Быстрое развертывание RAG 3-Pack для Dify с помощью GPUStack

GPUStack Это платформа с открытым исходным кодом, позволяющая эффективно интегрировать и использовать различные гетерогенные ресурсы GPU/NPU, такие как Nvidia, Apple Metal, Huawei Rise и Moore Threads, для локального частного развертывания решений на основе больших моделей.
GPUStack может поддерживать RAG Три ключевые модели, необходимые для системы: модель диалога в чате (большая языковая модель), модель встраивания текста Embedding и модель переупорядочивания Rerank - доступны в комплекте из трех частей, и развернуть локальные частные модели, необходимые для системы RAG, - очень простая и безошибочная операция.
Вот как установить GPUStack и Dify с помощью Dify для взаимодействия с моделью диалога, моделью встраивания и моделью реранкера, развернутой GPUStack.
Установка GPUStack
Установите его онлайн на Linux или macOS с помощью следующей команды, в процессе установки потребуется пароль sudo: curl -sfL https://get.gpustack.ai | sh -
Если вы не можете подключиться к GitHub для загрузки некоторых двоичных файлов, используйте следующие команды для их установки с помощью --tools-download-base-url Параметр указывает на загрузку из облачного хранилища Tencent Cloud Object Storage:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Запустите Powershell от имени администратора в Windows и установите его в режиме онлайн с помощью следующей команды:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Если вы не можете подключиться к GitHub для загрузки некоторых двоичных файлов, используйте следующие команды для их установки с помощью --tools-download-base-url Параметр указывает на загрузку из облачного хранилища Tencent Cloud Object Storage:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Если вы увидите следующее сообщение, значит, GPUStack был успешно развернут и запущен:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
Далее следуйте инструкциям в выводе сценария, чтобы получить начальный пароль для входа в GPUStack, и выполните следующую команду:
на Linux или macOS:cat /var/lib/gpustack/initial_admin_password
В Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Зайдите в GPUStack UI через браузер с именем пользователя admin и паролем, полученным выше.
После сброса пароля введите GPUStack: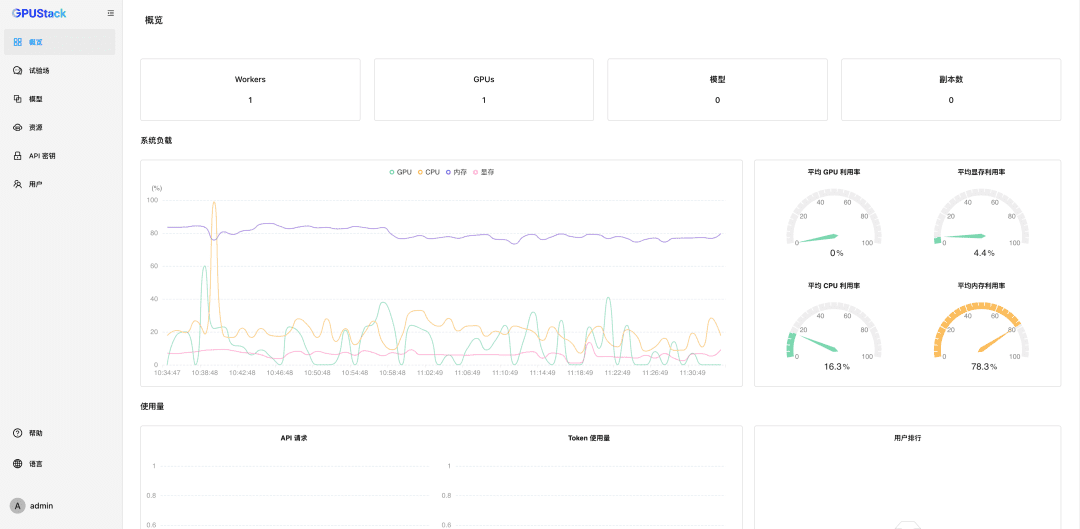
Наноуправление ресурсами GPU
GPUStack поддерживает ресурсы GPU для устройств Linux, Windows и macOS и управляет этими ресурсами GPU, выполняя следующие действия.
Другие узлы должны быть аутентифицированы Токен Присоединитесь к кластеру GPUStack и выполните следующую команду на узле GPUStack Server, чтобы получить токен:
на Linux или macOS:cat /var/lib/gpustack/token
В Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Получив токен, выполните следующую команду на других узлах, чтобы добавить рабочего в GPUStack и управлять GPU на этих узлах (замените http://YOUR_IP_ADDRESS на адрес доступа к GPUStack, а YOUR_TOKEN - на токен аутентификации, использованный для добавления рабочего):
на Linux или macOS:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
В Windows:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
С помощью описанных выше шагов мы создали среду GPUStack и управляем несколькими узлами GPU, которые затем можно использовать для развертывания частных больших моделей.
Развертывание частных макромоделей
Посетите GPUStack и разверните модели в меню Models. GPUStack поддерживает развертывание моделей из HuggingFace, Ollama Library, ModelScope и частных репозиториев моделей; ModelScope рекомендуется для домашних сетей.
Поддержка GPUStack vLLM и llama-box, vLLM оптимизирован для производственного анализа и лучше подходит для производственных нужд с точки зрения параллелизма и производительности, но vLLM поддерживается только в Linux. llama-box - это гибкий, совместимый с несколькими платформами механизм анализа, который является llama.cpp Он поддерживает системы Linux, Windows и macOS и поддерживает не только GPU, но и CPU для работы с большими моделями, что делает его более подходящим для сценариев, требующих мультиплатформенной совместимости.
