
Освоение RAG Document Chunking: руководство по стратегиям объединения документов для создания эффективных поисковых систем

Если ваш RAG Приложение не приносит желаемых результатов, так что, возможно, пришло время пересмотреть стратегию разбивки на части.Лучшая разбивка на части означает более точный поиск, что в конечном итоге приводит к более качественным ответам.
Тем не менее, разбивка на части - это не универсальный подход, и ни один из них не является абсолютно оптимальным. Необходимо рассмотреть и выбрать наиболее подходящую стратегию в соответствии с конкретными потребностями проекта, характеристиками документа, бюджетом и другими факторами.
Почему качество чанкинга напрямую влияет на качество ответов RAG?
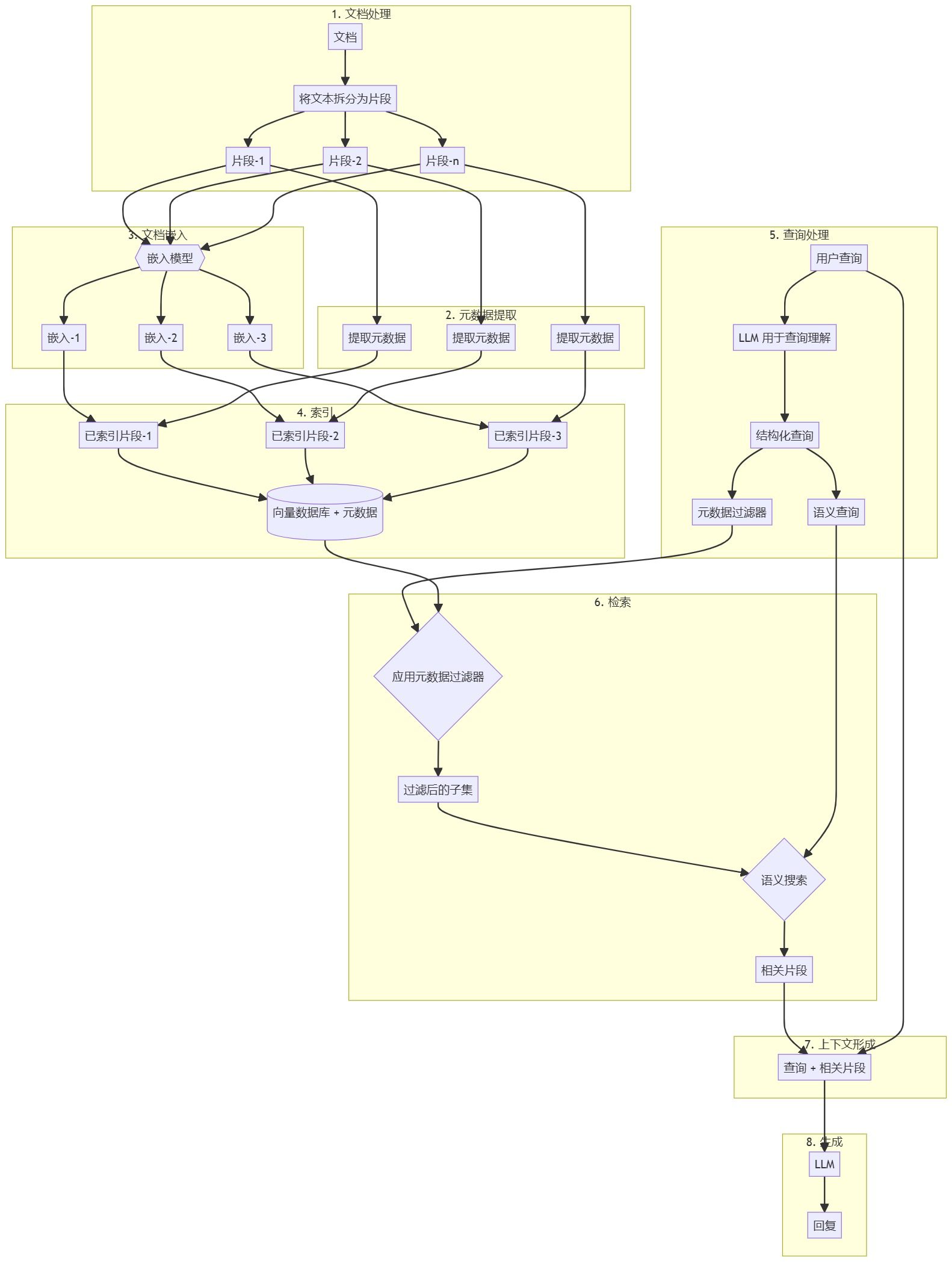
Я уверен, что к моменту прочтения этой статьи у вас есть представление о базовых понятиях chunking и RAG. Вкратце напомним, что основная идея RAG заключается в том, чтобы сделать LLM Ответьте на вопросы, основываясь на данной контекстуальной информацииЭто связано с тем, что LLM обладает богатой базой знаний, но у нее есть задержка в обновлении знаний и нет прямого доступа к частным данным. Это связано с тем, что, хотя LLM и обладает богатой базой знаний, у нее есть задержка в обновлении своих знаний и нет прямого доступа к частным данным.
