ThinkSound - моделирование генерации звука от Али Тонги

Что такое ThinkSound?
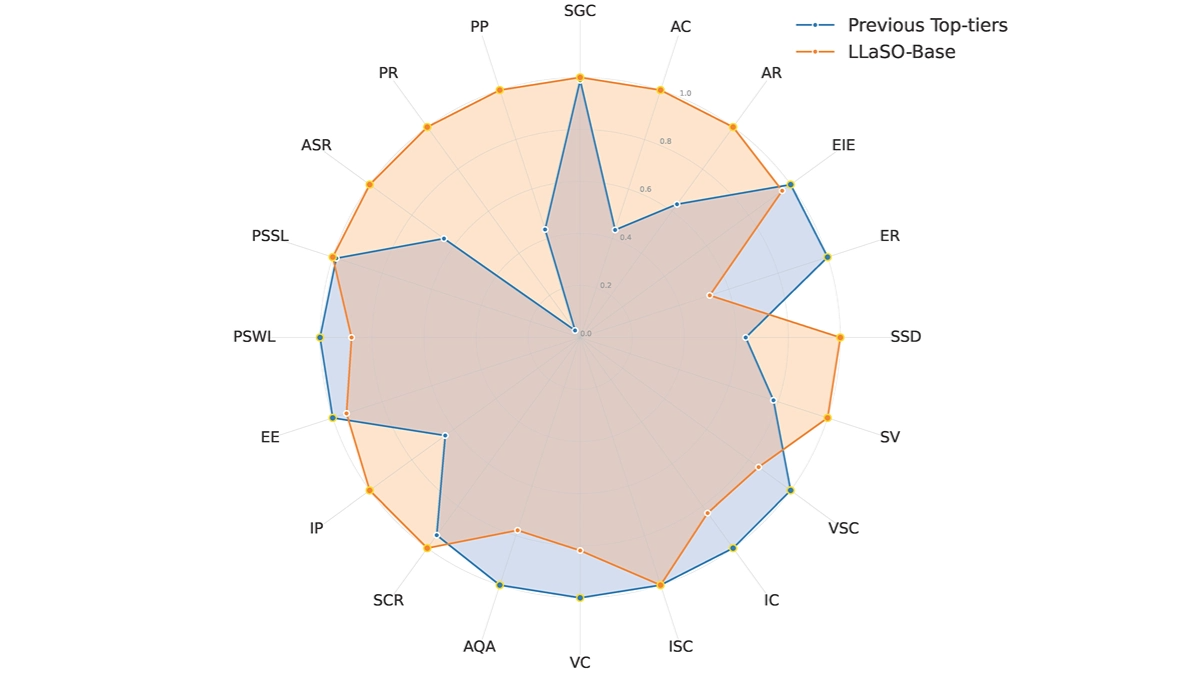
ThinkSound - это первая модель генерации звука CoT (Chain Thinking), представленная речевой командой Али Тонги. Модель может генерировать точно подобранные звуковые эффекты для видеоизображений, основываясь на внедрении CoT-рассуждений, чтобы решить проблему, связанную с тем, что традиционной технологии сложно передать динамические детали и пространственные отношения изображения. В основе модели лежит цепочка мыслей третьего порядка, которая управляет генерацией звука, включая базовые звуковые выводы, взаимодействие на уровне объектов и редактирование команд. Модель оснащена набором данных AudioCoT, который содержит аудиоданные, аннотированные цепочкой мыслей, и обладает отличной производительностью на наборе данных VGGSound. ThinkSound используется в кино и телепроизводстве, разработке игр, рекламе и маркетинге, виртуальной реальности (VR) и дополненной реальности (AR) для повышения реалистичности и погружения в аудио-видео синхронизацию.

Основные характеристики ThinkSound
- Базовая генерация звука: На основе содержания видео генерируйте базовые звуковые эффекты, соответствующие семантике и синхронизации экрана, чтобы создать подходящий звуковой фон для видео, чтобы оно перестало быть монотонным и беззвучным.
- Интерактивное уточнение на уровне объектов: Пользователь нажимает на определенный объект в видео, чтобы уточнить и оптимизировать звуковой эффект конкретного объекта, чтобы звуковой эффект более точно соответствовал конкретному визуальному элементу и улучшал координацию звука и изображения.
- Редактирование звука с помощью командОн поддерживает редактирование сгенерированного аудио с помощью команд на естественном языке, например, добавление, удаление или изменение определенных звуковых эффектов, чтобы удовлетворить различные творческие потребности и сделать генерацию аудио более гибкой и разнообразной.
Адрес официального сайта ThinkSound
- Веб-сайт проекта:: https://thinksound-project.github.io/
- Репозиторий GitHub:: https://github.com/liuhuadai/ThinkSound
- Библиотека моделей HuggingFace:: https://huggingface.co/liuhuadai/ThinkSound
- Технический документ arXiv:: https://arxiv.org/pdf/2506.21448
Как использовать ThinkSound
- Подготовка к защите окружающей среды::
- Установка Python: Убедитесь, что в вашей системе установлен Python (рекомендуется Python 3.8 и выше).
- Установка зависимых библиотек: Установите необходимые библиотеки зависимостей для ThinkSound, выполнив следующую команду:
pip install -r requirements.txt- Файл требований к конкретным зависимостям requirements.txt можно найти в репозитории GitHub.
- Скачать модели::
- Загрузка репозитория GitHub: Посетите репозиторий ThinkSound на GitHub (https://github.com/liuhuadai/ThinkSound), чтобы клонировать репозиторий локально:
git clone https://github.com/liuhuadai/ThinkSound.git
cd ThinkSound- Обнимающиеся лица Скачать: Загрузите форму непосредственно из библиотеки моделей Hugging Face (https://huggingface.co/liuhuadai/ThinkSound).
- Подготовка данных::
- Подготовка видеофайла: Убедитесь, что есть видеофайл, ThinkSound будет генерировать звук на основе этого видео.
- Подготовка командного файла: Если для редактирования аудиозаписи необходимы инструкции на естественном языке, подготовьте текстовый файл с этими инструкциями.
- операционная модель::
- Базовая генерация звука: Выполните следующую команду, чтобы сгенерировать базовый звук:
python generate.py --video_path <path_to_your_video> --output_path <path_to_output_audio>- Интерактивное уточнение на уровне объектов: Если вам нужно доработать звуковые эффекты для конкретного объекта, вы можете сделать это, изменив соответствующие параметры в коде или используя интерактивный интерфейс (если он поддерживается).
- Редактирование звука с помощью команд: Редактирование аудио с помощью команд на естественном языке, основанных на следующих командах:
python edit.py --audio_path <path_to_generated_audio> --instruction_file <path_to_instruction_file> --output_path <path_to_edited_audio>- Посмотреть результаты::
- Проверка сгенерированного аудио: В указанном пути вывода найдите сгенерированный аудиофайл, воспроизведите и проверьте его с помощью аудиоплеера.
- Параметры настройки: В соответствии с полученным аудиоэффектом настройте параметры модели или входные команды, чтобы получить более удовлетворительный аудиоэффект.
Основные преимущества ThinkSound
- Цепное мышление (CoT)Звук основан на многоступенчатых рассуждениях, которые имитируют творческий процесс звукорежиссеров, точно передавая динамические детали и пространственные отношения на экране, генерируя высокосовместимый звук и повышая реалистичность синхронизированного звука и изображения.
- Мультимодальное моделирование больших языков (MLLM): Извлечение пространственно-временной информации видео и семантического содержания на основе таких моделей, как VideoLLaMA2, генерация структурированных цепочек выводов для семантически согласованного аудио и улучшение координации аудио и изображения.
- Базовая модель унифицированного аудио: На основе технологии условного сопоставления потоков в сочетании с мультимодальной контекстной информацией генерируется высококачественный звук, поддерживающий гибкие комбинации входных модальностей для удовлетворения разнообразных потребностей в создании и редактировании.
- Интерактивное уточнение на уровне объектовЗвуковые эффекты оптимизированы для пользователей, нажимающих на определенные объекты в видео, так что звуковые эффекты точно соответствуют визуальным элементам, повышая координацию и реалистичность звука и изображения, а управление интуитивно понятно и удобно.
- Редактирование звука с помощью команд: Поддержка команд на естественном языке для редактирования звука, таких как добавление, удаление или изменение определенных звуковых эффектов, что позволяет создавать аудио с учетом различных творческих потребностей и расширяет свободу творчества.
- Мощная поддержка наборов данных: Оснащен набором данных AudioCoT со структурированными аннотациями CoT, которые используются для обучения оптимизационных моделей, чтобы улучшить понимание и генерацию аудиовизуальных связей и обеспечить качество генерации аудио.
Для кого предназначен ThinkSound
- кинопродюсер: Команды по производству фильмов и телесериалов, а также создатели коротких видеороликов могут быстро генерировать реалистичные фоновые звуковые эффекты и звуковые эффекты для конкретных сцен, чтобы улучшить погружение зрителей и привлекательность контента.
- разработчик игрКомпания генерирует динамические эмбиентные и интерактивные звуковые эффекты, которые усиливают погружение игрока в игру и интерактивность, экономя затраты на производство звука и время.
- Сотрудники отдела рекламы и маркетинга: Рекламные агентства и создатели контента для социальных сетей могут создавать привлекательные звуковые эффекты и саундтреки для рекламных видеороликов и видеороликов для социальных сетей, чтобы повысить привлекательность контента и вовлеченность пользователей.
- Обучение и подготовка персонала: Платформы онлайн-образования и корпоративные тренеры, которые генерируют соответствующие содержанию звуковые эффекты для учебных видео и симулированных учебных сред, чтобы помочь учащимся лучше понять и запомнить, а также повысить эффективность обучения.
- Разработчики виртуальной реальности (VR) и дополненной реальности (AR): Разработчики VR/AR-приложений и дизайнеры опыта могут генерировать высокосовместимые звуковые эффекты в виртуальных средах, улучшая погружение и интерактивность пользователей и обеспечивая персонализированный опыт.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...