При развертывании модели GPUStack автоматически выбирает подходящий бэкенд для вывода данных в зависимости от типа файла модели. GPUStack использует llama-box в качестве бэкенда для запуска службы модели, если модель имеет формат GGUF, и vLLM в качестве бэкенда для запуска службы модели, если она имеет не-GGUF формат.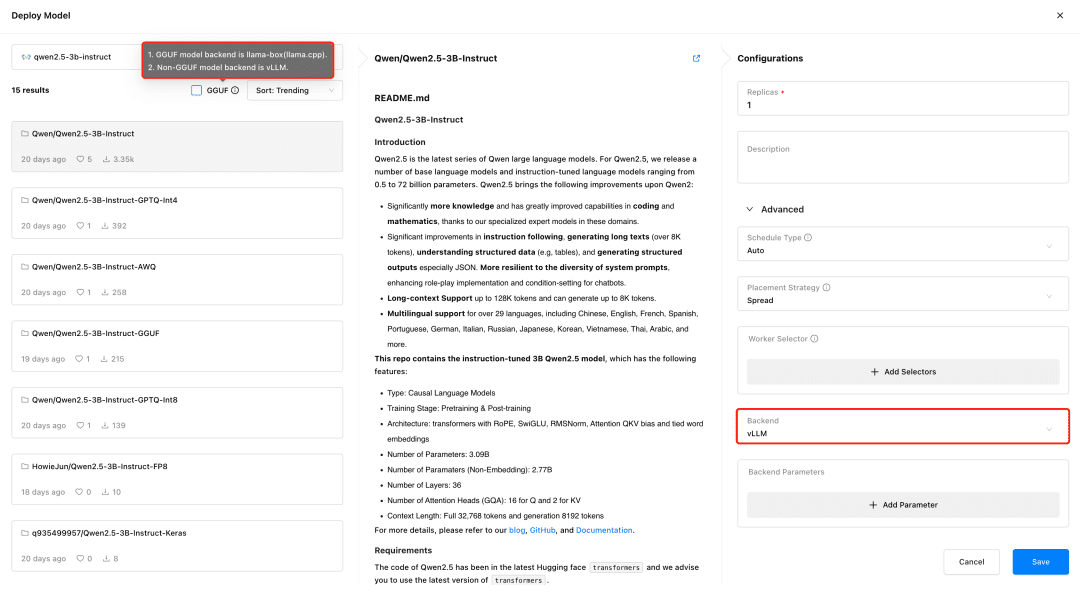
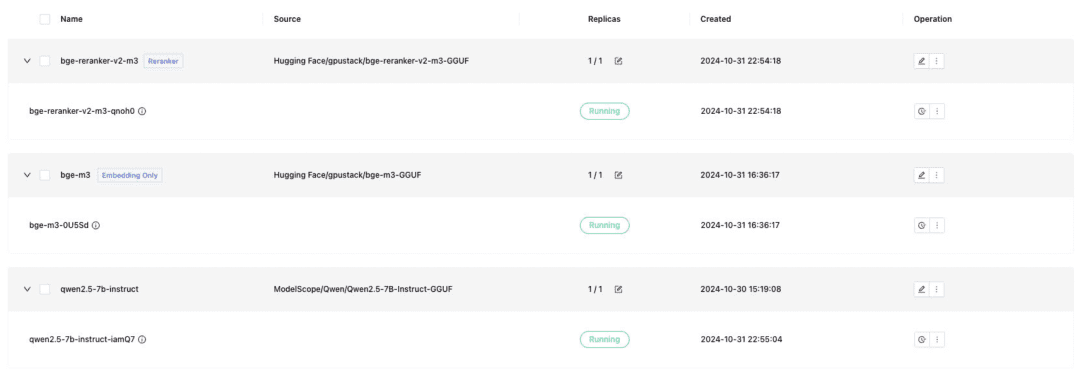
Разверните модель текстового диалога, модель встраивания текста Embedding и модель Reranker, необходимые для стыковки с Dify, и не забудьте проверить формат GGUF при развертывании:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack также поддерживает мультимодальные модели VLM, для развертывания которых необходимо использовать бэкэнд vLLM inference:
Qwen2-VL-2B-Instruct 

После развертывания модели система RAG или другое приложение генеративного ИИ может взаимодействовать с развернутой моделью GPUStack через OpenAI / Jina совместимый API, предоставляемый GPUStack, а затем Dify для взаимодействия с развернутой моделью GPUStack.
Модели Dify Integration GPUStack
Установите Dify
Чтобы запустить Dify с помощью Docker, необходимо подготовить среду Docker и быть внимательным, чтобы избежать конфликта между Dify и портом 80 в GPUStack, использовать другие хосты или изменить порт. Выполните следующую команду для установки Dify:git clone -b 0.10.1 https://github.com/langgenius/dify.gitПосетите интерфейс пользовательского интерфейса Dify по адресу http://localhost, чтобы инициализировать учетную запись администратора и войти в систему.
