
Масштабирование вычислений по времени тестирования: цепочка размышлений о векторных моделях

С тех пор как OpenAI выпустила модель o1.Масштабирование вычислений в тестовое время(Scaling Reasoning) стала одной из самых горячих тем в кругах ИИ. Проще говоря, вместо того чтобы накапливать вычислительные мощности на этапе предварительного или последующего обучения, лучше потратить больше вычислительных ресурсов на этапе вывода (т. е. когда большая языковая модель генерирует вывод). o1 Модель разбивает большую задачу на серию маленьких задач (т. е. Chain-of-Thought), так что модель может думать, как человек, шаг за шагом оценивая различные возможности, осуществляя более детальное планирование, размышляя над собой, прежде чем дать ответ, и т. д. Модель может затем использоваться для оценки различных возможностей, более детального планирования и выдачи ответа. Модели позволено думать как человек, оценивая различные возможности, осуществляя более детальное планирование, размышляя над собой, прежде чем дать ответ, и т. д. Таким образом, модель не нужно переучивать, а производительность может быть улучшена только за счет дополнительных вычислений во время рассуждений.Вместо того чтобы заставлять модель заучивать, заставьте ее больше думать.-- Эта стратегия особенно эффективна в сложных задачах вывода и позволяет значительно улучшить результаты, и недавний выпуск компанией Alibaba модели QwQ подтверждает эту технологическую тенденцию: улучшение возможностей модели за счет расширения вычислений во время вывода.
👩🏫 Под масштабированием в данной статье понимается увеличение вычислительных ресурсов (например, арифметических или временных) в процессе рассуждений. Оно не относится к горизонтальному масштабированию (распределенные вычисления) или ускоренной обработке (сокращение времени вычислений).

Если вы также использовали модель o1, то наверняка почувствуете, что многоступенчатые рассуждения занимают больше времени, поскольку для решения задачи необходимо выстраивать цепочки размышлений.
В Jina AI мы больше внимания уделяем эмбеддингам и реранкерам, чем большим языковым моделям (LLM), поэтому, естественно, мы придумали:Можно ли применить концепцию "цепочки мыслей" и к модели Embedding?
Хотя на первый взгляд это может показаться не совсем интуитивным, в данной статье мы рассмотрим новый взгляд и продемонстрируем, как масштабирование вычислений в тестовое время может быть применено кjina-clipдля того, чтобы лучше понять Сложные изображения вне домена (OOD) Классификация проводится для решения невыполнимых задач.
Мы экспериментировали с распознаванием покемонов, которое все еще остается довольно сложным для векторных моделей. Такая модель, как CLIP, хотя и сильна в сопоставлении изображений и текстов, имеет тенденцию сворачиваться, когда она сталкивается с данными вне домена (OOD), которые модель не видела раньше.
Однако мы обнаружили, чтоТочность классификации внедоменных данных может быть повышена за счет увеличения времени вывода модели и использования многоцелевой стратегии классификации, подобной цепочке мышления, которая не требует настройки модели.
Пример из практики: классификация изображений покемонов
🔗 Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
Мы использовали набор данных TheFusion21/PokemonCards, содержащий тысячи изображений карточек покемонов.Это задача классификации изображенийкоторый вводит обрезанную колоду покемонов (с удаленным текстовым описанием) и выводит правильное название покемона. Но это сложно для модели CLIP Embedding по нескольким причинам:
- Названия и внешний вид покемонов относительно новы для модели, и легко скатиться до прямого категоризирования.
- У каждого покемона есть свои визуальные характеристикиКЛИПы становятся более понятными, например, формы, цвета и позы.
- Стиль карт единый, хотяНо разные фоны, позы и стили рисования добавляют сложности..
- Эта задача требуетРассматривайте несколько визуальных особенностей одновременнокак и сложная цепочка мыслей в LLM.

Мы убрали всю текстовую информацию (название, нижний колонтитул, описание) с карточек, чтобы модели не жульничали и не находили ответы прямо из текста, ведь обозначения классов этих покемонов - это их названия, например Absol, Aerodactyl.
