
Как выбрать лучшую модель встраивания для приложений RAG


Векторное встраивание лежит в основе современных приложений Retrieval Augmented Generation (RAG). Они фиксируют семантическую информацию об объектах данных (например, текст, изображения и т. д.) и представляют их в виде массивов чисел. В современных приложениях генеративного ИИ эти векторные вкрапления обычно генерируются моделями вкраплений. Как выбрать подходящую модель Embedding для приложения RAG? В целом, это зависит от конкретного случая использования, а также от конкретных требований. Далее давайте разделим шаги, чтобы рассмотреть каждый из них в отдельности.
01. Определите конкретные варианты использования
Мы рассматриваем следующие вопросы в соответствии с требованиями RAG:
Во-первых, достаточно ли типовой модели для удовлетворения потребностей?
Во-вторых, есть ли особые потребности? Например, модальность (например, только текст или изображение, для мультимодальных вариантов встраивания см.Как выбрать подходящую модель встраивания"), конкретные области (например, юриспруденция, медицина и т.д.)
В большинстве случаев для нужных режимов выбирается типовая модель.
02. Выбор типовых моделей
Как выбрать модель общего назначения? В таблице лидеров Massive Text Embedding Benchmark (MTEB) в HuggingFace перечислены различные существующие модели встраивания текста с открытым исходным кодом, и для каждой модели в MTEB указаны различные показатели, включая параметры модели, память, размеры встраивания, максимальное количество лексем, а также их оценки в таких задачах, как поиск и обобщение.
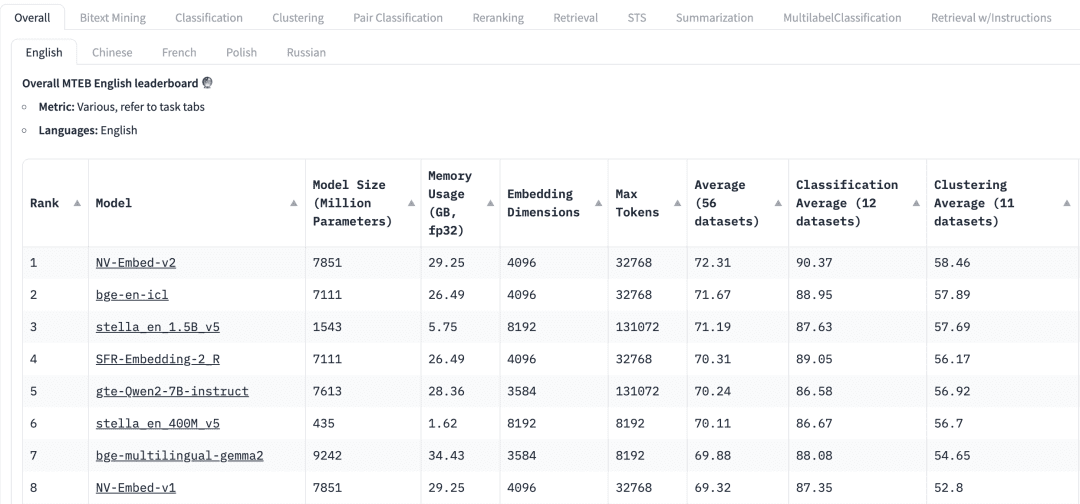
При выборе модели встраивания для приложения RAG необходимо учитывать следующие факторы:
мандаты: В верхней части таблицы лидеров MTEB мы увидим различные вкладки задач. Для приложения RAG нам может понадобиться больше внимания на задаче "Получить", где мы можем выбрать Retrial Эта вкладка.
многоязычие: На основе языка набора данных, в котором применяется RAG, выбирается модель встраивания для соответствующего языка.
оценка: Указывает на производительность модели на определенном эталонном наборе данных или на нескольких эталонных наборах данных. В зависимости от задачи используются различные метрики оценки. Как правило, эти метрики принимают значения от 0 до 1, причем более высокие значения указывают на лучшую производительность.
