Sesame выпускает модель разговорной речи CSM: повышение естественности голосового взаимодействия с ИИ

В недавнем блоге Брендана Ириба, Анкита Кумара и команды Sesame описывается последнее исследование компании в области генерации разговорной речи - модель разговорной речи (Conversational Speech Model, CSM). CSM). Модель призвана устранить недостаток эмоций и естественности в текущем общении с голосовыми помощниками, приблизив голосовое взаимодействие ИИ к человеческому уровню.
Пересечение "долины ужаса" в поисках "присутствия голоса".
Команда Sesame считает, что голос - самое интимное средство общения для человека и содержит огромное количество информации, выходящей далеко за рамки буквального смысла. Однако существующие голосовые помощники часто лишены эмоциональной выразительности и имеют ровный тон, что затрудняет установление глубокой связи с пользователями. При длительном использовании таких голосовых помощников пользователи не только испытывают разочарование, но и усталость.
Чтобы решить эту проблему, Sesame разработала концепцию "присутствия голоса", которая означает, что голосовое взаимодействие должно быть реальным, понятным и ценным, а модель CSM - это ключевой шаг на пути к этой цели. Команда Sesame подчеркивает, что они создают не просто инструмент, а партнера по диалогу, который выстраивает доверительные отношения с пользователем.
Добиться "присутствия голоса" - задача не из легких и требует сочетания следующих ключевых элементов:
- Эмоциональный интеллект: Распознавать и реагировать на изменения в настроении пользователя.
- Динамика диалога: Поймите естественный ритм диалога, включая темп речи, паузы, перерывы и акценты.
- Ситуационная осведомленность: Подстройка тона и выражения к различным сценариям диалога.
- Последовательная личность: Поддерживайте постоянство и надежность личности ИИ-ассистента.
Модель CSM: одноэтапная, мультимодальная, более эффективная
Для достижения этих целей команда Sesame предложила новую модель разговорной речи, CSM, которая использует сквозную систему мультимодального обучения для создания более естественной и связной речи, используя информацию из истории разговора.
В отличие от традиционных моделей преобразования текста в речь (TTS), модель CSM работает непосредственно с лексемами RVQ (residual vector quantisation). Такая конструкция позволяет избежать информационного "узкого места", которое может быть вызвано семантическими лексемами в традиционных моделях TTS, что позволяет лучше улавливать нюансы речи.
CSM Архитектурный дизайн модели также весьма впечатляет. В ней используются два авторегрессионных трансформанта:
- Мультимодальная магистраль: Обработка чередующейся текстовой и аудиоинформации для предсказания нулевого уровня кодовой книги RVQ.
- Аудиодекодер: Используя различные линейные заголовки для каждой кодовой книги, оставшиеся N-1 слоев предсказываются для восстановления речи.
Такая конструкция позволяет декодеру быть намного меньше магистрали, что обеспечивает генерацию речи с низкой задержкой при сохранении сквозной модели.

Процесс вывода модели CSM
Кроме того, чтобы решить проблему узкого места в памяти в процессе обучения, команда Sesame предложила схему распределения вычислений. Эта схема обучает аудиодекодер только на случайном подмножестве аудиокадров, что значительно сокращает потребление памяти, не влияя на производительность модели.

Распределение учебного процесса
Экспериментальные результаты: близко к человеческому уровню, но все же есть отставание
Команда Sesame обучила модель CSM на наборе данных, содержащем около 1 миллиона часов английских аудиозаписей, и использовала различные метрики для тщательной оценки работы модели.
Результаты оценки показывают, что модель CSM близка к человеческому уровню в традиционных метриках Word Error Rate (WER) и Speaker Similarity (SIM).