Базовая методология: прямое сравнение сходства
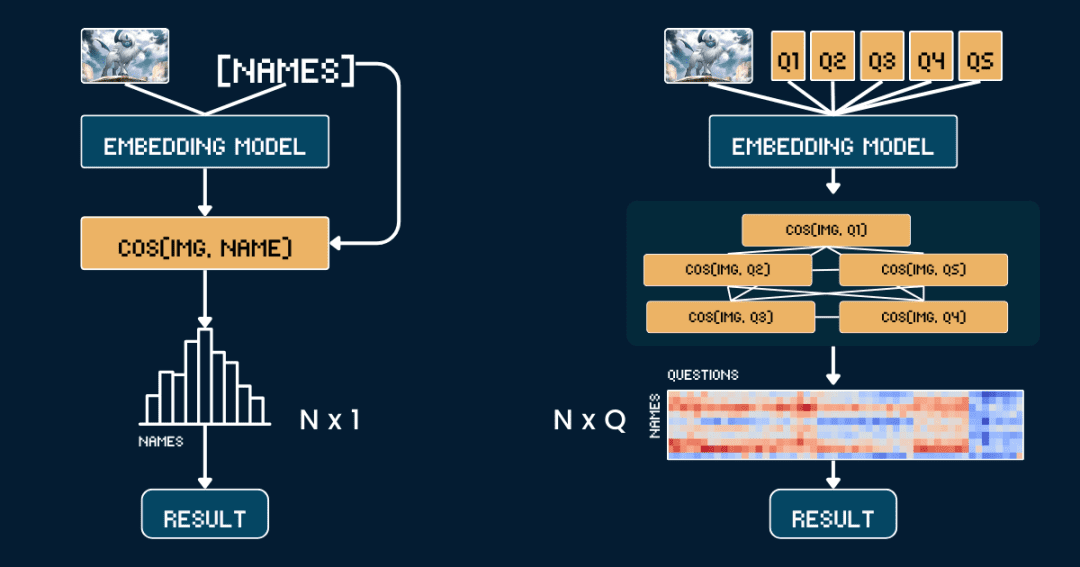
Начнем с самой простой базовой методологии. Прямое сравнение сходства между изображениями и названиями покемонов.
Во-первых, лучше удалить из карточек всю текстовую информацию, чтобы модели CLIP не приходилось угадывать ответ непосредственно из текста. Затем мы используем jina-clip-v1 ответить пением jina-clip-v2 Модель кодирует изображение и название покемона отдельно, чтобы получить их соответствующие векторные представления. Наконец, вычисляется косинусоидальное сходство между векторами изображения и текста, и то имя, которое имеет наибольшее сходство, считается тем покемоном, который изображен на картинке.
Такой подход эквивалентен сопоставлению изображения и имени один к одному, без учета какой-либо другой контекстной информации или атрибутов. Следующий псевдокод кратко описывает этот процесс.
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
Продвинутый вариант: применение цепочек мышления для классификации изображений
На этот раз, вместо того чтобы сопоставлять картинки и имена, мы разделили идентификацию покемонов на несколько частей, как в игре "Pokémon Connect".
Мы определили пять наборов ключевых атрибутов: основной цвет (например, "белый", "синий"), основная форма (например, "волк", "крылатая рептилия"), ключевые признаки (например, "белый рог", "большие крылья"), размер тела (например, "четвероногая форма волка"). крылатая рептилия"), ключевые особенности (например, "белый рог", "большие крылья"), размер тела (например, "четвероногий волк ", "крылатый и стройный"), а также фоновые сцены (например, "космическое пространство", "зеленый лес").
Для каждого набора признаков мы разработали специальное слово-подсказку, например "Тело этого покемона в основном {} окрашено", а затем заполнили возможные варианты.Далее мы используем модель для расчета оценок сходства изображения и каждого варианта и преобразуем их в вероятности с помощью функции softmax, которая дает более точную оценку достоверности модели.
Полная цепочка мышления (CoT) состоит из двух частей:classification_groups ответить пением pokemon_rulesПервый определяет структуру вопросов: каждому атрибуту (например, цвету, форме) соответствует шаблон вопроса и набор возможных вариантов ответа. Вторая записывает, какие варианты должны быть подобраны для каждого покемона.