cd dify/docker/
cp .env.example .env
docker compose up -d
Чтобы интегрировать модель GPUStack, сначала добавьте модель диалога Chat, в правом верхнем углу Dify выберите "Настройки - Поставщики моделей", найдите в списке тип GPUStack и выберите Добавить модель:
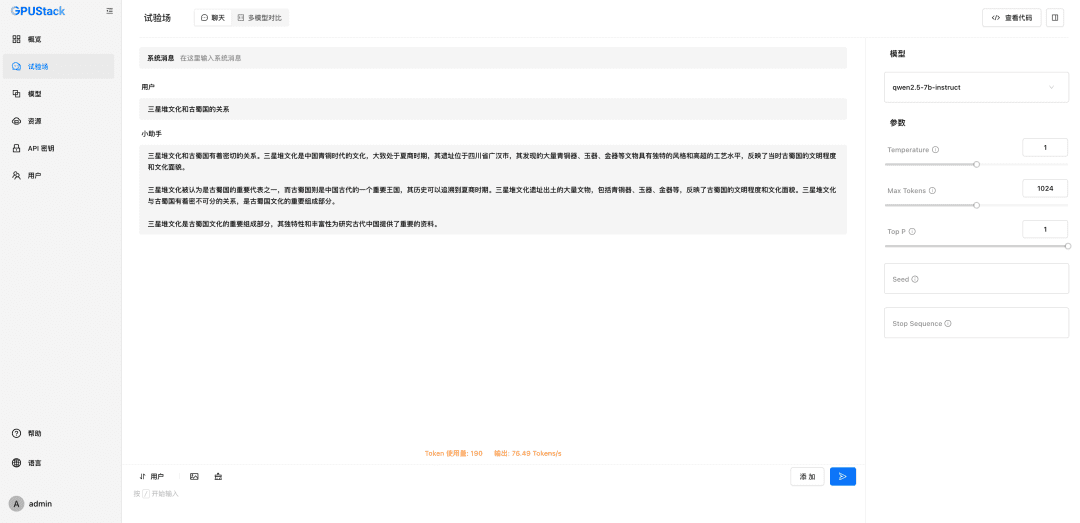
Заполните имя LLM-модели, развернутой на GPUStack (например, qwen2.5-7b-instruct), адрес доступа GPUStack (например, http://192.168.0.111) и сгенерированный API-ключ, а также контекстные длины параметров модели 8192 и max. жетоны 2048: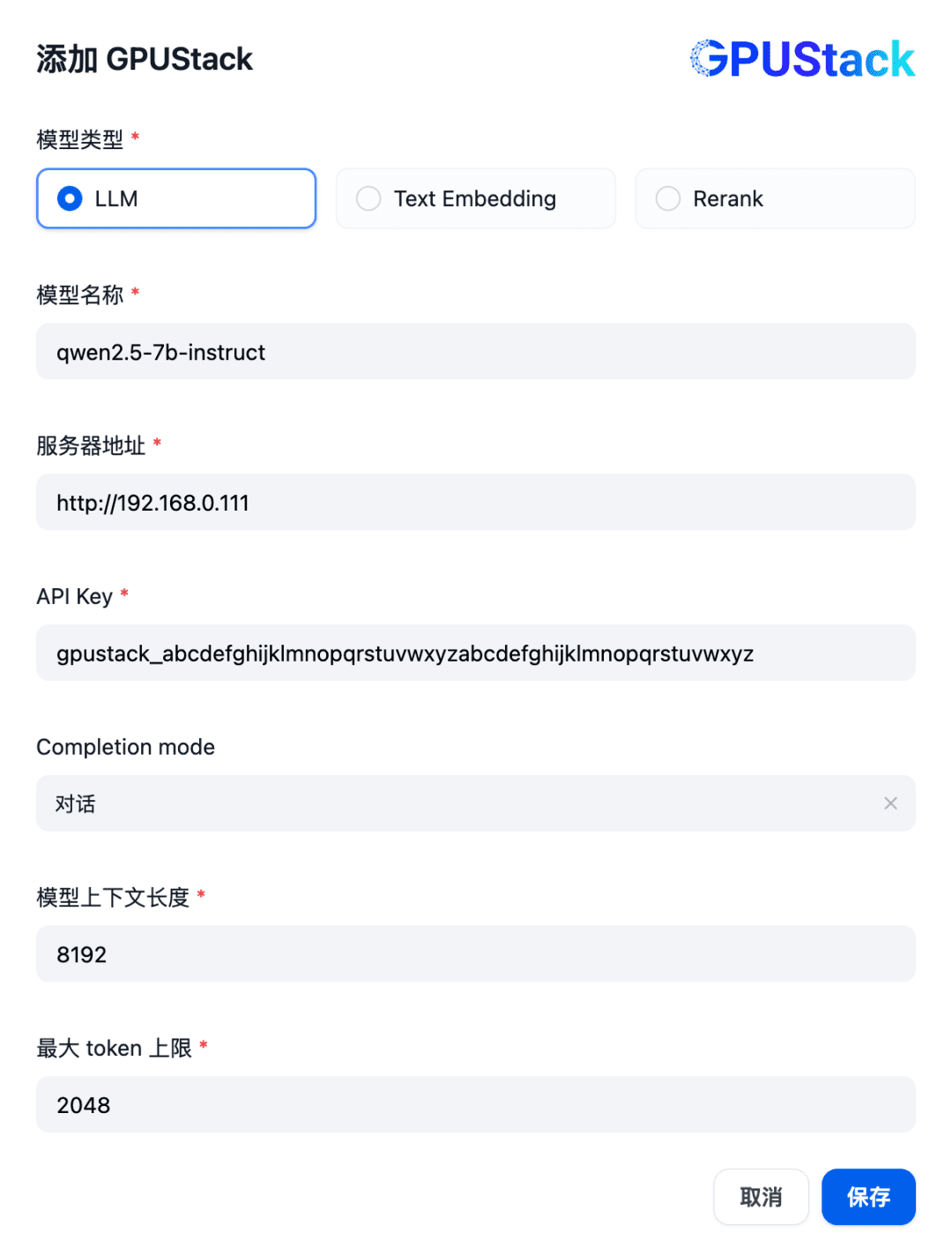
Затем добавьте модель Embedding, в верхней части Model Provider выберите тип GPUStack и выберите Add Model: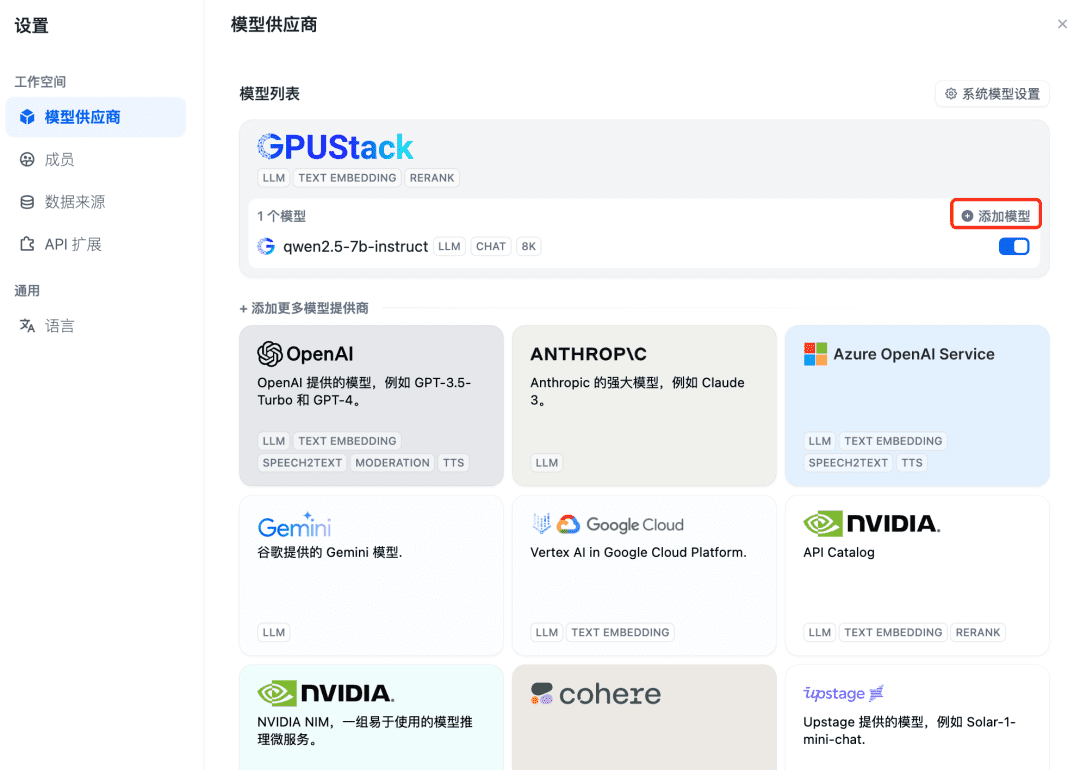
Добавьте модель типа Text Embedding, заполнив имя модели Embedding, развернутой на GPUStack (например, bge-m3), адрес доступа GPUStack (например, http://192.168.0.111) и сгенерированный ключ API, а также значение длины контекста 8192 для настроек модели: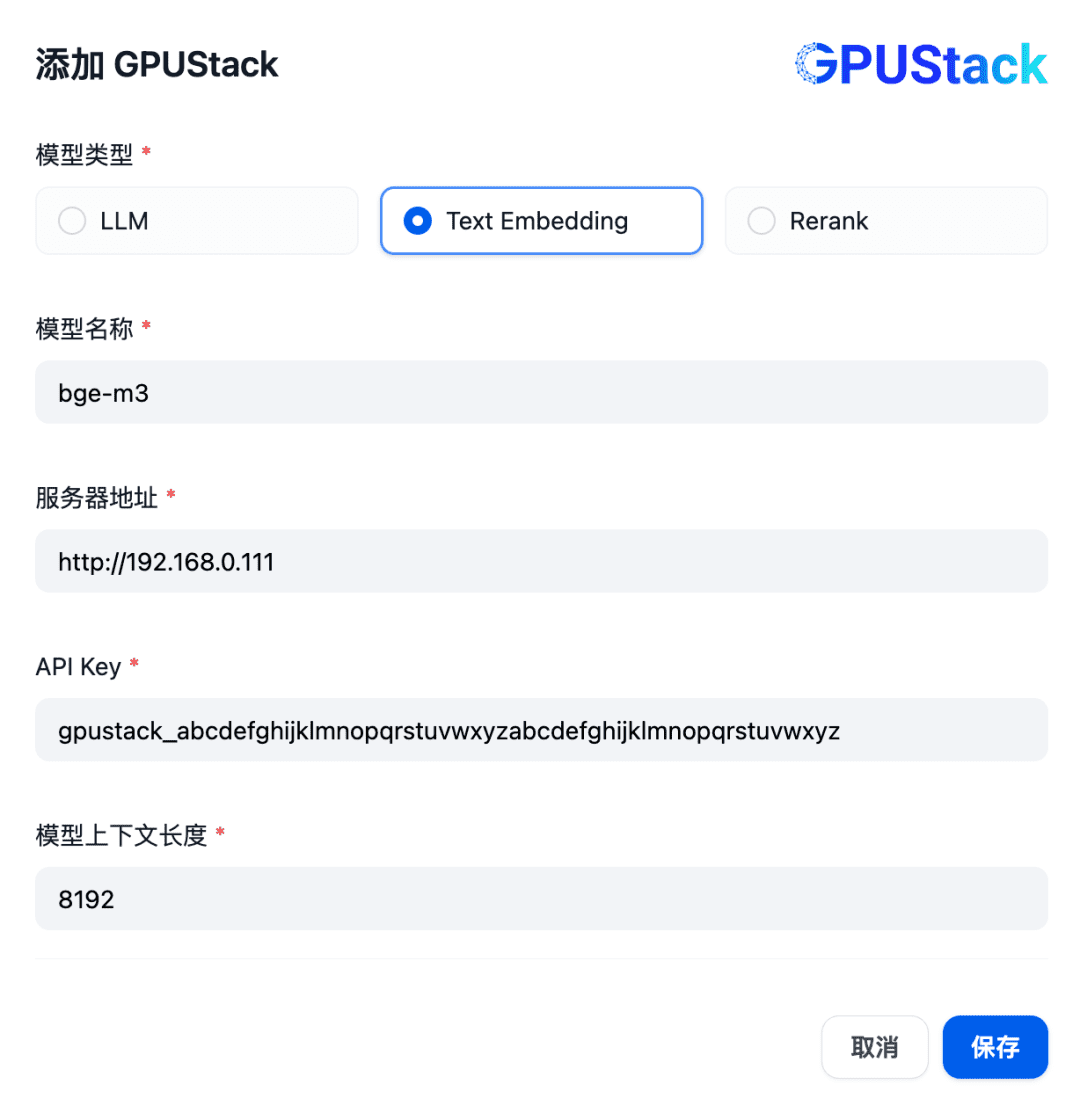
