
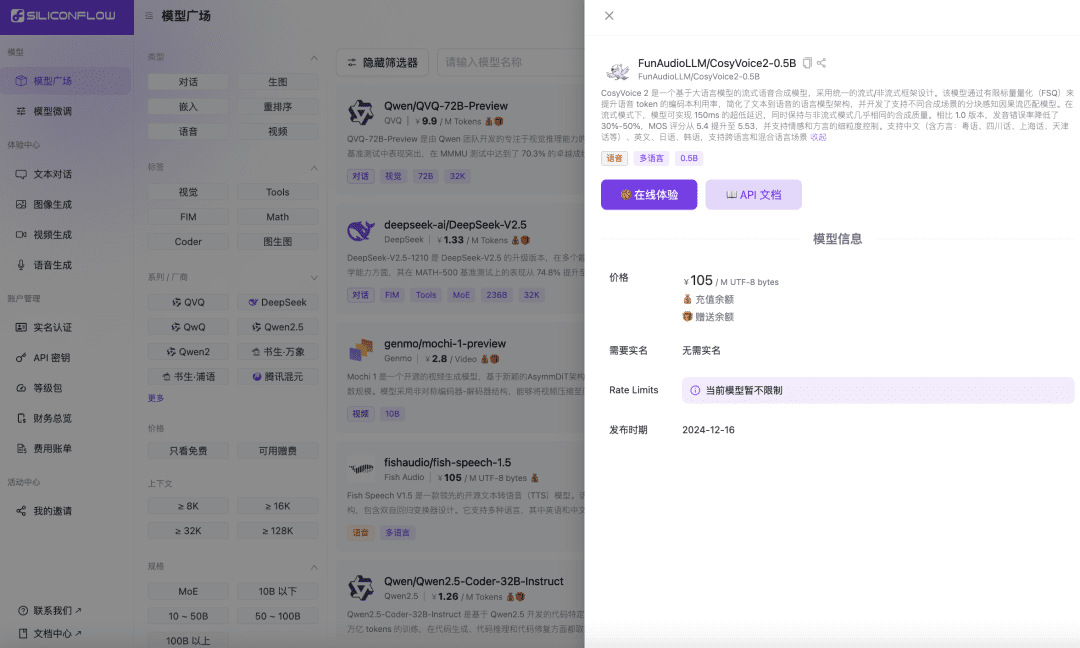
Siliconcloud запускает ускоренную версию CosyVoice2: 150-минутный синтез речи в реальном времени, поддержка смешанных языков и диалектов


Недавно речевая команда лаборатории Ali Tongyi официально выпустила модель синтеза речи.CosyVoice2. Модель поддерживает двунаправленную потоковую передачу текста и речи, поддерживает многоязычие, смешанные языки и диалекты, а также обеспечивает более точные, стабильные, быстрые и качественные возможности генерации речи. Теперь Siliconcloud, поток Siliconcloud на основе кремния, официально доступен онлайн с версией ускорения вывода CosyVoice2-0.5B (цена ¥105/ M UTF-8 байт, каждый символ занимает от 1 до 4 байт), которая включает время передачи данных по сети, что делает выходную задержку модели низкой до 150 мс, обеспечивая более эффективный пользовательский опыт для ваших генеративных приложений ИИ. Как и другие модели синтеза языка на SiliconCloud, CosyVoice2 поддерживает 8 предустановленных тонов, пользовательские тона, а также динамические тона, настраиваемые скорость речи, усиление звука и выходную частоту дискретизации.
Опыт работы в Интернете
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
Документация по API
https://docs.siliconflow.cn/api-reference/audio/create-speech
Ознакомьтесь с версией CosyVoice 2.0 от SiliconCloud, ускоренной с помощью выводов.
В сочетании с ранее представленной компанией SiliconCloudМодель распознавания речи Али SenseVoice-Small (доступна бесплатно)С помощью модели API разработчики могут эффективно создавать комплексные приложения для голосового взаимодействия, включая аудиокниги, потоковые аудиовыходы, виртуальные помощники и другие приложения.
Особенности и характеристики модели
CosyVoice2 это модель потокового синтеза речи, основанная на большой языковой модели и разработанная с использованием единого фреймворка потокового/непотокового вещания. Модель улучшает использование кодовой книги речевых лексем с помощью конечного скалярного квантования (FSQ), упрощает архитектуру языковой модели преобразования текста в речь и разрабатывает модель каузального согласования потоков с учетом чанков, которая поддерживает различные сценарии синтеза. В потоковом режиме модель достигает сверхнизкой задержки в 150 мс, сохраняя при этом почти такое же качество синтеза, как и в непотоковом режиме.
Кроме того, CosyVoice2 добился значительного прогресса в интеграции базовой модели и командной модели, не только продолжив поддержку эмоций, стилей речи и тонких команд управления, но и добавив возможность работы с китайскими командами.CosyVoice2 также представил функции ролевой игры, такие как возможность подражать роботам и стиль речи Свинки Пеппы.