Например, цвет Абсола должен быть "белый", а его форма - "волчья". О том, как построить полную структуру CoT, мы поговорим позже, а приведенная ниже pokemon_system - это конкретный пример CoT:
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
Короче говоря, вместо того, чтобы просто сравнивать сходства, мы теперь делаем несколько сравнений, комбинируя вероятности каждого атрибута, чтобы мы могли вынести более обоснованное суждение.
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
Анализ сложности двух методов
Теперь давайте проанализируем сложность: предположим, мы хотим найти среди N имен покемонов имя, которое лучше всего соответствует заданному изображению:
Базовый метод требует вычисления N текстовых векторов (по одному для каждого имени) и 1 вектора изображения, а затем N вычислений сходства (векторы изображений сравниваются с каждым текстовым вектором).Таким образом, сложность эталонного метода в основном зависит от количества вычислений N текстовых векторов.
И наш метод CoT должен вычислить Q текстовых векторов, где Q - общее количество всех комбинаций вопрос-вариант, и 1 вектор картинки. После этого необходимо произвести Q вычислений сходства (сравнение векторов картинок с векторами текста для каждой комбинации вопрос-вариант).Таким образом, сложность метода зависит в основном от Q.
В данном примере N = 13 и Q = 52 (5 групп признаков со средним числом вариантов около 10 в каждой группе). Оба метода нуждаются в вычислении векторов изображений и выполнении шагов классификации, и мы округляем эти общие операции при сравнении.
В крайнем случае, если Q = N, то наш метод фактически превращается в эталонный. Таким образом, ключ к эффективному расширению времени вычислений в режиме вывода заключается в следующем:
Разработайте задачу, чтобы увеличить значение Q. Убедитесь, что каждый вопрос содержит полезные подсказки, которые помогут нам сузить круг поиска. Лучше не дублировать информацию между вопросами, чтобы получить максимум информации.
Результаты
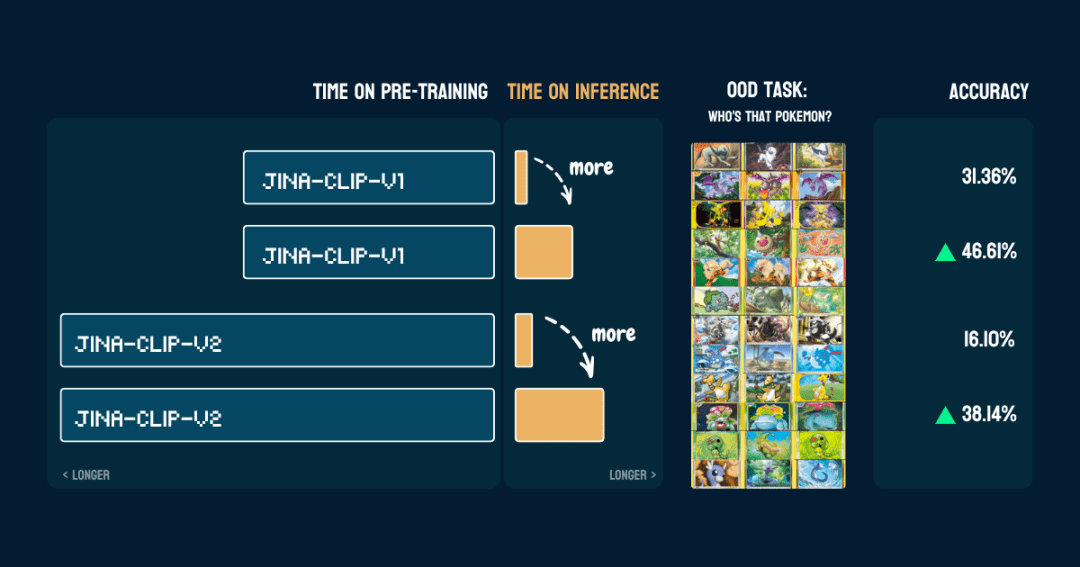
Мы оценили его на 117 тестовых изображениях, содержащих 13 различных покемонов. Результаты точности следующие:

Он также показывает, что послеpokemon_systemОн построен правильно.Один и тот же CoT можно использовать непосредственно на другой модели без изменения кода, тонкой настройки и дополнительного обучения.