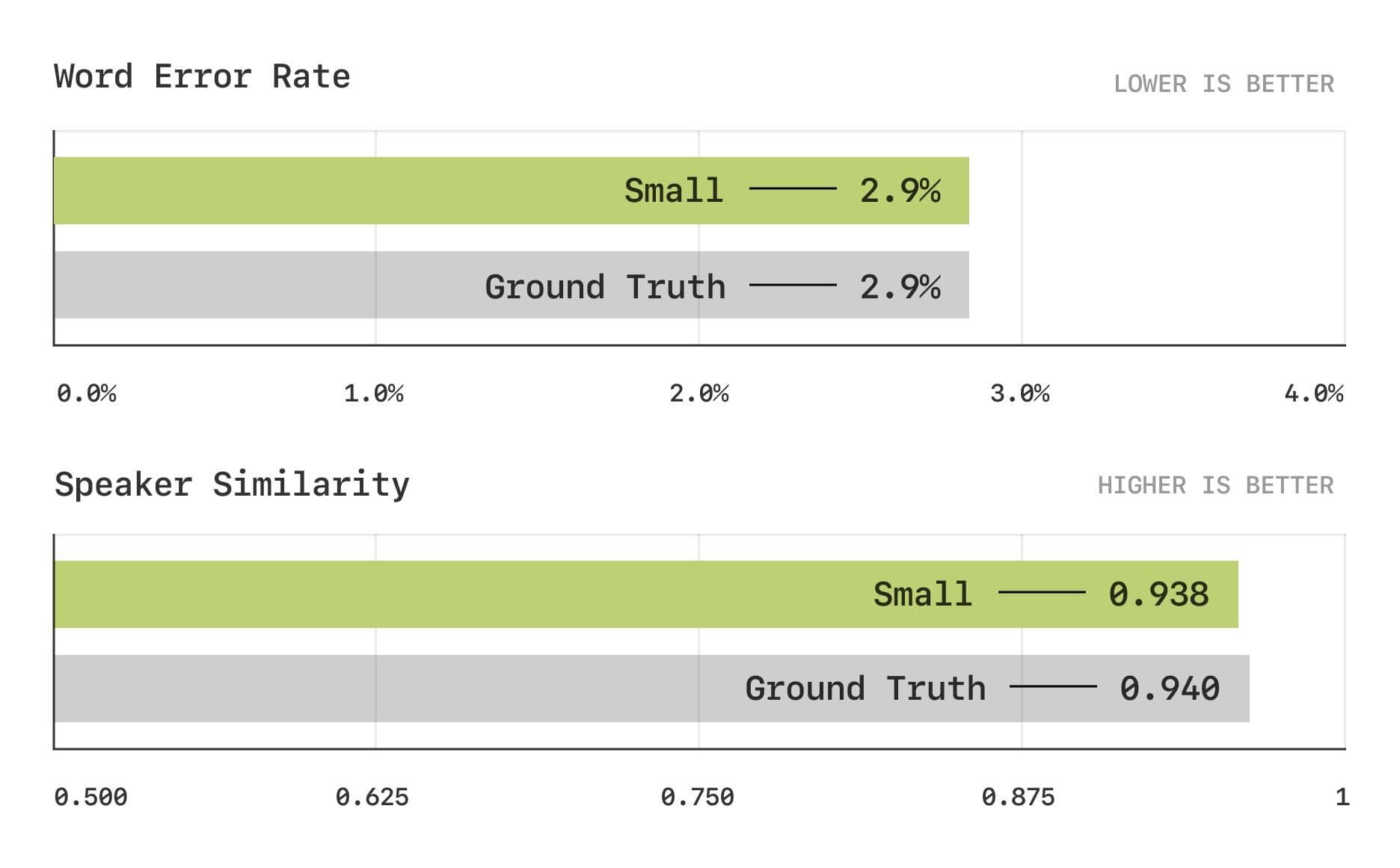
Тесты на количество ошибок в словах и сходство с диктором
Для более глубокой оценки возможностей модели в области понимания произношения и контекста команда Sesame также представила новый набор эталонных тестов, основанных на транскрипции речи, включая тесты на распознавание омофонов и согласованность произношения. Результаты показывают, что модель CSM отлично справляется и с этими задачами, причем производительность повышается по мере увеличения размера модели.
