
V-JEPA 2 - самая мощная большая модель мира от Meta AI

Что такое V-JEPA 2
V-JEPA 2 Да Мета ИИ Запущена модель мирового масштаба на основе видеоданных с 1,2 млрд параметров. Модель обучается на основе самоконтроля, используя более 1 миллиона часов видео и 1 миллиона изображений, чтобы понять объекты, действия и движения в физическом мире и предсказать будущие состояния. Модель использует архитектуру кодировщика-предиктора в сочетании с предсказанием условий действия для поддержки планирования роботов с нулевой выборкой, что позволяет роботам выполнять задачи в новых условиях. Модель оснащена функциями видеовопросов и поддерживает комбинированные языковые модели для ответов на вопросы, связанные с видеоконтентом. V-JEPA 2 отлично справляется с такими задачами, как распознавание действий, предсказание и видеовопросы, обеспечивая мощную техническую поддержку для управления роботами, интеллектуального наблюдения, образования и здравоохранения, и является важным шагом на пути к продвинутому машинному интеллекту.
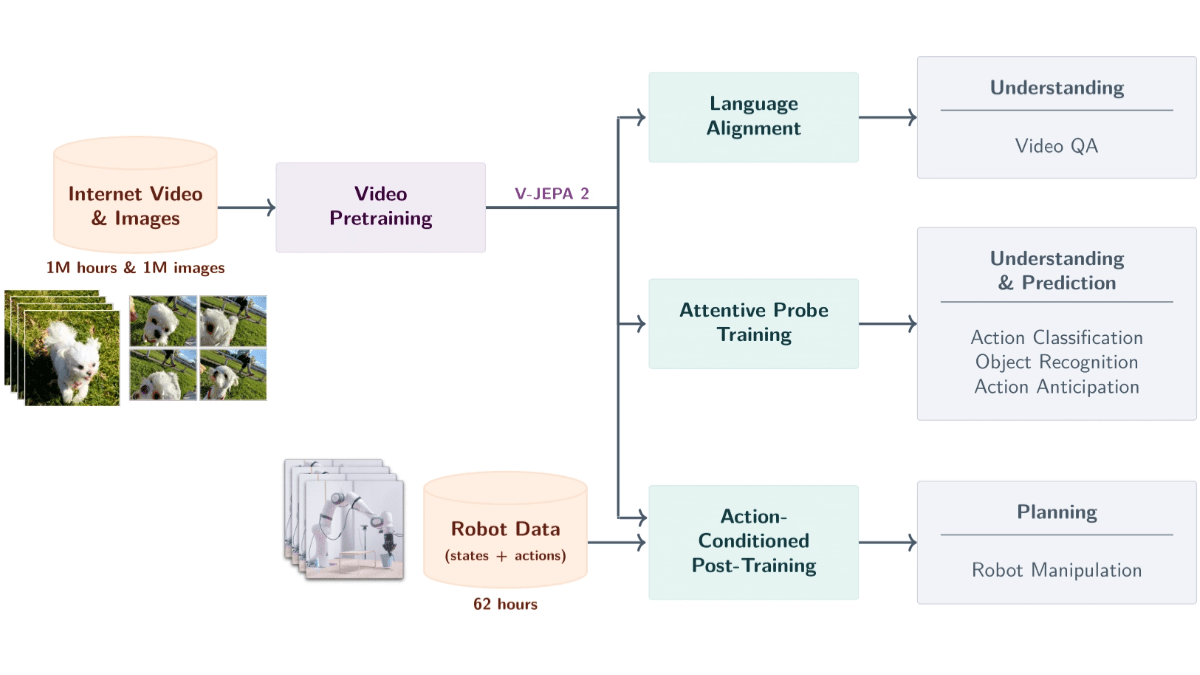
Ключевые особенности V-JEPA 2
- Семантический разбор видео: Распознавание объектов, действий и движений на видео и точное извлечение семантической информации о сцене.
- Прогноз будущих событий: Прогнозирует будущие видеокадры или результаты действий на основе текущего состояния и действий, поддерживая как краткосрочные, так и долгосрочные прогнозы.
- Планирование нулевого образца робота: Планирование задач для роботов в новых условиях, таких как захват и манипулирование объектами, на основе возможностей прогнозирования, без дополнительных данных обучения.
- Взаимодействие с помощью видео вопросов и ответов: Ответьте на вопросы, связанные с содержанием видеоролика, в сочетании с языковым моделированием, охватывающим физическую причинность и понимание сцены.