Интересно.jina-clip-v1Базовая точность модели при классификации покемонов выше (31,36%), поскольку она была обучена на наборе данных LAION-400M, содержащем данные о покемонах. В то время как jina-clip-v2Модель была обучена на DFN-2B, который является более качественным набором данных, но также отфильтровывает больше данных и, вероятно, удаляет контент, связанный с покемонами, поэтому его базовая точность ниже (16,10%).
Подождите, как работает этот метод?
👩🏫 Давайте рассмотрим, что мы сделали.
Мы начали с фиксированных предварительно обученных векторных моделей, которые не могли справиться с проблемами нераспространения (OOD) при нулевых выборках. Но когда мы построили дерево классификации, они неожиданно смогли это сделать. В чем секрет этого? Может быть, это что-то вроде слабой интеграции обучаемых в традиционном машинном обучении? Стоит отметить, что наша векторная модель может превратиться из "плохой" в "хорошую" не благодаря интегрированному обучению как таковому, а благодаря внешним знаниям о домене, содержащимся в дереве классификации. Вы можете многократно классифицировать тысячи вопросов с нулевыми выборками, но если ответы не вносят вклад в конечный результат, это бессмысленно. Это похоже на игру "ты мне скажи, я угадаю" (двадцать вопросов), где нужно постепенно сужать круг решения с каждым вопросом. Таким образом, именно это внешнее знание или мыслительный процесс являются ключевыми- Как и в нашем примере, ключевым моментом является то, как построена система Pokemon.Эти знания могут быть получены от людей или от больших языковых моделей.
pokemon_systemкачество.Существует множество способов создания системы CoT, от ручного до полностью автоматизированного, каждый из которых имеет свои преимущества и недостатки.1. Ручное строительство
2. Строительство с помощью LLM
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLM быстро создает черновой вариант, но при этом требует ручной проверки и исправлений.
Более надежный подход заключается в следующем Комбинированная генерация LLM и ручная проверка. Сначала LLM генерирует первоначальную версию, затем вручную проверяет и изменяет группировки атрибутов, опции и правила, а затем передает изменения обратно в LLM, чтобы тот продолжил доработку до тех пор, пока не будет удовлетворен. Такой подход позволяет сбалансировать эффективность и точность.
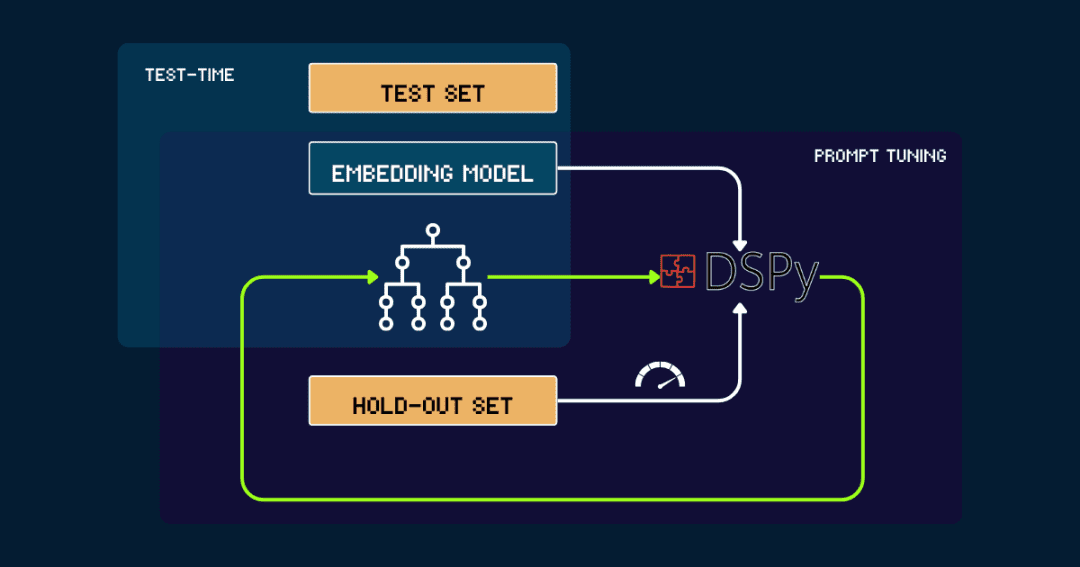
3. Автоматизированные сборки с помощью DSPy
Для полностью автоматизированных сборок pokemon_systemкоторые можно итеративно оптимизировать с помощью DSPy.
