
Модель генерации изображений CogView4, объявленная с открытым исходным кодом!


Слияние классического китайского искусства и современных элементов. Это изображение вдохновлено картиной "Тысяча миль рек и гор" художника династии Северная Сун Ван Си Мэна. На картине изображен великолепный пейзажный свиток, в котором с помощью техники зеленого пейзажа изображены холмы и обширные реки, богатые цветовые слои и изысканные детали. На фоне этого живописного пейзажа тонко вырисовывается иероглиф "CogView4", выполненный сильным и мощным шрифтом, а тушь имеет правильный оттенок, как будто это импровизированный мазок кисти, сделанный древним литератором во время любования пейзажем. Слова "CogView4" дополняют окружающий пейзаж, не являясь ни слишком резкими, ни слишком гармоничными, а скорее создавая ощущение диалога во времени и пространстве. Вся картина имеет колорит классического пейзажа, но также включает в себя элементы современных технологий, представляя собой уникальное художественное напряжение, позволяющее людям оценить традиционную эстетику и одновременно почувствовать столкновение и слияние современного творчества.
Сегодня мы официально выпустили нашу новейшую модель генерации изображений CogView4 и открыли для нее доступ.
Модель обладает сильными возможностями сложного семантического выравнивания и следования командам, поддерживает двуязычные вводы произвольной длины, способна генерировать изображения произвольного разрешения в заданном диапазоне, а также обладает сильными возможностями генерации текста. Модель также является первой моделью генерации изображений с открытым исходным кодом под протоколом Apache 2.0.
I. Оценка
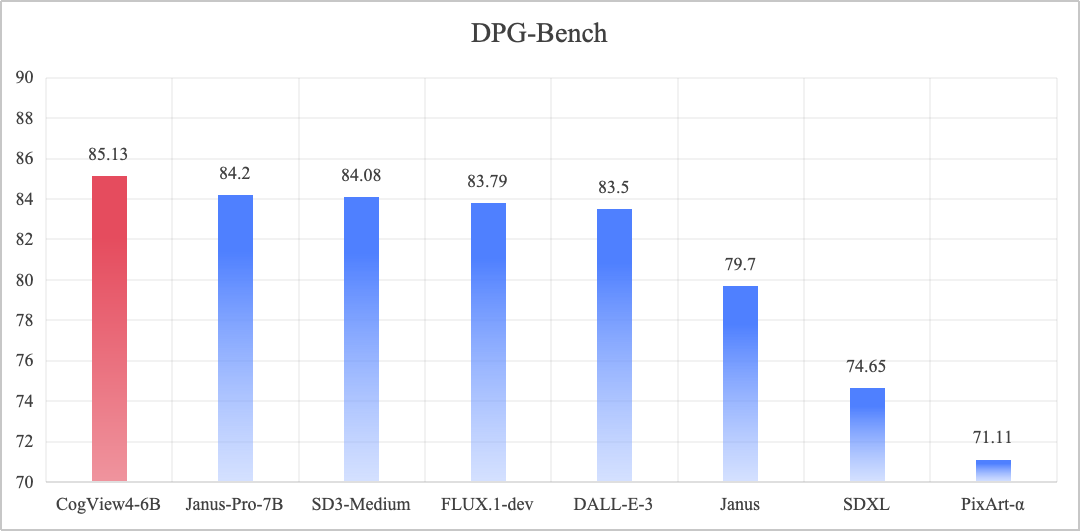
DPG-Bench (Dense Prompt Graph Benchmark) - это эталонный тест для оценки моделей генерации текста в изображение, ориентированный на производительность моделей в плане сложного семантического выравнивания и возможности следования инструкциям.
CogView4-6B, который занимает первое место в бенчмарке DPG-Bench и достигает SOTA в графической модели Vincennes с открытым исходным кодом.
II. Произвольная длина и произвольное разрешение
Модель CogView4 реализует гибридную парадигму обучения с использованием текстовых описаний произвольной длины и изображений произвольного разрешения.
1、Кодирование положения изображения
CogView4 использует 2D Rotational Position Encoding (2D RoPE) для моделирования позиционной информации изображения и поддерживает задачи генерации изображений в различных разрешениях путем интерполяции позиционного кодирования.
2. Моделирование диффузионной генерации
Модель смоделирована с использованием схемы Flow-matching для генерации диффузии в сочетании с параметрическим линейным динамическим планированием шума, чтобы учесть требования к соотношению сигнал/шум для изображений различного разрешения.
3、Архитектурный дизайн
С точки зрения архитектуры модели DiT, CogView4 продолжает архитектуру Share-param DiT своего предшественника и разрабатывает отдельные адаптивные слои LayerNorm для модальностей текста и изображения для достижения эффективной межмодальной адаптации.
4. Многоступенчатое обучение
В CogView4 используется многоступенчатая стратегия обучения, включающая обучение базовому разрешению, обучение панорамному разрешению, тонкую настройку высококачественных данных и обучение выравниванию предпочтений человека. Такой поэтапный подход к обучению не только охватывает широкий диапазон распределений изображений, но и обеспечивает высокую эстетическую привлекательность генерируемых изображений и их соответствие предпочтениям человека.
5. оптимизация системы обучения
С текстовой точки зрения CogView4 преодолевает традиционное ограничение на фиксированную длину лексем, позволяя использовать более высокие верхние границы лексем и значительно сокращая текстовую избыточность лексем во время обучения. Когда средняя длина обучающей надписи находится в диапазоне 200-300 лексем, CogView4 сокращает избыточность лексем примерно на 50% по сравнению с традиционной схемой с фиксированными 512 лексемами и достигает повышения эффективности на 5%-30% на этапе прогрессивного обучения модели.
С точки зрения изображения, обучение со смешанным разрешением позволяет модели поддерживать создание произвольного разрешения в широком диапазоне, что значительно расширяет свободу творчества. Целевое разрешение должно удовлетворять только следующим условиям:
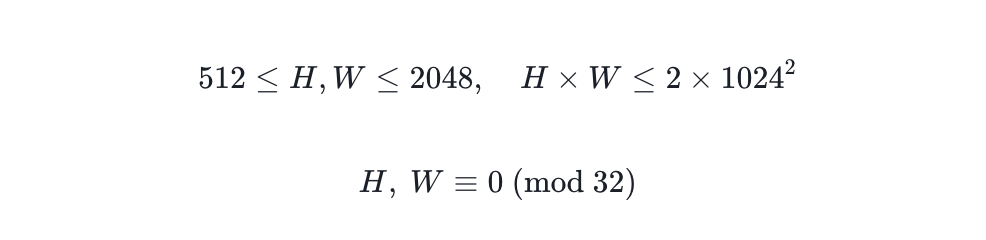
И то, и другое может значительно увеличить творческую свободу.
Пример: очень длинная история (четырехпанельный комикс)