RAG компенсирует недостатки самого LLM, вводя в подсказки соответствующие фрагменты документов (т. е. контекст) и направляя LLM на генерацию ответов на основе этих фрагментов. Контекст может быть получен различными способами, например, с помощью запроса к базе данных, поиска в Интернете или извлечения из PDF-документов.
Создание эффективного приложения RAG сопряжено с двумя основными трудностями:
- Пределы контекстного окна для LLM: Ранние модели LLM, такие как GPT-2 и GPT-3, имели небольшие контекстные окна, что ограничивало объем текста, который можно было обработать за один проход. Хотя сейчас существуют модели, поддерживающие большие контекстные окна, это не означает, что мы можем просто запихнуть весь документ в LLM.
- проблема контекстного шумаДаже если контекстное окно LLM достаточно велико, если предоставленная контекстная информация содержит много контента (шума), который не имеет отношения к вопросу, это может повлиять на понимание и оценку LLM, что приведет к ухудшению качества ответа или даже к галлюцинациям.
Чтобы решить эти проблемы.Распределение документов по частямТак родилась технология. Основная идея заключается в разбиении больших документов на более мелкие, семантически связные сегменты (фрагменты), а затем на этапе поиска в качестве контекста, предоставляемого LLM, выбираются только наиболее релевантные фрагменты.
Существуют различные способы разбивки документов на части, такие как простая разбивка предложений и абзацев, сложная семантическая разбивка, агентивная разбивка и т. д. Важно выбрать подходящую стратегию разбивки, которая напрямую влияет на эффективность системы RAG и качество конечного ответа. Выбор подходящей стратегии чанкинга очень важен, он напрямую влияет на эффективность поиска системы RAG и качество конечного ответа.
В этой статье мы рассмотрим несколько более продвинутых и практичных стратегий разбиения документов на части, которые помогут вам создать более надежные приложения RAG. Мы пропустим простое разбиение на предложения и абзацы и сосредоточимся на методах, которые более ценны в реальных приложениях RAG.
Далее я подробно расскажу о нескольких стратегиях разбивки на части, которые я изучил и применяю на практике.
Рекурсивная сегментация символов: быстрый и экономичный базовый подход
Рекурсивное разделение символов - вы можете подумать, что это самый простой метод. Действительно, он является базовым, но, на мой взгляд, это одна из наиболее часто используемых и экономически эффективных техник разбиения на части. Ее легко понять, просто реализовать, она быстрая и недорогая, что делает ее особенно подходящей для быстрого создания прототипов и проектов, чувствительных к затратам.
Основная идея рекурсивной сегментации символов заключается в следующемИспользуйте скользящее окно фиксированного размераи допускает перекрытие окон. Он генерирует блоки текста, непрерывно сдвигая окно из начальной позиции документа с заданным размером блока и количеством перекрывающихся символов.