В частности, версия 2.0 имеет следующие преимущества перед CosyVoice версии 1.0:
Поддержка нескольких языков
- Поддерживаемые языки: китайский, английский, японский, корейский, китайские диалекты (кантонский, сычуаньский, шанхайский, тяньцзиньский, уханьский и др.)
- Кросс-язык и смешанные языки: поддержка клонирования речи с нулевым образцом в сценариях кросс-языка и переключения кодов.
сверхнизкая задержка
- Поддержка двунаправленного потокового вещания: CosyVoice 2.0 объединяет технологии автономного и потокового моделирования.
- Быстрый синтез первого пакета: достижение задержек до 150 миллисекунд при сохранении высокого качества выходного аудиосигнала.
высокоточный
- Улучшение произношения: количество ошибок произношения сократилось на 30% до 50% по сравнению с CosyVoice 1.0.
- Достижение контрольной точки: достижение наименьшего числа ошибок в символах на сложном тестовом наборе оценочного набора Seed-TTS.
высокая стабильность
- Согласованность тонов: обеспечивает надежную согласованность тонов при синтезе речи с нулевым образцом и межъязыковом синтезе.
- Межъязыковой синтез: значительные улучшения по сравнению с версией 1.0.
естественная беглость речи
- Усиление ритма и тональности: повышение балла оценки MOS с 5,4 до 5,53.
- Эмоции и диалектная гибкость: поддерживает более тонкий контроль эмоций и регулировку диалектного акцента.
Оценка разработчиков
Как только CosyVoice 2.0 был выпущен, некоторые разработчики первым делом испытали его. Некоторые разработчики отметили, что он поддерживает сверхтонкие функции управления и более реалистичный и естественный синтез голоса. 
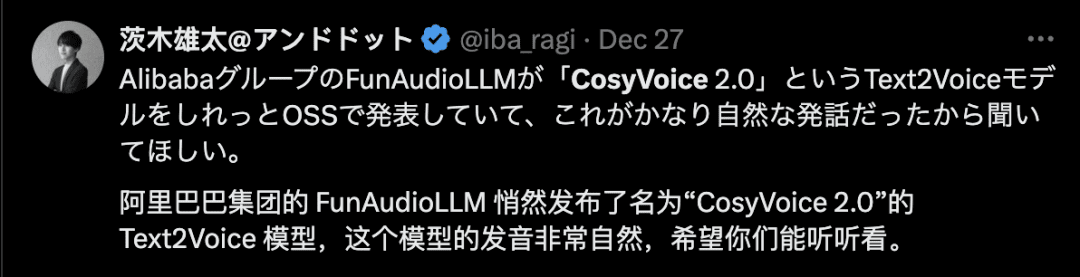 Однако, по словам некоторых пользователей, несмотря на то, что их привлекли превосходные характеристики генерации речи, развертывание стало серьезной проблемой.
Однако, по словам некоторых пользователей, несмотря на то, что их привлекли превосходные характеристики генерации речи, развертывание стало серьезной проблемой. 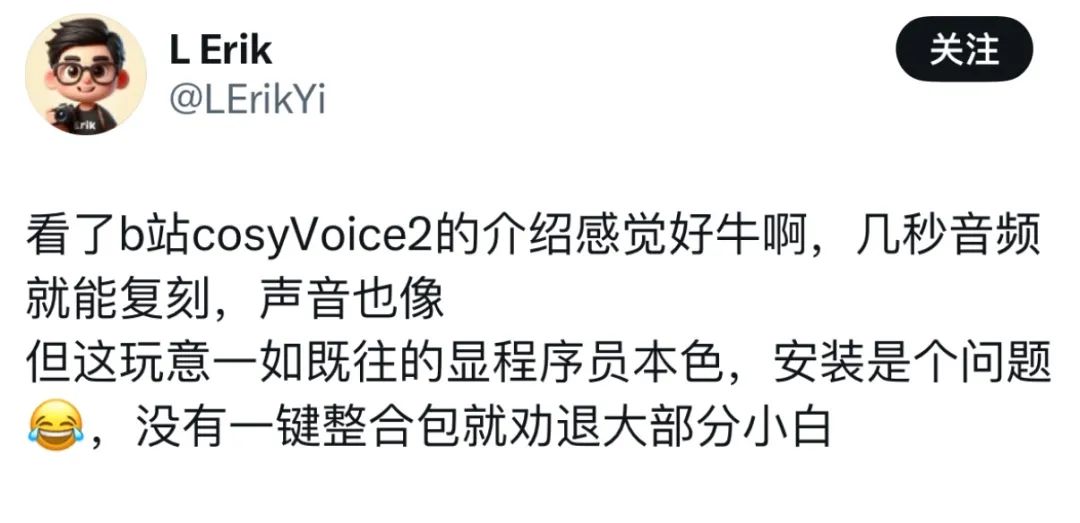 Теперь, когда Siliconcloud выпустила CosyVoice 2.0, устранив необходимость в сложных развертываниях, вы можете просто вызвать API и получить доступ к своим собственным приложениям.
Теперь, когда Siliconcloud выпустила CosyVoice 2.0, устранив необходимость в сложных развертываниях, вы можете просто вызвать API и получить доступ к своим собственным приложениям.