- Межсценарное обобщение: хорошо работает с невидимыми средами и объектами, поддерживает обучение с нулевой выборкой и адаптацию в новых сценах.
Адрес официального сайта V-JEPA 2
- Веб-сайт проекта::https://ai.meta.com/blog/v-jepa-2
- Репозиторий GitHub::https://github.com/facebookresearch/vjepa2
- Технические документы::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Как использовать V-JEPA 2
- Доступ к ресурсам модели: Загрузите файлы предварительно обученной модели и сопутствующий код из репозитория GitHub. Файлы моделей предоставляются в формате .pth или .ckpt.
- Настройка среды разработки::
- Установка Python: Убедитесь, что Python установлен (рекомендуется Python 3.8 или выше).
- Установка зависимых библиотек: Используйте pip для установки зависимостей, необходимых проекту. Обычно проекты предоставляют файл requirements.txt для установки зависимостей, основанных на следующих командах:
pip install -r requirements.txt- Установка фреймворков глубокого обученияV-JEPA 2 основан на PyTorch и требует установки PyTorch, в зависимости от конфигурации системы и GP, получите команды установки с сайта PyTorch.
- Модели для погрузки::
- Загрузка предварительно обученных моделей: Загрузите файлы предварительно обученных моделей с помощью PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Подготовка к вводу данных::
- Предварительная обработка видеоданных: V-JEPA 2 требует видеоданные в качестве входного сигнала. Видеоданные преобразуются в формат (обычно тензорный), необходимый для модели. Ниже приведен простой пример предварительной обработки:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Прогнозирование с помощью моделей::
- Прогнозы реализации: Введите предварительно обработанные видеоданные в модель, чтобы получить результаты прогнозирования. Ниже приведен пример кода:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Анализ и применение результатов прогнозирования::
- Анализ результатов прогнозирования: Разбирает выходные данные модели в соответствии с требованиями задачи.
- Применение к реальным сценариям: Применяйте предсказания в реальных задачах, таких как управление роботами, видеовикторина или обнаружение аномалий.
Основные преимущества V-JEPA 2
- Глубокое понимание физического мира: V-JEPA 2 может точно распознавать действия и движения объектов на основе видеосигнала, собирать семантическую информацию о сцене и обеспечивать базовую поддержку для сложных задач.
- Эффективное предсказание будущего состояния: На основе текущего состояния и действий модель может предсказывать будущие видеокадры или результаты действий, поддерживая как краткосрочные, так и долгосрочные прогнозы, что способствует развитию таких приложений, как планирование роботов и интеллектуальный мониторинг.
- Возможности обучения с нулевой выборкой и обобщенияV-JEPA 2 отлично справляется с невидимыми средами и объектами, поддерживает обучение и адаптацию с нулевой выборкой и не требует дополнительных обучающих данных для выполнения новых задач.
- Возможность видеовопросов и ответов в сочетании с моделированием языка: В сочетании с языковой моделью V-JEPA 2 может отвечать на вопросы, связанные с видеоконтентом, включая физическую причинность и понимание сцены, что расширяет сферу применения в таких областях, как образование и здравоохранение.
- Эффективное обучение на основе самоконтроля: Обучение общим визуальным представлениям из больших видеоданных на основе самоконтроля без ручной маркировки данных, снижение затрат и улучшение обобщения.
- Многоступенчатая тренировка и прогнозирование условий движения: Основываясь на многоступенчатом обучении, V-JEPA 2 предварительно обучает кодер, а затем обучает предиктор условий движения, объединяя визуальную информацию и информацию о движении для поддержки точного предиктивного управления.
Люди, для которых предназначен V-JEPA 2
- Исследователи искусственного интеллектаАкадемические исследования и технологические инновации с использованием передовой технологии V-JEPA 2 для развития машинного интеллекта.
- Инженер по робототехнике: Разработка робототехнических систем, адаптированных к новым условиям и сложным задачам, с использованием возможностей планирования на основе модели с нулевой выборкой.
- Разработчик компьютерного зрения: Повышение эффективности видеоанализа с помощью V-JEPA 2, используемого в интеллектуальных системах безопасности, промышленной автоматизации и других областях.
- эксперт по обработке естественного языка (NLP): Сочетание визуального и лингвистического моделирования для разработки интеллектуальных систем взаимодействия, таких как виртуальные помощники и интеллектуальное обслуживание клиентов.
- педагог: Разработка иммерсивных образовательных инструментов на основе функций видеовикторины для повышения эффективности преподавания и обучения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...