Размер модели и использование памяти: Эти показатели дают нам представление о вычислительных ресурсах, необходимых для работы модели. Хотя производительность поиска улучшается с увеличением размера модели, важно отметить, что размер модели также напрямую влияет на задержку. Кроме того, большие модели могут быть слишком хорошо подогнаны и иметь низкую эффективность обобщения, поэтому плохо работают в производстве. Поэтому нам необходимо найти баланс между производительностью и задержкой в производственной среде. В общем, мы можем начать с небольшой, легкой модели и быстро построить приложение RAG. После того как базовый процесс приложения будет работать должным образом, мы можем перейти к более крупной, высокопроизводительной модели для дальнейшей оптимизации приложения.
Размеры встраивания: Это длина вектора встраивания. Хотя большие размеры встраивания позволяют уловить более тонкие детали в данных, результаты не всегда оптимальны. Например, действительно ли нам нужно 8192 размера для данных о документах? Скорее всего, нет. С другой стороны, меньшая размерность Embedding обеспечивает более быстрое формирование выводов и более эффективна с точки зрения хранения и памяти. Таким образом, необходимо найти оптимальный баланс между передачей содержимого данных и эффективностью выполнения.
Максимальное количество жетонов: указывает на максимальное количество токенов для одного Embedding. Для обычных приложений RAG оптимальным размером фрагмента для встраивания обычно является один абзац, и в этом случае модели встраивания с максимальным количеством лексем 512 будет достаточно. Однако в некоторых особых случаях нам могут понадобиться модели с большим количеством лексем для работы с длинными текстами.
03. Оценка моделей в приложениях RAG
Несмотря на то, что мы можем найти типовые модели в списках лидеров MTEB, к их результатам следует относиться с осторожностью. Учитывая, что эти результаты предоставляются моделями самостоятельно, возможно, что некоторые модели показывают завышенные результаты, поскольку они могли включить наборы данных MTEB в свои обучающие данные, которые, в конце концов, являются общедоступными. Кроме того, наборы данных, которые модели используют для бенчмаркинга, могут не совсем точно представлять данные, используемые в нашем приложении. Поэтому нам необходимо оценить модели Embedding на наших собственных наборах данных.
3.1 Наборы данных
Мы можем сгенерировать небольшой набор данных с метками из данных, используемых приложением RAG. В качестве примера возьмем следующий набор данных.
| Язык | Описание |
|---|---|
| C/C++ | Язык программирования общего назначения, известный своей производительностью и эффективностью. Он предоставляет возможности низкоуровневого манипулирования памятью и широко используется при разработке систем/программного обеспечения, игр и приложений, требующих высокой производительности. |
| Java | Универсальный объектно-ориентированный язык программирования, созданный для того, чтобы иметь как можно меньше зависимостей от реализации. Он широко используется для создания Благодаря своей переносимости и надежности он широко используется для создания корпоративных приложений, мобильных приложений (особенно Android) и веб-приложений. |
| Python | Высокоуровневый интерпретируемый язык программирования, известный своей читабельностью и простотой. Он поддерживает множество парадигм программирования и широко Поддерживает множество парадигм программирования и широко используется в веб-разработке, анализе данных, искусственном интеллекте, научных вычислениях и автоматизации. |
| JavaScript | Динамический язык программирования высокого уровня, используемый в основном для создания интерактивного и динамического контента в Интернете. Является основной технологией для Этот язык является основной технологией для фронтенд-веб-разработки и все чаще используется на стороне сервера с помощью таких сред, как Node.js. |
| C# | Он используется для разработки широкого спектра приложений, включая веб-приложения, настольные, мобильные и игры, особенно в рамках экосистемы Microsoft. Он используется для разработки широкого спектра приложений, включая веб-приложения, настольные, мобильные и игры, в частности в экосистеме Microsoft. |