На следующем рисунке показано, как работает рекурсивная сегментация символов:
 Как работает рекурсивная сегментация символов - рисунок Thuwarakesh
Как работает рекурсивная сегментация символов - рисунок ThuwarakeshПреимущество рекурсивной сегментации символов заключается в ее простоте и эффективности. Она позволяет быстро обрабатывать большие документы и разбивать годовые отчеты на части на уровне минут. Реализовать рекурсивную сегментацию символов в Langchain очень просто:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text = """
Hydroponics is an intelligent way to grow veggies indoors or in small spaces. In hydroponics, plants are grown without soil, using only a substrate and nutrient solution. The global population is rising fast, and there needs to be more space to produce food for everyone. Besides, transporting food for long distances involves lots of issues. You can grow leafy greens, herbs, tomatoes, and cucumbers with hydroponics.
"""
rc_splits = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=20, chunk_overlap=2
).split_text(text)
Варианты раздвижных окон
На практике размер скользящего окна и шаг скольжения можно варьировать в зависимости от потребностей:
- Раздвижные окна на основе символов и токенов: Приведенный выше пример представляет собой скользящее окно на основе символов. Также можно использовать посимвольное Токен скользящее окно, чтобы обеспечить размер блоков, более соответствующий обработке LLM.Langchain's RecursiveCharacterTextSplitter Поддерживаются как символьный, так и маркерный режимы.
- Динамический размер окна:: Хотя для рекурсивной сегментации символов характерны фиксированные размеры окон, в некоторых сценариях можно рассматривать и динамическое изменение размеров окон. Например, адаптивная настройка размера окна в зависимости от длины предложения или структуры абзаца для обеспечения смысловой целостности блока.
ограничения
Рекурсивная сегментация символов - этоПодход, основанный на позиционной разбивке. Он просто предполагает, что текст, позиционно соседствующий в документе, также семантически связан. Однако во многих случаях это предположение не выполняется.
Подумайте: почему чанкинг на основе местоположения приводит к низкой производительности RAG? Как реализовать семантическую разбивку и получить лучшие результаты?
Например, в одной и той же главе автор может сначала обсудить несколько разных концепций, а затем связать их между собой. Если используется только рекурсивная сегментация символов, содержимое, которое должно относиться к одной семантической единице, может быть разделено, или семантически несвязанное содержимое может быть объединено, что повлияет на поиск.
Несмотря на свои недостатки, рекурсивная сегментация символов идеально подходит для начала работы с RAG. Она часто дает удовлетворительные результаты на этапе создания прототипа или для просто структурированных документов. Рекурсивная сегментация символов также является достойным вариантом, если ваш проект имеет высокие требования к стоимости и скорости.
Семантический чанкинг: подход к пониманию смысла текста с помощью чанкинга
Семантический кусок - это более продвинутая стратегия куска, котораяВместо того чтобы полагаться исключительно на позиционную информацию текста, достигается более глубокое понимание его семантического смысла. Основная идея заключается в сегментировании документов при значительном изменении их семантики, при этом каждый фрагмент должен быть максимально сосредоточен вокруг одной темы.
На рисунке ниже показано, как работает семантический кусок:
 Семантический чанкинг работает - рисунок Туваракеша
Семантический чанкинг работает - рисунок ТуваракешаВ отличие от рекурсивной сегментации символов, при семантическом расщеплении создаются блоки, как правило, переменной длины. Он определяет границы блока на основе семантической целостности, а не задает фиксированное количество символов или лексем.
Основные шаги на пути к семантическому расчленению
Трудность семантического расчленения заключается в том, какПрограммируется для понимания семантики предложений**. Обычно это делается с помощьюМодели встраиваниядля реализации. Внедрение таких моделей, как модель OpenAI text-embedding-3-largeПредложения можно преобразовать в векторные представления, а векторы способны передать семантическую информацию предложения. Семантически близкие предложения имеют векторы, которые также близки в пространстве. **
Типичный процесс семантического расчленения состоит из следующих пяти этапов:
- Создание начального блока: Первоначально разбивает документ на предложения или абзацы и объединяет соседние предложения или абзацы в начальный блок.