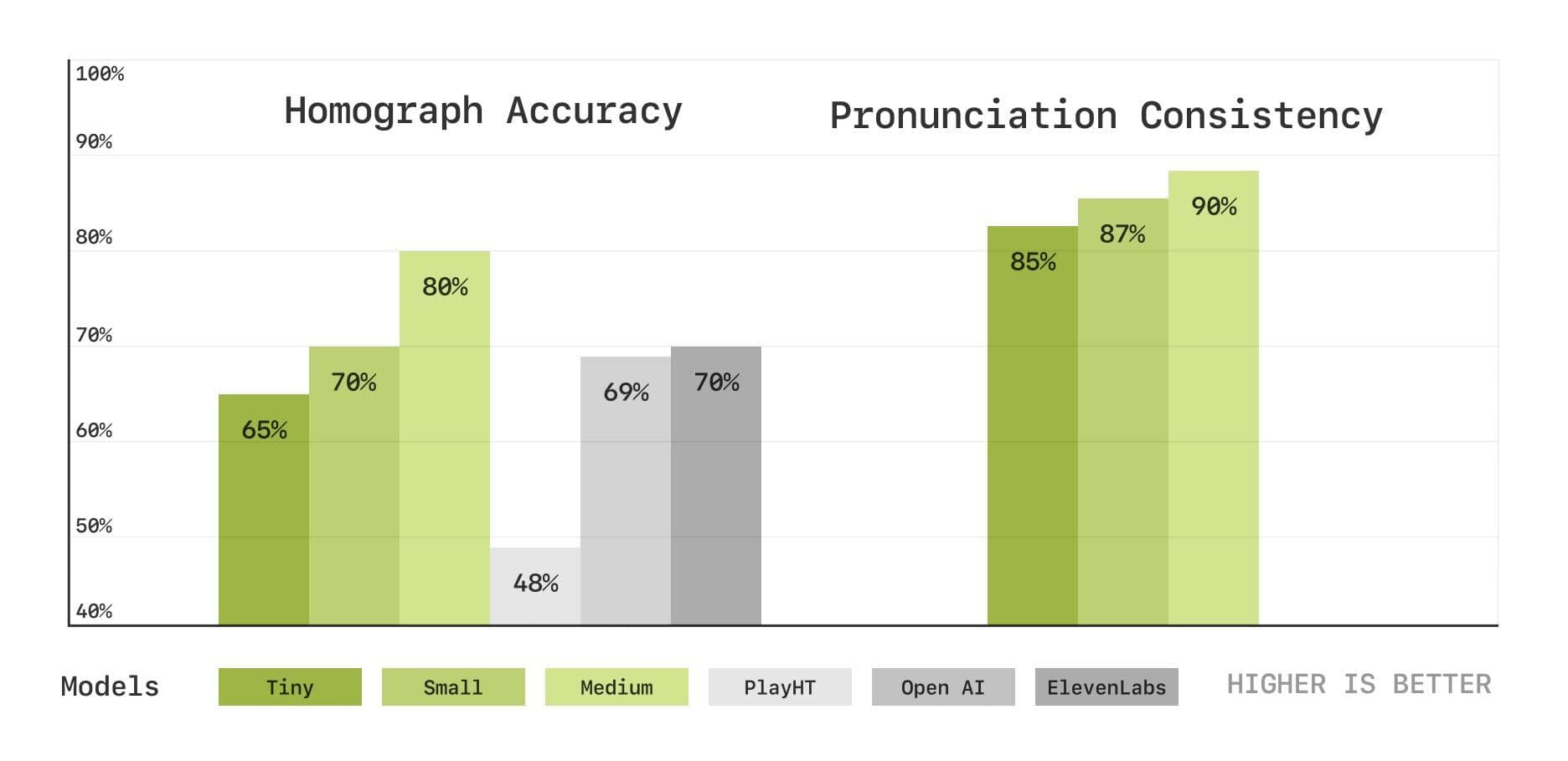
Тесты на определение омофонов и согласованность произношения
Однако между моделью CSM и реальной человеческой речью все еще существует разрыв с точки зрения субъективной оценки. Команда Sesame провела два исследования сравнительной средней оценки мнений (CMOS) с использованием набора данных Expresso. Результаты показали, что без контекста слушатели отдавали сопоставимые предпочтения речи, сгенерированной CSM, и реальной человеческой речи. Однако, когда слушателям предоставлялась контекстная информация, они отдавали предпочтение реальной человеческой речи. Это говорит о том, что модели CSM еще есть куда совершенствоваться в улавливании тонких ритмических изменений в диалоге.