| SQL | Язык, используемый для программирования и управления реляционными базами данных. Он необходим для запросов, обновления и управления данными в базах данных. Он необходим для запросов, обновления и управления данными в базах данных и широко используется в анализе данных и бизнес-аналитике. |
| PHP | Он встраивается в HTML и широко используется для создания динамических веб-страниц и приложений, широко представленных в системах управления контентом, таких как WordPress. Приложения, широко представленные в системах управления контентом, таких как WordPress. |
| Golang | Статически типизированный компилируемый язык программирования, разработанный компанией Google. Известный своей простотой и эффективностью, он используется для создания масштабируемых и высокопроизводительных приложений, особенно в облачных сервисах и распределенных системах. -производительности, особенно в облачных сервисах и распределенных системах. |
| Ржавчина | Язык системного программирования, ориентированный на безопасность и параллелизм. Обеспечивает безопасность памяти без использования сборщика мусора и используется для создания Обеспечивает безопасность памяти без использования сборщика мусора и используется для создания надежного и эффективного программного обеспечения, в частности, в системном программировании и веб-сборке. |
3.2 Создание встраивания
Далее мы используемpymilvus[model]Для вышеуказанного набора данных генерируется соответствующий вектор Embedding. о pymilvus[model] Как использовать, см. https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md.
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
Затем созданный эмбеддинг помещается в коллекцию Milvus.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Запросы
Мы определяем функции запроса, чтобы облегчить поиск вектора Embedding.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Оценка эффективности модели встраивания
Мы используем две модели эмбеддинга от OpenAI.text-embedding-3-small ответить пением text-embedding-3-largeСравниваются результаты для двух следующих запросов. Существует множество оценочных метрик, таких как точность, отзыв, MRR, MAP и т. д. Здесь мы используем точность и отзыв.
Точность Оценивает процент действительно релевантного контента в результатах поиска, т.е. сколько из возвращенных результатов соответствуют поисковому запросу.
Точность = TP / (TP + FP)
В этом случае истинно положительные результаты (TP) - это те, которые действительно соответствуют запросу, а ложноположительные результаты (FP) - это те, которые не соответствуют результатам поиска.
Recall оценивает количество релевантного контента, успешно извлеченного из всего набора данных.
Recall = TP / (TP + FN)
Ложные отрицательные результаты (ЛО) - это все релевантные элементы, которые не были включены в конечный набор результатов.
Для более подробного объяснения этих двух понятий
Запрос 1::auto garbage collection
Сопутствующие товары: Java, Python, JavaScript, Golang
| Рейтинг | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Ржавчина | ❎ Ржавчина |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Точность | 0.50 | 0.50 |
| Отзыв | 0.50 | 0.50 |
Запрос 2::suite for web backend server development
Смежные предметы: Java, JavaScript, PHP, Python (ответы включают субъективную оценку)
| Рейтинг | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Точность | 0.75 | 1.0 |
| Отзыв | 0.75 | 1.0 |
В этих двух запросах мы сравнили две модели встраивания по точности и вспоминаемости text-embedding-3-small ответить пением text-embedding-3-large Модель Embedding можно использовать в качестве отправной точки. Мы можем использовать ее в качестве отправной точки для увеличения количества объектов данных в наборе данных, а также количества запросов, чтобы модель Embedding можно было оценить более эффективно.
04. Резюме
В приложениях Retrieval Augmented Generation (RAG) выбор подходящих моделей векторного встраивания имеет решающее значение. В этой статье мы показываем, что после выбора общей модели из MTEB на основе реальных бизнес-требований, точность и отзыв используются для тестирования модели на основе конкретного бизнес-данных, чтобы выбрать наиболее подходящую модель встраивания, которая, в свою очередь, эффективно улучшает точность отзыва в приложении RAG.
Полный код доступен для скачивания
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...