- Генерирование блочной эмбеддинг: Используйте модель встраивания для генерации векторных вложений для каждого начального блока.
- Рассчитайте расстояние между блоками: Вычислите семантическое расстояние между соседними блоками. Обычно используются такие метрики расстояния, как косинусоидальное расстояние и т. д. Чем больше расстояние, тем больше семантическое различие.
- Определите точку разделения: Установите пороговое значение расстояния. Если расстояние между соседними блоками превышает порог, разбейте их, чтобы сформировать новые семантические блоки. Выбор порога необходимо корректировать в зависимости от конкретного документа и экспериментального эффекта.
- Визуализация (по желанию): Визуализация расстояния между блоками помогает более интуитивно понять эффект разбиения и настроить пороговые значения.
В следующем коде показано, как реализовать семантическое расщепление:
# Step 1 : Create initial chunks by combining concecutive sentences.
# ------------------------------------------------------------------
#Split the text into individual sentences.
sentences = re.split(r"(?<=[.?!])\s+", text)
initial_chunks = [
{"chunk": str(sentence), "index": i} for i, sentence in enumerate(sentences)
]
# Function to combine chunks with overlapping sentences
def combine_chunks(chunks):
for i in range(len(chunks)):
combined_chunk = ""
if i > 0:
combined_chunk += chunks[i - 1]["chunk"]
combined_chunk += chunks[i]["chunk"]
if i < len(chunks) - 1:
combined_chunk += chunks[i + 1]["chunk"]
chunks[i]["combined_chunk"] = combined_chunk
return chunks
# Combine chunks
combined_chunks = combine_chunks(initial_chunks)
# Step 2 : Create embeddings for the initial chunks.
# ------------------------------------------------------------------
# Embed the combined chunks
chunk_embeddings = embeddings.embed_documents(
[chunk["combined_chunk"] for chunk in combined_chunks]
# If you haven't created combined_chunk, use the following.
# [chunk["chunk"] for chunk in combined_chunks]
)
# Add embeddings to chunks
for i, chunk in enumerate(combined_chunks):
chunk["embedding"] = chunk_embeddings[i]
# Step 3 : Calculate distance between the chunks
# ------------------------------------------------------------------
def calculate_cosine_distances(chunks):
distances = []
for i in range(len(chunks) - 1):
current_embedding = chunks[i]["embedding"]
next_embedding = chunks[i + 1]["embedding"]
similarity = cosine_similarity([current_embedding], [next_embedding])[0][0]
distance = 1 - similarity
distances.append(distance)
chunks[i]["distance_to_next"] = distance
return distances
# Calculate cosine distances
distances = calculate_cosine_distances(combined_chunks)