Давайте начнем с простого pokemon_system старт, созданный вручную или сгенерированный LLM. Затем он оценивается с помощью данных из набора исключений, сигнализируя DSPy о точности в качестве обратной связи. DSPy использует эту обратную связь для генерации нового pokemon_systemи повторяйте этот цикл до тех пор, пока производительность не сойдется и не будет достигнуто значительное улучшение.
Векторная модель фиксируется на протяжении всего процесса. С помощью DSPy можно автоматически найти оптимальный дизайн pokemon_system (CoT) и настраивать его только один раз для каждой задачи.
Зачем масштабировать вычисления времени тестирования на векторных моделях?
Это слишком дорого из-за необходимости постоянно увеличивать размер предварительно обученных моделей.
Коллекция Jina Embeddings, отjina-embeddings-v1, иv2, иv3 до (времени) jina-clip-v1, иv2И jina-ColBERT-v1, иv2При этом каждое обновление предполагает использование более крупных моделей, увеличение количества предварительно обученных данных и рост затрат.
взятьjina-embeddings-v1Для выпуска в июне 2023 года с 110 миллионами параметров обучение будет стоить от 5 000 до 10 000 долларов. К тому времени, когда jina-embeddings-v3, производительность значительно улучшилась, но это по-прежнему происходит в основном за счет выброса денег на ресурсы. Сейчас стоимость обучения топовых моделей выросла с тысяч долларов до десятков тысяч долларов, а крупным компаниям приходится тратить даже сотни миллионов долларов. Хотя чем больше инвестиций в предварительное обучение, тем лучше результаты модели, но стоимость слишком высока, рентабельность становится все ниже и ниже, при разработке конечной модели необходимо учитывать устойчивость.
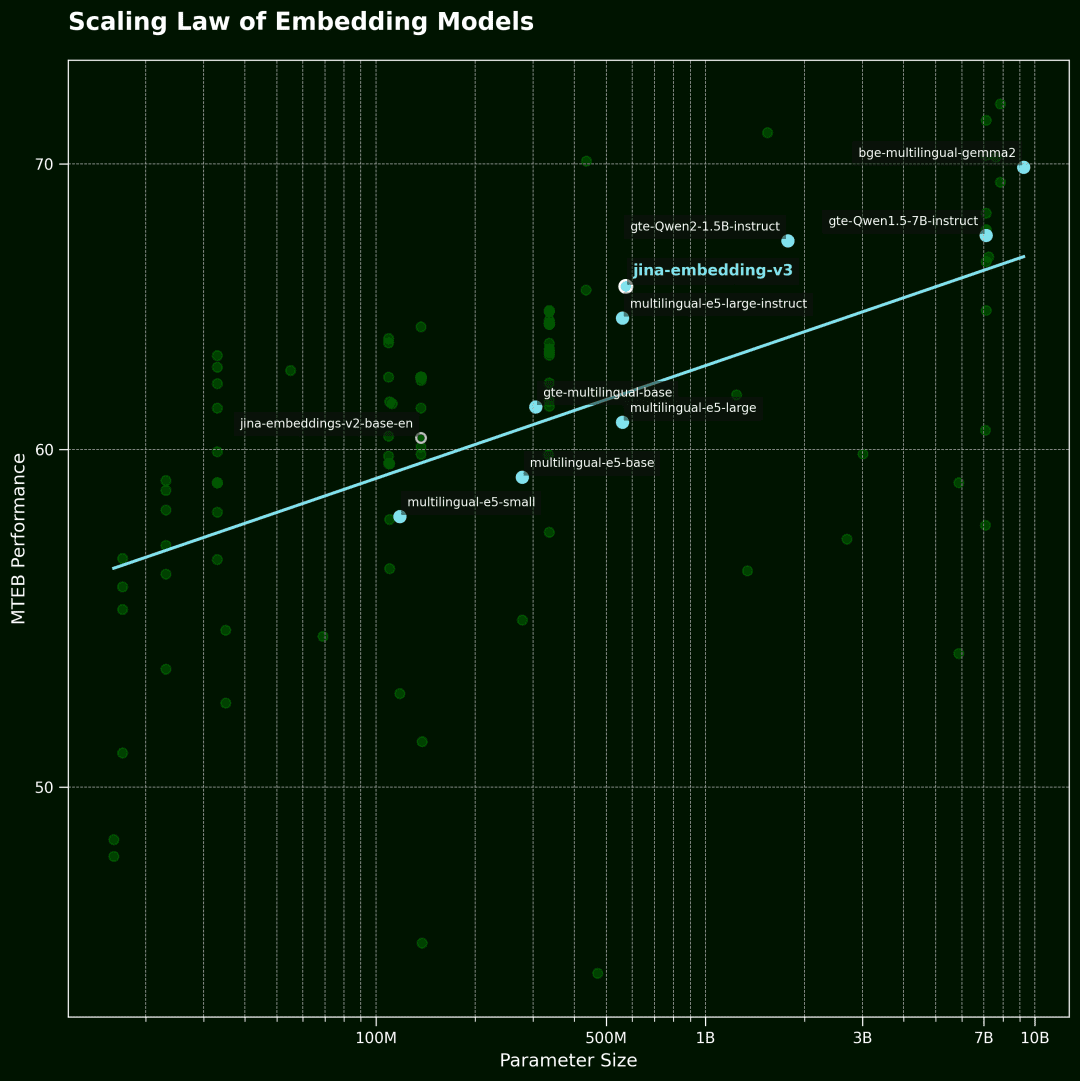
векторное моделирование Закон масштабирования
На этом рисунке показана векторная модель ScЗакон об алинге.Горизонтальная ось - количество параметров модели, а вертикальная - средняя производительность MTEB. Каждая точка представляет собой векторную модель. Линия тренда представляет собой среднее значение для всех моделей, а синие точки - это многоязычные модели.
Данные были отобраны из 100 лучших векторных моделей в рейтинге MTEB. Для обеспечения качества данных мы отсеяли модели, которые не раскрыли информацию о размере модели, а также некоторые недействительные заявки.
С другой стороны, векторные модели сегодня очень мощные: многоязычные, многозадачные, мультимодальные, с отличными возможностями обучения с нулевым образцом и следования инструкциям.Такая универсальность открывает широкие возможности для алгоритмических улучшений и расширений вычислений в момент вывода.
Главный вопрос заключается в следующем:Сколько пользователи готовы заплатить за запрос, который их действительно интересует? Если простое увеличение времени вывода данных для фиксированной предварительно обученной модели может значительно улучшить качество результатов, я уверен, что многие сочтут это целесообразным.
По нашему мнению.Вычисления с расширенным временем вывода обладают огромным неиспользованным потенциалом в области векторного моделированиячто, вероятно, станет важным прорывом для будущих исследований.Вместо того чтобы стремиться к расширению модели, лучше приложить больше усилий на этапе вывода и исследовать более интеллектуальные вычислительные методы для повышения производительности -- Это может быть более экономичным и эффективным способом.
вынести вердикт
существовать jina-clip-v1/v2 В ходе эксперимента мы наблюдали следующие ключевые явления:
мы О данных, не видимых моделью и находящихся за пределами домена (OOD)(математика) родБыли достигнуты лучшие показатели точности распознавания, при этом не потребовалось ни тонкой настройки, ни дополнительного обучения модели. Система работает следующим образом Итеративное уточнение критериев поиска и классификации сходстваЭто позволяет добиться более тонкой дифференциации. представляя Динамическая настройка подсказок и итеративное рассуждение(аналог "цепочки мыслей"), мы превращаем процесс рассуждений векторной модели из одного запроса в более сложную цепочку мыслей.
Это только начало! Возможности масштабирования вычислений в тестовое время выходят далеко за рамки этого!Но еще остается огромное пространство для исследования. Например, мы можем разработать более эффективные алгоритмы для сужения пространства ответов путем итеративного выбора наиболее эффективной стратегии, подобно стратегии поиска оптимальных решений в игре "двадцать вопросов". Расширяя возможности вычислений во времени, мы можем продвинуть векторные модели за пределы существующих узких мест, разблокировать сложные и тонкие задачи, которые раньше казались недоступными, и продвинуть эти модели в более широкие приложения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...