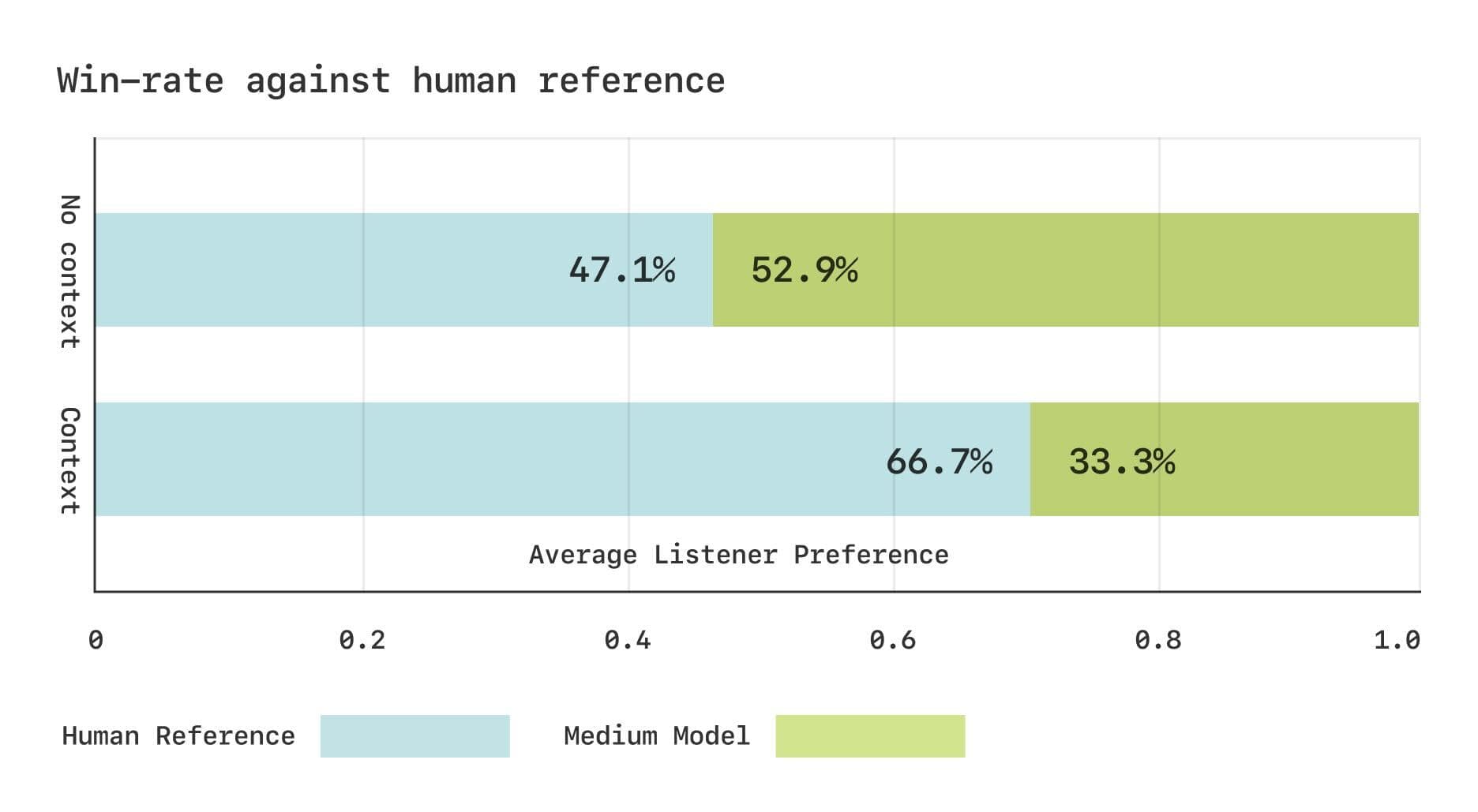
Результаты субъективной оценки набора данных Expresso
Совместное использование открытого исходного кода, перспективы на будущее
В духе открытого кода команда Sesame планирует открыть ключевые компоненты модели CSM для взаимного развития сообщества.
https://github.com/SesameAILabs/csm
Хотя модель CSM добилась значительного прогресса, она все еще имеет некоторые ограничения, такие как поддержка в основном английского языка, а многоязычные возможности необходимо улучшить. Команда Sesame заявила, что в будущем они продолжат увеличивать размер модели, увеличивать объем набора данных, расширять поддержку языков и исследовать использование языковых моделей предварительного обучения для дальнейшего улучшения производительности модели CSM. Команда Sesame уверена в будущем направлении своих исследований. Команда Sesame уверена, что будущее ИИ-диалогов - за полнодуплексными моделями, то есть моделями, которые могут неявно изучать динамику диалога на основе данных.
В целом, модель CSM, выпущенная Sesame, - это важный шаг вперед в области генерации разговорной речи, предоставляющий новые идеи для создания более естественных и эмоциональных голосовых взаимодействий ИИ. Несмотря на то, что еще есть куда совершенствоваться, дух открытого исходного кода и планы команды Sesame на будущее заслуживают внимания.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...