# Step 4 : Find chunks with significant different to it's previous ones.
# ----------------------------------------------------------------------
import numpy as np
threshold_percentile = 90
threshold_value = np.percentile(cosine_distances, threshold_percentile)
crossing_points = [
i for i, distance in enumerate(distances) if distance > threshold_value
]
len(crossing_points)
# Step 5 (Optional) : Create a plot of chunk distances to get a better view
# -------------------------------------------------------------------------
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
def visualize_cosine_distances_with_thresholds_multicolored(
cosine_distances, threshold_percentile=90
):
# Calculate the threshold value based on the percentile
threshold_value = np.percentile(cosine_distances, threshold_percentile)
# Identify the points where the cosine distance crosses the threshold
crossing_points = [0] # Start with the first segment beginning at index 0
crossing_points += [
i
for i, distance in enumerate(cosine_distances)
if distance > threshold_value
]
crossing_points.append(
len(cosine_distances)
) # Ensure the last segment goes to the end
# Set up the plot
plt.figure(figsize=(14, 6))
sns.set(style="white") # Change to white to turn off gridlines
# Plot the cosine distances
sns.lineplot(
x=range(len(cosine_distances)),
y=cosine_distances,
color="blue",
label="Cosine Distance",
)
# Plot the threshold line
plt.axhline(
y=threshold_value,
color="red",
linestyle="--",
label=f"{threshold_percentile}th Percentile Threshold",
)
# Highlight segments between threshold crossings with different colors
colors = sns.color_palette(
"hsv", len(crossing_points) - 1
) # Use a color palette for segments
for i in range(len(crossing_points) - 1):
plt.axvspan(
crossing_points[i], crossing_points[i + 1], color=colors[i], alpha=0.3
)
# Add labels and title
plt.title(
"Cosine Distances Between Segments with Multicolored Threshold Highlighting"
)
plt.xlabel("Segment Index")
plt.ylabel("Cosine Distance")
plt.legend()
# Adjust the x-axis limits to remove extra space
plt.xlim(0, len(cosine_distances) - 1)
# Display the plot
plt.show()
return crossing_points
# Example usage with cosine_distances and threshold_percentile
crossing_poings = visualize_cosine_distances_with_thresholds_multicolored(
distances, threshold_percentile=bp_threashold
)
Диаграмма Себорна для визуализации расстояний:
 Используется для иллюстрации семантического расщепления Диаграмма Сиборна - нарисована Туваракешем
Используется для иллюстрации семантического расщепления Диаграмма Сиборна - нарисована ТуваракешемПреимущества семантического чанкинга и применимые сценарии
Преимущество семантического расчленения заключается в возможностиЛучше улавливает семантическую структуру документов и объединяет семантически связанные фрагменты текста, повышая тем самым качество поиска в системе RAG. Он лучше подходит для обработки следующих типов документов:
- Документы со сложной структурой и разнообразными темамиНапример, объемные отчеты, технические документы, книги и т.д., содержащие множество подтем.
- Документы с высокими семантическими переходамиАвторы могут скакать в своих мыслях во время написания текста, и семантическая разбивка на части позволяет лучше приспособиться к такому стилю письма.
По сравнению с рекурсивной сегментацией символов, семантическое расщеплениеВычисления более дорогостоящие** и более медленные. В основном это связано с необходимостью вычисления вектора встраивания и метрики расстояния. Поэтому в сценариях с ограниченными ресурсами необходимо учитывать компромиссы.
Агенциальный чанкинг: стратегии чанкинга, имитирующие человеческое понимание
Агентская разбивка - это еще один шаг на пути к интеллектуальной разбивке. ОнОпираясь на то, как люди читают и понимают документы, LLM используется в качестве "интеллектуального агента" для помощи в разбивке на куски.
Читательские привычки человека не совсем линейныАгентный кусок пытается имитировать этот процесс человеческого понимания. Когда мы читаем, мы перескакиваем с темы на тему или с понятия на понятие и выстраиваем логическую структуру документа в своем сознании. агентивный кусок пытается имитировать этот процесс человеческого понимания.
В отличие от двух предыдущих методов, агентурное расщеплениене предполагает, что семантически схожее содержимое встречается в документе последовательно**. Он может объединять разрозненные, но семантически связанные фрагменты документа, формируя семантические куски, которые более совместимы с человеческим восприятием.
Рабочий процесс агентирования
Основная идея агентурного расчленения заключается в следующемПусть LLM "читает" документ как человек, определяя основные понятия и темы в документе и разбивая его на части на основе этих понятий и тем. Типичный процесс агентурного разбиения включает в себя:
- Предложение: Преобразуйте каждое предложение в документе в более независимое Предложение. Например, замена неизвестных местоимений на объекты для придания каждому предложению более полного смыслового значения.
- Строительные блоки-контейнеры: Создайте один или несколько контейнеров Chunk для семантически связанных предложений. Каждый контейнер Chunk может иметь заголовок и резюме, описывающее тему этого контейнера.
- Управляемые агентами пропозициональные задания: Используя LLM в качестве агента, "читайте" предложения одно за другим и определяйте, к какому блочному контейнеру должно относиться предложение.
- Если агент считает, что предложение относится к теме одного из существующих контейнеров блоков, оно добавляется в этот контейнер.