Принцесса: человеческая женщина, красивая и элегантная, одетая в великолепный костюм принцессы, заключенная в логово монстра.
Король: человеческий мужчина, величественный и благосклонный, одетый в богатые королевские одежды и восседающий на троне королевства.
Огненный дракон: монстр, покрытый чешуей, похожей на пламя, изрыгающий пламя и огромный по размеру.
Темный лорд: монстр огромных размеров, окутанный тьмой, обладает огромной магической силой.
Сцена 1: Сяо Мин отправляется в путешествие
Создайте сцену в стиле аниме с великолепным королевским двором на заднем плане. Главный герой сцены - Котомине (человеческий мальчик с храбрым сердцем, держащий меч и одетый в простой костюм воина), который изображен в позе, отправляющейся в путешествие. В картину включены детали цветов во дворе и замок вдали, а свет утреннего солнца передает храбрость и решимость. Качество: шедевр, лучшее качество, супер детализация, 4k
Сцена 2: Минг побеждает Огненного Дракона
Создайте сцену в стиле аниме с огненным кратером на заднем плане. Главный герой сцены - Котомине (человеческий мальчик с храбрым сердцем, держащий меч и одетый в простой костюм воина), который находится в момент победы над огненным драконом. В картину включены детали скал и лавы в кратере, а огненно-красное освещение передает свирепость и отвагу. Качество: шедевр, лучшее качество, супер детализация, 4k
Сцена 3: Минг сражается с Темным Лордом!
Создайте сцену в стиле аниме с теневым логовом монстров на заднем плане. Главный герой сцены - Минг (человеческий мальчик с храбрым сердцем, мечом в руке и в простом костюме воина), который находится в центре ожесточенной битвы с Темным Лордом. Включает в себя детали тьмы и магической энергии логова, а мрачное освещение передает интенсивность и напряжение. Качество: шедевр, лучшее качество, супер детализация, 4k
Сцена 4: Минг спасает принцессу
Создайте сцену в стиле аниме с интерьером заброшенного замка на заднем плане. Главные герои сцены - Минг (человеческий мальчик с храбрым сердцем, держащий меч и одетый в простой костюм воина) и принцесса (человеческая женщина, красивая и элегантная, одетая в великолепный костюм принцессы), которые участвуют в душещипательной сцене спасения Мингом принцессы. Включает в себя детали внутренних руин замка и приглушенное освещение, а мягкое освещение передает трогательность и искупление. Качество: шедевр, лучшее качество, супер детализация, 4k
C. Поддержка китайского и английского языков
С точки зрения технической реализации, CogView4 переключает кодировщик текста с англоязычного кодировщика T5 на двуязычный кодировщик GLM-4 и обучается с помощью двуязычных графических пар, так что модель CogView4 имеет возможность вводить двуязычные слова подсказки.
На данный момент CogView4 является первой графической моделью с открытым исходным кодом, поддерживающей двуязычный ввод слов-подсказок, и особенно хорошо справляется с пониманием и следованием китайским подсказкам и генерированием китайских иероглифов на экране. Эти две особенности больше подходят для широкого спектра творческих потребностей в отечественной рекламе, коротком видео и других областях.

IV. Протокол Apache
Модель CogView4-6B поддерживает протокол Apache2.0, в дальнейшем будут добавлены ControlNet, ComfyUI и другие экоподдержки, скоро будет доступен полный набор инструментов для тонкой настройки.
Модель склада:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
обновлено CogView4 Модель появится на сайте chatglm.cn 13 марта.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...