Далее, чтобы добавить модель Rerank, выберите тип GPUStack, выберите Add Model, добавьте модель типа Rerank, заполните имя модели Rerank, развернутой на GPUStack (например, bge-reranker-v2-m3), адрес доступа GPUStack (например, http://192.168. 0.111) и сгенерированный API-ключ, а также длина контекста 8192 для настроек модели: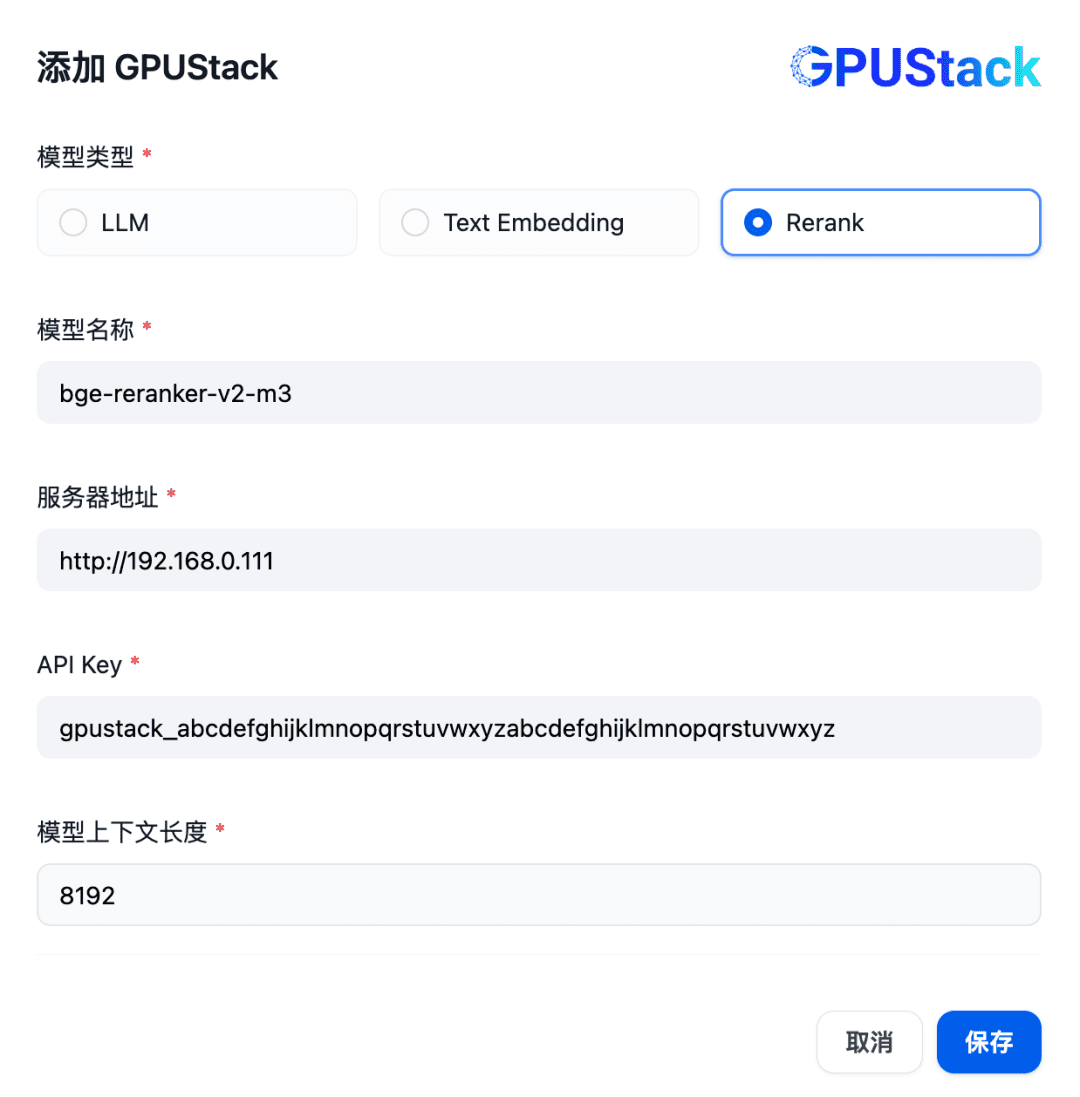
Обновите после добавления, а затем подтвердите в Model Provider, что модели системы настроены для трех моделей, добавленных выше: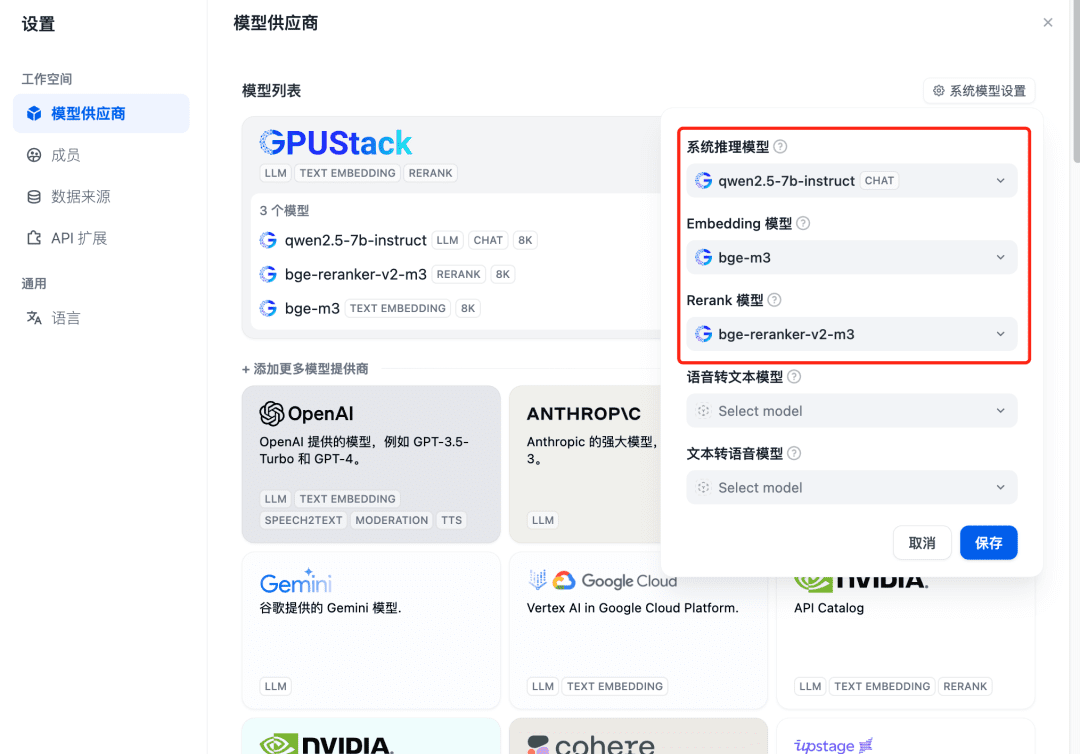
Использование моделей в системе RAG Выберите Базу знаний Dfiy, выберите Создать базу знаний, импортируйте текстовый файл, подтвердите опцию Встраивание модели, используйте рекомендуемый гибридный поиск для параметров поиска и включите модель Rerank: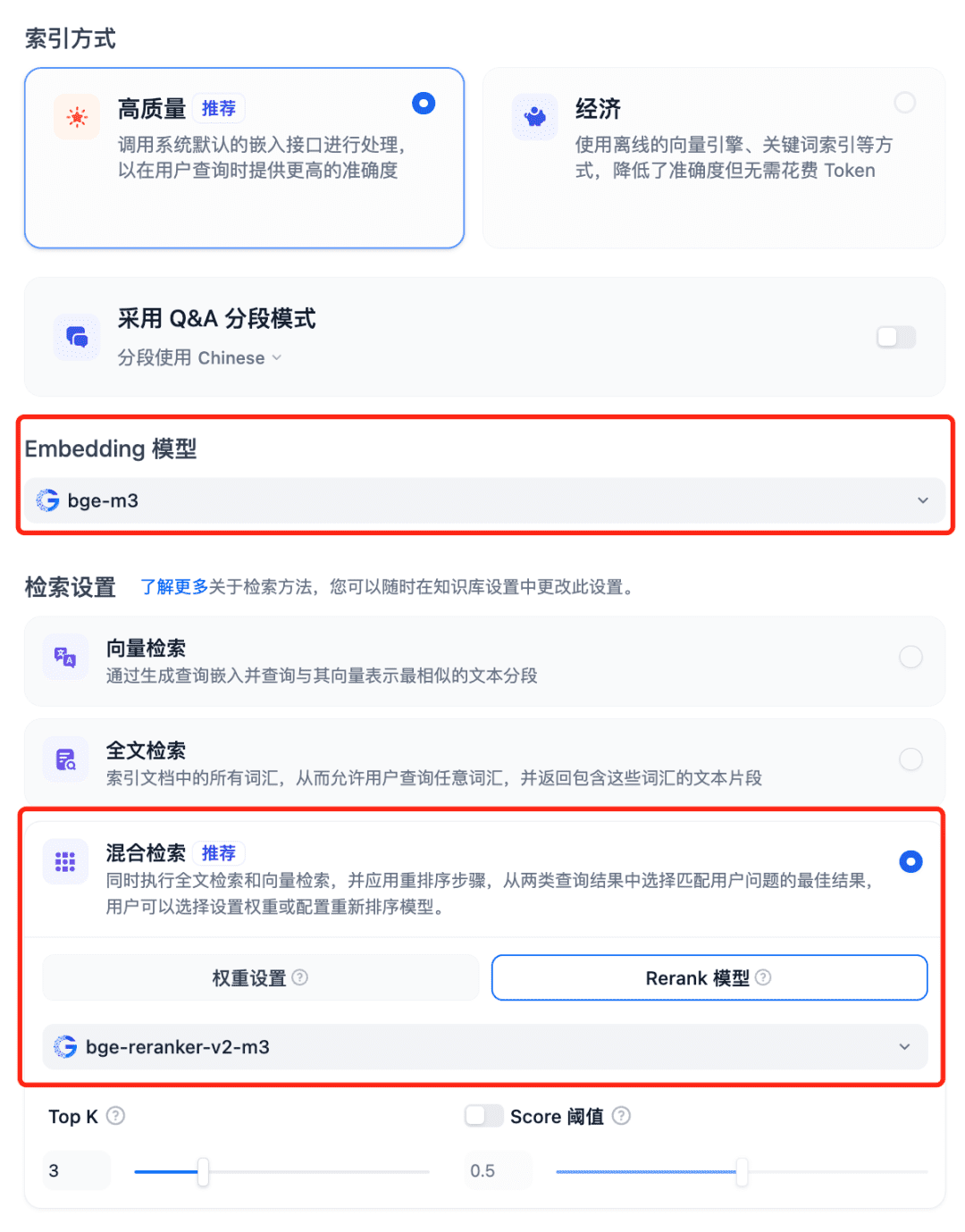
Сохраните и начните процесс векторизации документа. После завершения векторизации база знаний будет готова к использованию.
Тестирование Recall может быть использовано для подтверждения эффективности запоминания базы знаний, а модель Rerank будет доработана для запоминания более релевантных документов, чтобы достичь лучших результатов запоминания: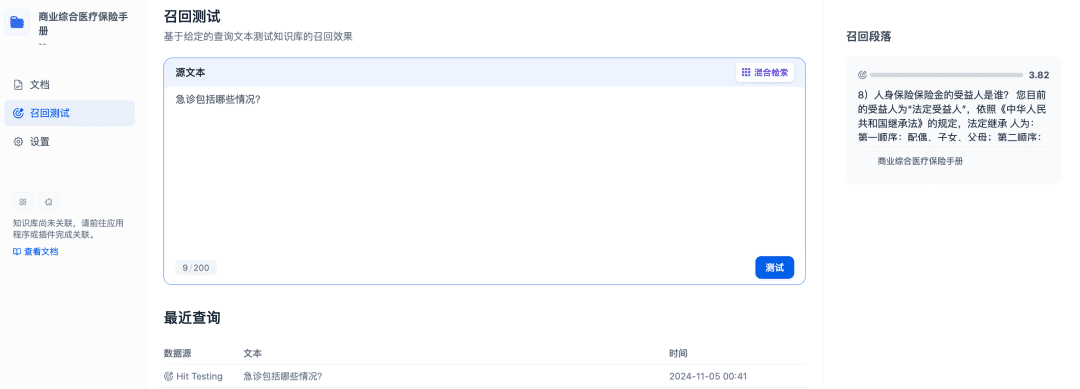
Затем создайте в чате приложение-ассистент: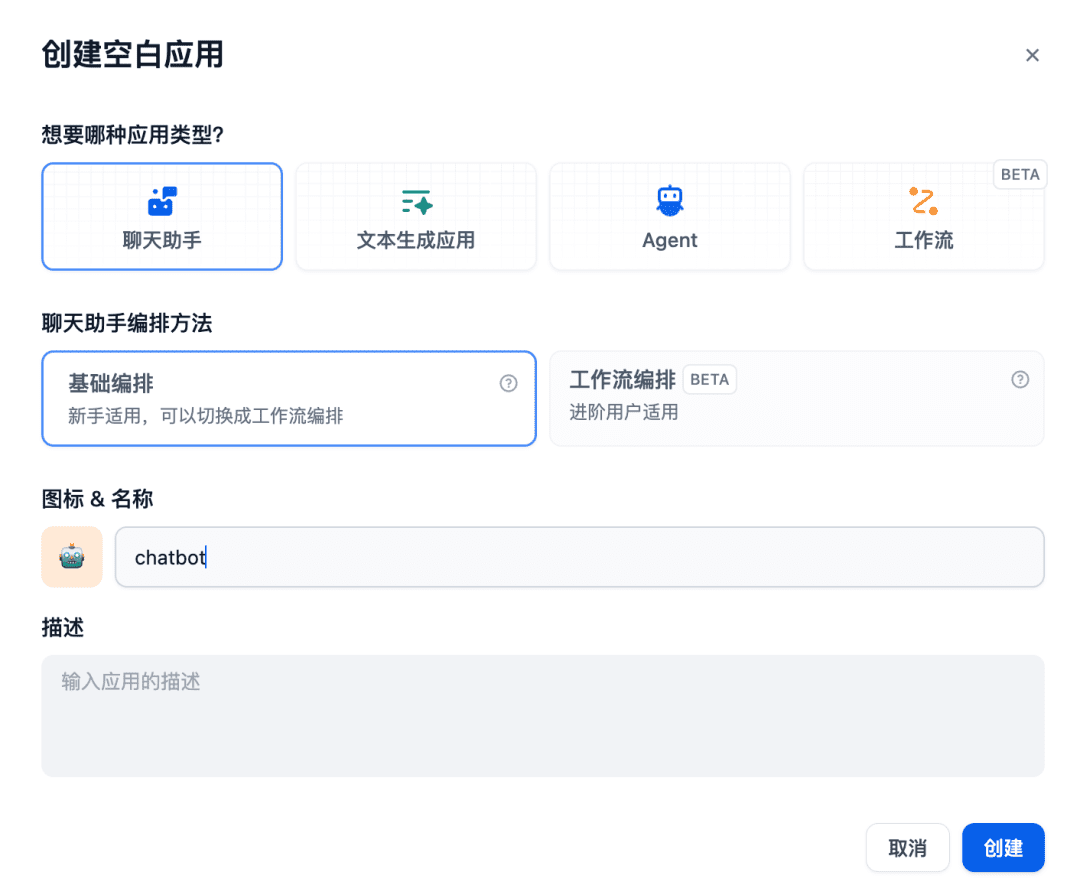
Соответствующая база знаний добавляется в используемый контекст, и в этот момент модель чата, модель встраивания и модель реранкера работают вместе для поддержки приложения RAG, при этом модель встраивания отвечает за векторизацию, модель реранкера - за тонкую настройку содержания отзыва, а модель чата - за ответ на основе содержания вопроса и контекста отзыва: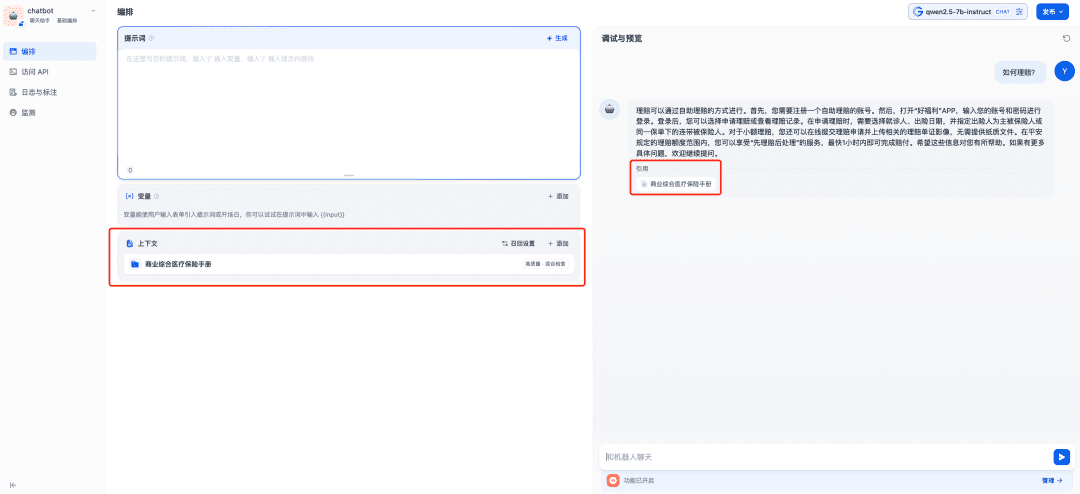
Выше приведен пример использования Dify для взаимодействия с моделями GPUStack. Другие системы RAG также могут взаимодействовать с GPUStack через API, совместимые с OpenAI / Jina, и использовать преимущества различных моделей Chat, Embedding и Reranker, развернутых платформой GPUStack для поддержки систем RAG.
Ниже приводится краткое описание функции GPUStack.
Особенности GPUStack
- Поддержка гетерогенных GPU: поддержка гетерогенных ресурсов GPU, в настоящее время поддерживаются Nvidia, Apple Metal, Huawei Rise и Moore Threads и другие типы GPU/NPU.
- Поддержка нескольких бэкендов: поддерживаются бэкенды vLLM и llama-box (llama.cpp), с учетом требований к производительности и совместимости с несколькими платформами.
- Мультиплатформенная поддержка: поддерживает платформы Linux, Windows и macOS, охватывая архитектуры amd64 и arm64.
- Поддержка нескольких типов моделей: поддерживает различные типы моделей, такие как текстовая модель LLM, мультимодальная модель VLM, модель встраивания текста Embedding и модель переупорядочивания Reranker.
- Поддержка мультимодельных репозиториев: поддержка развертывания моделей из HuggingFace, Ollama Library, ModelScope и частных репозиториев моделей.
- Богатые политики автоматического/ручного планирования: поддерживаются различные политики планирования, такие как компактное планирование, децентрализованное планирование, планирование с заданными тегами рабочих, планирование с заданным GPU и т. д.
- Распределенный вывод: если один GPU не может выполнить большую модель, можно использовать функцию распределенного вывода GPUStack для автоматического запуска модели на нескольких GPU на разных хостах.
- Рассуждения на CPU: если GPU нет или ресурсов GPU недостаточно, GPUStack может использовать ресурсы CPU для запуска больших моделей, поддерживая два режима рассуждений на CPU: гибридные рассуждения GPU&CPU и рассуждения на CPU.
- Сравнение нескольких моделей: GPUStack в Игровая площадка Представление сравнения нескольких моделей позволяет сравнивать содержание вопросов и ответов и данные о производительности нескольких моделей одновременно, чтобы оценить эффект от использования различных моделей, различных весов, различных параметров Prompt, различных квантификаций, различных графических процессоров и различных бэкендов для вывода.
- Наблюдаемые данные GPU и LLM: предоставляет комплексные показатели производительности, использования, мониторинга состояния и данных об использовании для оценки использования GPU и LLM.
GPUStack предоставляет все функции корпоративного класса, необходимые для создания частной крупной платформы model-as-a-service. Будучи проектом с открытым исходным кодом, он требует очень простой установки и настройки, и может быть использован для создания частной крупной платформы model-as-a-service из коробки.
резюме
Выше представлен учебник по установке GPUStack и интеграции моделей GPUStack с помощью Dify, адрес проекта с открытым исходным кодом: https://github.com/gpustack/gpustack.
GPUStack - это недорогой, простой в использовании, готовый к использованию инструмент.платформа с открытым исходным кодомОна поможет предприятиям быстро интегрировать и использовать разнородные ресурсы GPU, а также в кратчайшие сроки создать частную платформу корпоративного уровня по модели "большая модель как услуга".
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...