- Если агент считает, что предложение предлагает новую тему, он создает новый блок-контейнер для размещения предложения.
- Переработка блок-контейнеров: Постобработка контейнеров блоков, например, создание более точных резюме и заголовков блоков на основе предложений, содержащихся в контейнере.
Следующий код показывает реализацию Agentic chunking:
from langchain import hub
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Step 1: Convert paragraphs to propositions.
# --------------------------------------------
# Load the propositioning prompt from langchain hub
obj = hub.pull("wfh/proposal-indexing")
# Pick the LLM
llm = ChatOpenAI(model="gpt-4o")
# A Pydantic model to extract sentences from the passage
class Sentences(BaseModel):
sentences: List[str]
extraction_llm = llm.with_structured_output(Sentences)
# Create the sentence extraction chain
extraction_chain = obj | extraction_llm
# NOTE: text is your actual document
paragraphs = text.split("\n\n")
propositions = []
for i, p in enumerate(paragraphs):
propositions = extraction_chain.invoke(p
propositions.extend(propositions)
# Step 2: Create a placeholder to store chunks
chunks = {}
# Step 3: Deine helper classes and functions for agentic chunking.
class ChunkMeta(BaseModel):
title: str = Field(description="The title of the chunk.")
summary: str = Field(description="The summary of the chunk.")
def create_new_chunk(chunk_id, proposition):
summary_llm = llm.with_structured_output(ChunkMeta)
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"Generate a new summary and a title based on the propositions.",
),
(
"user",
"propositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk_meta = summary_chain.invoke(
{
"propositions": [proposition],
}
)
chunks[chunk_id] = {
"summary": chunk_meta.summary,
"title": chunk_meta.title,
"propositions": [proposition],
}
def add_proposition(chunk_id, proposition):
summary_llm = llm.with_structured_output(ChunkMeta)
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"If the current_summary and title is still valid for the propositions return them."
"If not generate a new summary and a title based on the propositions.",
),
(
"user",
"current_summary:{current_summary}\n\ncurrent_title:{current_title}\n\npropositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk = chunks[chunk_id]
current_summary = chunk["summary"]
current_title = chunk["title"]
current_propositions = chunk["propositions"]
all_propositions = current_propositions + [proposition]
chunk_meta = summary_chain.invoke(
{
"current_summary": current_summary,
"current_title": current_title,
"propositions": all_propositions,
}
)
chunk["summary"] = chunk_meta.summary
chunk["title"] = chunk_meta.title
chunk["propositions"] = all_propositions
# Step 5: The main functino that creates chunks from propositions.
def find_chunk_and_push_proposition(proposition):
class ChunkID(BaseModel):
chunk_id: int = Field(description="The chunk id.")
allocation_llm = llm.with_structured_output(ChunkID)
allocation_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You have the chunk ids and the summaries"
"Find the chunk that best matches the proposition."
"If no chunk matches, return a new chunk id."
"Return only the chunk id.",
),
(
"user",
"proposition:{proposition}" "chunks_summaries:{chunks_summaries}",
),
]
)
allocation_chain = allocation_prompt | allocation_llm
chunks_summaries = {
chunk_id: chunk["summary"] for chunk_id, chunk in chunks.items()
}
best_chunk_id = allocation_chain.invoke(
{"proposition": proposition, "chunks_summaries": chunks_summaries}
).chunk_id
if best_chunk_id not in chunks:
best_chunk_id = create_new_chunk(best_chunk_id, proposition)
return
add_proposition(best_chunk_id, proposition)
Примеры пропозиционализации
原始文本
===================
A crow sits near the pond. It's a white one.
命题化文本
==================
A crow sits near the pond. This crow is a white one.
Преимущества и проблемы агентурного расчленения
Агенты, разбитые на частиГлавное преимущество - гибкость и интеллектуальность**. Он может лучше понимать глубокую семантическую структуру документов и генерировать семантические фрагменты, которые в большей степени соответствуют человеческому восприятию, и особенно хорошо справляется со следующими типами документов:**.