Token Factory SiliconCloud Qwen 2.5 (7B) и еще 20+ других моделей бесплатно!
Будучи универсальной платформой облачных сервисов, SiliconCloud стремится предоставить разработчикам чрезвычайно отзывчивые, доступные, полные и гладкие API для моделей. В дополнение к CosyVoice2, SiliconCloud уже положила на полку целый ряд API для моделей, включая QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-preview, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat, а также десятки открытых моделей больших языков, моделей генерации изображений/видео, моделей речи, кодов/математических моделей и векторных моделей. и модели переупорядочивания. 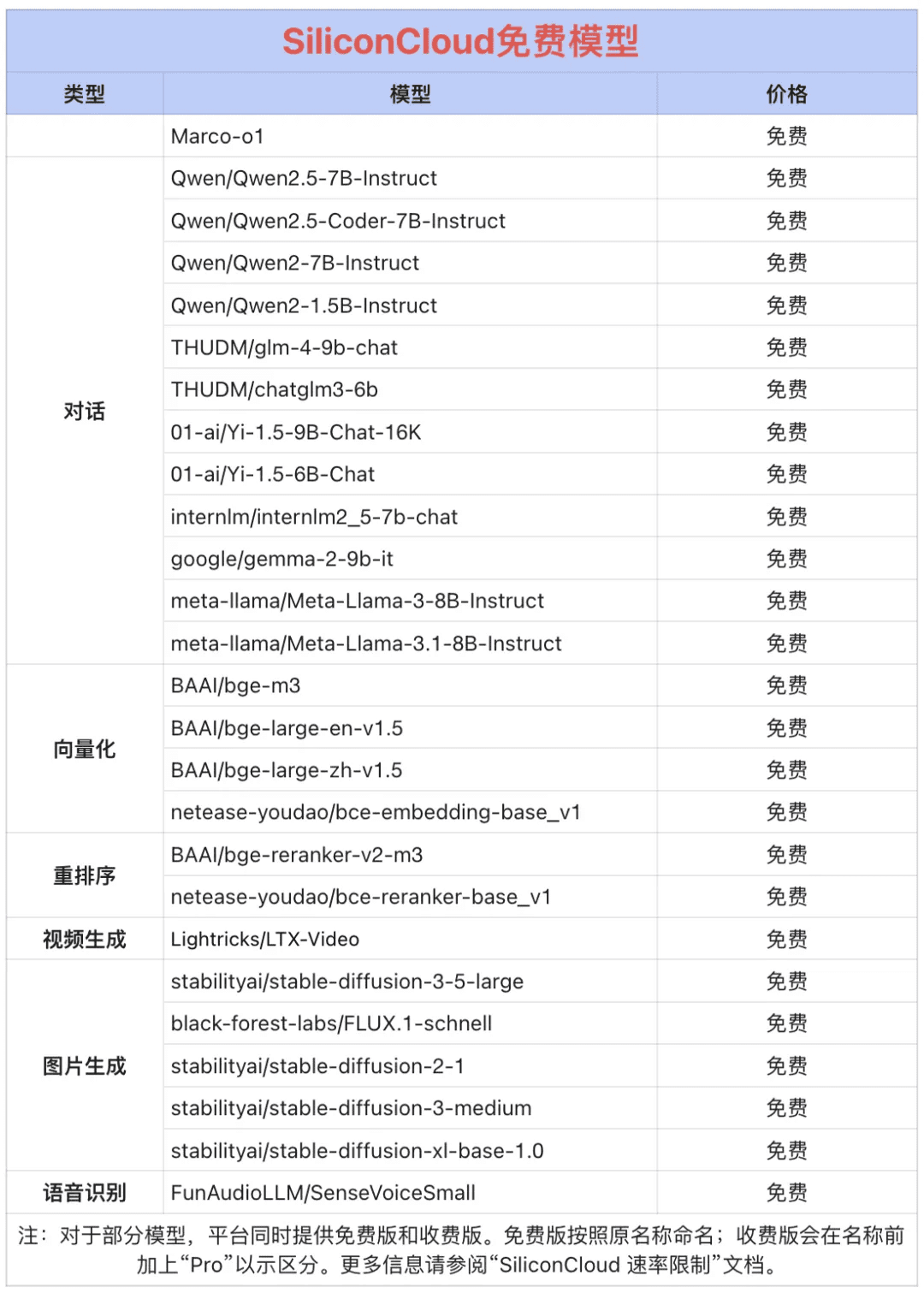 Среди них Qwen2.5 (7B), Llama3.1 (8B) и другие 20+ API больших моделей бесплатны для использования, так что разработчикам и менеджерам продуктов не нужно беспокоиться об арифметических затратах на этап исследований и разработок и масштабное продвижение, и реализовать "Token Freedom".
Среди них Qwen2.5 (7B), Llama3.1 (8B) и другие 20+ API больших моделей бесплатны для использования, так что разработчикам и менеджерам продуктов не нужно беспокоиться об арифметических затратах на этап исследований и разработок и масштабное продвижение, и реализовать "Token Freedom".
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...