Step-Audio-AQAA - сквозная модель большого аудиоязыка от StepFun

Что такое Step-Audio-AQAA?
Step-Audio-AQAA - это сквозная крупномасштабная модель аудиоязыка для задач "аудиозапрос-аудиоответ" (AQAA) от команды StepFun. Способность напрямую обрабатывать аудиоданные для генерации естественных и точных речевых ответов без использования традиционных модулей автоматического распознавания речи (ASR) и преобразования текста в речь (TTS) упрощает архитектуру системы и устраняет каскадные ошибки. Процесс обучения Step-Audio-AQAA включает мультимодальное предварительное обучение, контролируемую точную настройку (SFT), прямую оптимизацию предпочтений (DPO) и объединение моделей. Благодаря этим методам модель демонстрирует высокие результаты в таких сложных задачах, как управление эмоциями речи, ролевые игры и логические рассуждения. В бенчмарке StepEval-Audio-360 Step-Audio-AQAA превосходит существующие модели LALM по нескольким ключевым параметрам, демонстрируя мощный потенциал для сквозного речевого взаимодействия.
Основные характеристики Step-Audio-AQAA
- Прямая обработка аудиовходов: Генерирует голосовые ответы непосредственно из исходного аудиосигнала, не прибегая к традиционным модулям автоматического распознавания речи (ASR) и преобразования текста в речь (TTS).
- Бесшовное голосовое взаимодействие: Поддержка взаимодействия "голос - речь", пользователи могут задавать вопросы голосом, и модель отвечает непосредственно голосом, повышая естественность и плавность взаимодействия.
- Регулировка эмоционального тона: Поддержка настройки эмоционального тона речи на уровне предложений, например, для выражения таких эмоций, как счастье, грусть или серьезность.
- контроль речиПользователь может регулировать скорость голосового ответа по мере необходимости, чтобы сделать его более отзывчивым к потребностям сценария.
- Регулировка тембра и высоты тона: Он может регулировать тон и высоту голоса в соответствии с командами пользователя, адаптируясь к различным ролям или сценариям.
- многоязычное взаимодействие: Поддержка китайского, английского, японского и других языков для удовлетворения языковых потребностей различных пользователей.
- Поддержка диалектов: Охват китайских диалектов, таких как сычуаньский и кантонский, для повышения применимости модели в конкретных регионах.
- управление эмоциями с помощью голоса: Может генерировать голосовые ответы с определенными эмоциями в зависимости от контекста и команд пользователя.
- ролевая игра (игра): Поддерживает воспроизведение определенных ролей в диалоге, например, клиент, учитель, друг и т.д., и генерирование голосовых ответов, соответствующих характеристикам роли.
- Тесты на логическое мышление и знания: Может решать сложные задачи на логическое мышление и проводить викторины на знание предмета, генерируя точные голосовые ответы.
- Высокое качество передачи голоса: Генерируйте высокоточные, естественные и плавные формы речи с помощью нейронных вокодеров, чтобы повысить удобство использования.
- фонетическая когерентность: Сохраняйте связность и последовательность речи в длинных предложениях или абзацах, избегая речевых пауз или резких изменений.
- Чередование текста и речи: Поддерживает чередование текстового и голосового вывода, позволяя пользователям выбирать голосовые или текстовые ответы по мере необходимости.
- Понимание мультимодального ввода: Понимает смешанный ввод, содержащий речь и текст, генерируя соответствующие речевые реакции.
Адрес проекта Step-Audio-AQAA
- Библиотека моделей HuggingFace:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- Технический документ arXiv:: https://arxiv.org/pdf/2506.08967
Технические принципы Step-Audio-AQAA
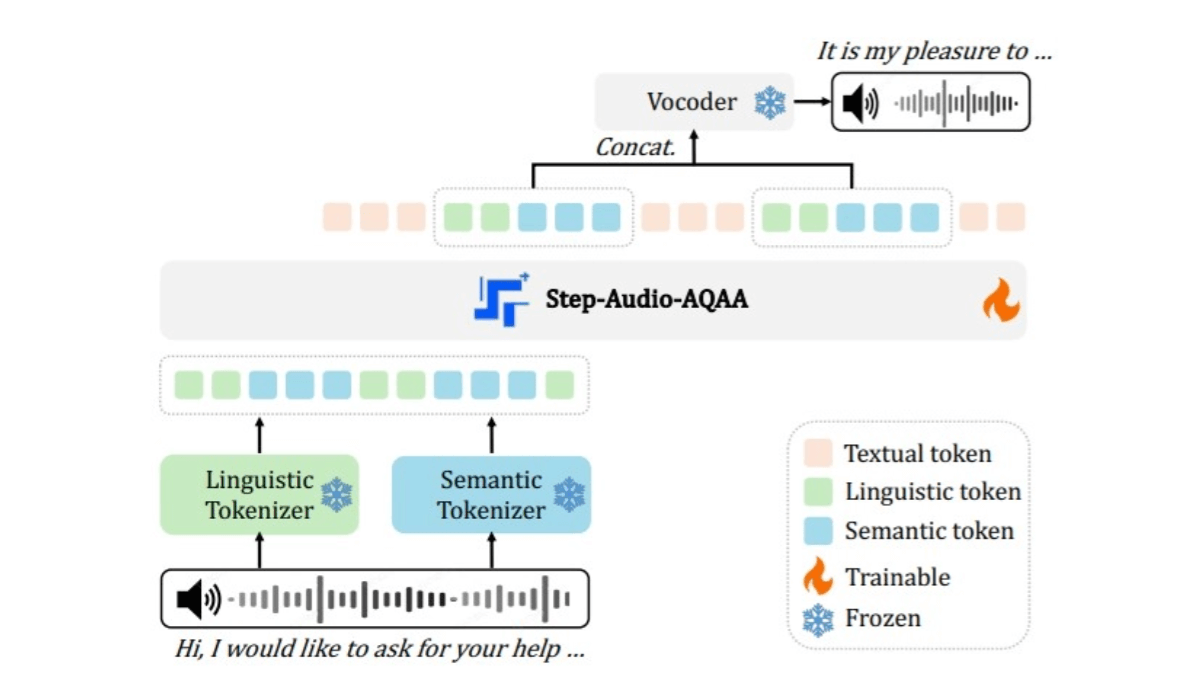
- Аудиоразделитель с двумя кодовыми книгами: Преобразует входной аудиосигнал в структурированную последовательность лексем. Состоит из двух лексеров: лингвистический лексер извлекает фонемы и лингвистические атрибуты речи с частотой дискретизации 16,7 Гц и размером кодовой книги 1024, а семантический лексер фиксирует акустические особенности речи, такие как эмоции и интонации, с частотой дискретизации 25 Гц и размером кодовой книги 4096, что лучше отражает сложность информации в речи.
- Магистратура LLM: Используется предварительно обученный мультимодальный LLM (Step-Omni) с 130 миллиардами параметров, данные предварительного обучения охватывают три модальности: текст, речь и изображение. Звуковые лексемы бикодового текста встраиваются в единое векторное пространство с помощью нескольких Трансформатор блоки для глубокого семантического понимания и извлечения признаков.
- нейронный вокодер: Синтезирует сгенерированные звуковые лексемы в естественные, высококачественные формы речи. Архитектура U-Net в сочетании со слоем ResNet-1D и блоком Transformer эффективно преобразует дискретные звуковые лексемы в непрерывные речевые сигналы.
Основные преимущества Step-Audio-AQAA
- Сплошное аудиовзаимодействиеStep-Audio-AQAA генерирует естественные, плавные голосовые ответы непосредственно из исходного аудиосигнала, избавляя от необходимости полагаться на традиционные модули автоматического распознавания речи (ASR) и преобразования текста в речь (TTS). Комплексная разработка позволяет избежать искажения результатов, вызванного ошибками в ASR или TTS в традиционных решениях.
- Поддержка нескольких языков: Модель поддерживает несколько языков, включая китайский (в том числе сычуаньский и кантонский), английский, японский и т.д., что позволяет удовлетворить языковые потребности различных пользователей.
- Тонкое управление голосовыми функциямиStep-Audio-AQAA обеспечивает тонкое управление голосовыми характеристиками, такими как эмоциональная интонация, темп речи и т. д., для создания более отзывчивых голосовых реакций. Особенно хорошо он справляется с управлением эмоциями голоса.
Для кого предназначен Step-Audio-AQAA?
- Пользователи интеллектуального голосового помощника: Пользователи, которые хотят использовать устройства голосового взаимодействия (например, смарт-динамики, смарт-ассистенты) для выполнения повседневных операций (например, проверка информации, установка напоминаний, воспроизведение музыки и т. д.).
- любитель игр: Геймеры, которые любят взаимодействовать с внутриигровыми NPC для более полного погружения в игровой процесс.
- Пользователи образования: Студенты и родители, которые хотят учиться с помощью голосового взаимодействия (например, изучать язык, проводить викторины и т.д.).
- Пожилые люди и дети: Голосовое взаимодействие более удобно и естественно для пользователей, которые не умеют пользоваться текстовым вводом.
- создатель аудиокниг: Создатели, которым необходимо генерировать высококачественный голосовой контент, например аудиокниги, радиоспектакли и т. д.
- видеопродюсерСоздатели, которым требуется голосовое взаимодействие или возможность генерации голоса при создании видеоконтента (например, коротких видеороликов, прямых трансляций).
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...