- Документирование нелинейных структур: Например, документы, в которых мысли скачут и содержится много фоновых знаний или подразумеваемой информации.
- Документы, в которых необходимо объединить информацию по параграфам и разделам: Агентурный чанкинг позволяет объединять семантически связанные фрагменты, которые разбросаны в разных местах документа.
Однако агентурное разделение также сталкивается с некоторыми проблемами:
- высокая стоимостьАгентное разбиение требует частых обращений к LLM, что требует больших затрат времени и вычислений.
- Подсказка Зависимости проекта: Эффективность агентурного разбиения в значительной степени зависит от дизайна подсказки. Подсказки должны быть тщательно разработаны, чтобы эффективно направлять LLM на разбивку.
- Неопределенность результата: На выходе LLM может быть некоторая неопределенность, что приводит к нестабильным результатам разбиения на части.
Сценарии применения агентского чанкинга
Хотя агентурное распределение, хотя и более дорогостоящее, все же является вариантом, который стоит рассмотреть в некоторых сценариях, где эффективность RAG имеет решающее значение. Пример:
- База знаний в специализированных областяхНапример, базы знаний в области юриспруденции, медицины, финансов и т. д. требуют чрезвычайно высокой точности поиска и запоминания.
- сложная система вопросов и ответов: Система вопросов и ответов, которая должна решать сложные вопросы, требующие осмысления и интеграции информации.
Углубленное чтение:Агентный чанкинг: управляемый агентами ИИ семантический чанкинг текста
Стратегии разбивки на части для различных форматов документов
Предыдущее обсуждение было посвящено в основном разбивке обычного текста. Однако в практических приложениях мы часто сталкиваемся с различными форматами документов, такими как Markdown, HTML, PDF, код и так далее. Для разных форматов необходима более тонкая стратегия разбиения на куски, чтобы в полной мере использовать структурную информацию документа.
Разбивка на части документов Markdown и HTML
Документы Markdown и HTML содержат структурированные теги, такие как заголовки, абзацы, списки, блоки кода и так далее. Мы можемИспользуйте эти метки в качестве основы для разбивки** для более точной разбивки. **
- Блок по названию: Рассматривайте каждый заголовок и содержимое под ним как отдельный блок. Это подходит для четко структурированных документов с отдельными разделами.
- кусок: Рассматривайте каждый абзац как кусок. Абзацы обычно являются семантически полными единицами и подходят в качестве основных единиц разбиения.
- измельчение: Объедините заголовки и абзацы для разбивки на части. Например, сначала разделите документ по заголовкам первого уровня, затем по содержимому под каждым заголовком первого уровня, затем разделите по абзацам.
Пример: разбивка на части на основе HTML-тегов (Python)
from bs4 import BeautifulSoup
html_text = """
<h1>Section 1</h1>
<p>This is the first paragraph of section 1.</p>
<p>This is the second paragraph of section 1.</p>
<h2>Subsection 1.1</h2>
<ul>
<li>List item 1</li>
<li>List item 2</li>
</ul>
"""
soup = BeautifulSoup(html_text, 'html.parser')
chunks = []
# 按 h1 标题分块
for h1_tag in soup.find_all('h1'):
chunk_text = h1_tag.text + "\n"
next_sibling = h1_tag.find_next_sibling()
while next_sibling and next_sibling.name not in ['h1', 'h2']: # 假设按 h1 和 h2 分级
chunk_text += str(next_sibling) + "\n" # 保留 HTML 标签,或 next_sibling.text 只保留文本
next_sibling = next_sibling.find_next_sibling()
chunks.append(chunk_text)
# 可以类似地处理 h2, p, ul, ol 等标签
print(chunks)
Разбивка документов PDF
Разбивка PDF-документов является относительно сложной задачей, поскольку PDF - это, по сути, формат набора текста, в котором смешаны текстовое содержимое и типографская информация. Разбивка PDF-документов непосредственно по символам или строкам может нарушить семантическую целостность.
Основные этапы разбивки PDF-файлов обычно включают в себя:
- Извлечение текста из PDF: Использование библиотек для разбора PDF (например, PyPDF2, pdfminer или более профессиональных). неструктурированный.io) для извлечения текстового содержимого из файлов PDF.
- Очистка и предварительная обработка текста: Удаление зашумленных символов, обработка переносов строк, исправление ошибок OCR и многое другое.
- Извлечение структурированной информации: Попробуйте извлечь из PDF-файлов структурированную информацию, например заголовки, верхние и нижние колонтитулы, таблицы, списки и так далее. Некоторые продвинутые библиотеки для разбора PDF (например, unstructured.io) могут помочь в извлечении структурированной информации.
- Варианты стратегий объединенияВыбор подходящих стратегий разбиения на части (например, семантическое разбиение, рекурсивная сегментация символов и т. д.) на основе извлеченного содержимого текста и структурной информации.
привлекать внимание к чему-л.: unstructured.io это мощный инструмент, который может работать с широким спектром форматов документов (включая PDF) и пытается извлечь структурированную информацию из документов, упрощая процесс разбивки PDF на части.
Разбивка кодовой документации
Разбивка кодовых документов (например, файлов кода Python, Java, C++) требует учета синтаксической структуры и логических единиц кода. Простое разбиение кода на строки или символы, скорее всего, нарушит целостность и исполняемость кода.
К распространенным стратегиям разбивки документации по коду относятся:
- Разбивка по функциям/классам: Рассматривайте каждую функцию или класс как отдельный блок. Функции и классы обычно являются логическими единицами кода.
- Разбивка на блоки по коду: Определяет логические блоки в коде (например, циклы, условные операторы, блоки try-except и т. д.), рассматривая каждый блок как фрагмент.
- В сочетании с разбивкой комментариев кода: Комментарии к коду - это, как правило, пояснения к функциональности и логике кода. Комментарии к коду и связанные с ними блоки кода могут быть разбиты на части как единое целое.
артефакт: Структурированный анализ и разбивка кода на части могут быть облегчены использованием инструментов синтаксического разбора, таких как tree-sitter, который разбирает код на различных языках программирования и генерирует абстрактное дерево синтаксиса (AST), что позволяет легко разбивать код на части в соответствии с его синтаксической структурой.
Выбор правильного размера куска и перекрытия
Размер чанка и перекрытие чанков - два важных параметра в политике чанкинга, которые напрямую влияют на производительность системы RAG.
- Размер куска: Объем текста, содержащегося в каждом фрагменте. Слишком маленький размер фрагмента может привести к неполной семантической информации; слишком большой размер фрагмента может внести шум и снизить точность поиска.
- Размер перекрытия: Количество текста, перекрывающего соседние блоки. Цель перекрытия - обеспечить контекстную непрерывность и избежать потери информации на границах блоков.
Как выбрать правильный размер кусков и их перекрытие?
Не существует абсолютно оптимального ответа на вопрос о выборе правильного размера кусков и их перекрытия, и обычно он должен определятьсяОсобенности документаответить пениемэкспериментальный эффектопределить. Вот некоторые правила и рекомендации:
- эвристический метод::
- На основе длины предложения/параграфа: Средняя длина предложения или абзаца в документе может быть использована в качестве ориентира для размера чанка. Например, если средняя длина абзаца составляет 150 Token, вы можете попробовать установить размер куска в 150-200 Token.
- Рассмотрим контекстное окно LLM: Размер блока не должен быть слишком большим, чтобы не превысить ограничения контекстного окна LLM. В то же время он не должен быть слишком маленьким, чтобы блок содержал достаточно семантической информации.
- Экспериментирование и оценка:
- Итеративная настройка: Установите начальный набор параметров размера куска и перекрытия (например, 500 Token для размера куска и 50 Token для перекрытия), постройте систему RAG и оцените ее. Затем постепенно изменяйте параметры, наблюдайте за изменениями в результатах поиска и вопросах и ответах и выбирайте оптимальную комбинацию параметров.
- