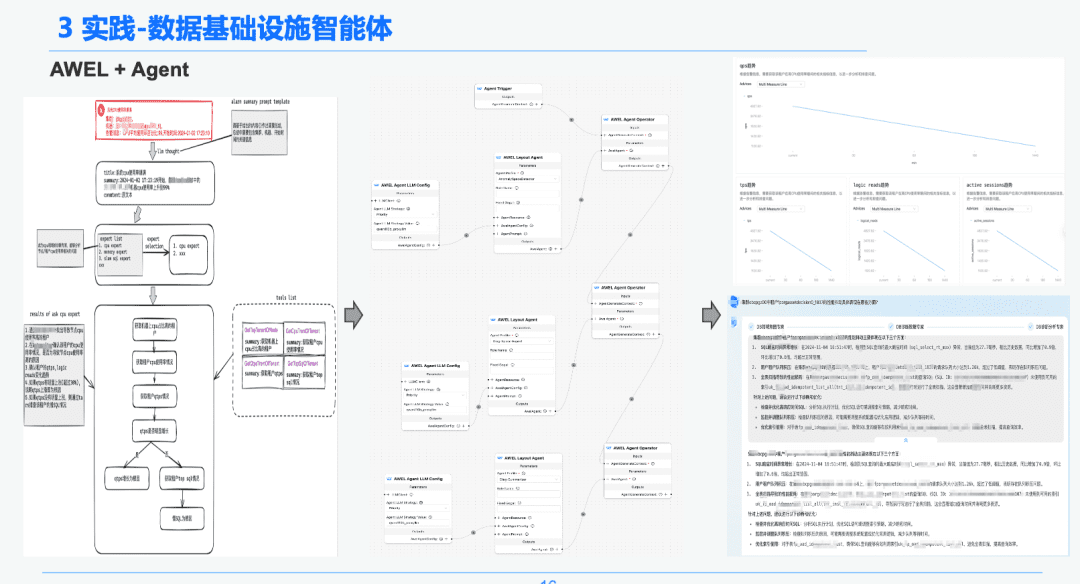
1,5 AWEL + Агент
Наконец, с помощью технологии сообщества AWEL+AGENT парадигма оркестровки AGENT была использована для создания эксперта по намерениям -> эксперта по диагностике чрезвычайных ситуаций -> эксперта по анализу первопричин.
Каждый агент выполняет различные функции. Эксперт по намерениям отвечает за идентификацию и разбор намерений пользователя и выявление предупреждающих сообщений. Эксперт по диагностике должен найти узел первопричины, который необходимо проанализировать с помощью GraphRAG, и получить конкретную информацию о первопричине. Эксперту по анализу необходимо объединить данные каждого узла первопричины + отчет об историческом анализе для создания отчета о диагностическом анализе.
2. RAG в области анализа финансовой отчетности
Последняя практика! Как построить помощник для анализа финансовых отчетов на основе DB-GPT?
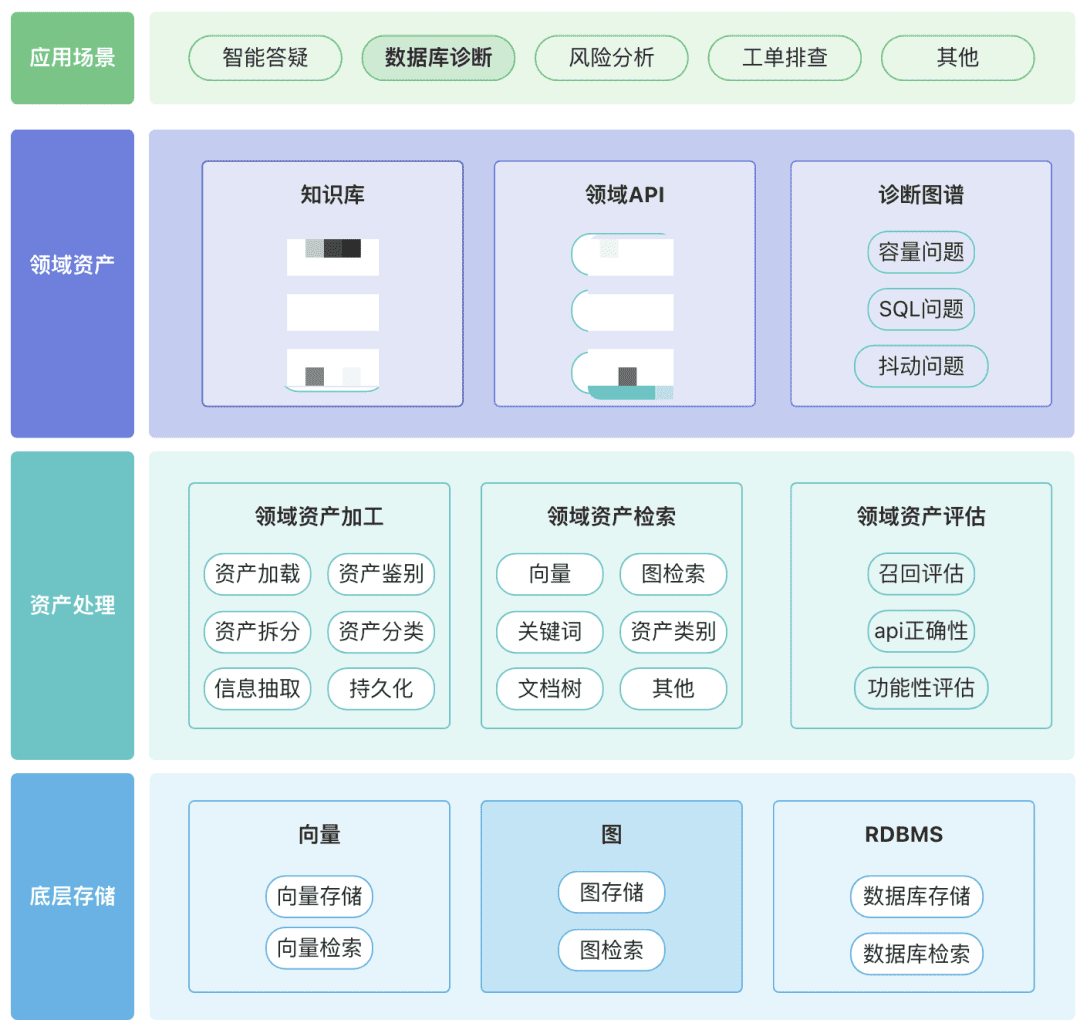
Вы можете создать собственное хранилище доменных активов, включая активы знаний, активы инструментов и активы графа знаний, вокруг вашего домена.
- Активы домена:Активы домена включают базы знаний, API и инструментальные скрипты.
- Обработка активов, вся связь данных об активах включает в себя обработку активов домена, поиск активов домена и оценку активов домена.
- Неструктурированные -> Структурированные: категоризация в структурированном виде, правильно организованная информация о знаниях.
- Извлечение более богатой семантической информации.
- Поиск активов:
- Надеюсь, это иерархический поиск с приоритетами, а не одиночный поиск.
- Постфильтрация очень важна, предпочтительно с помощью бизнес-семантики некоторых правил.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...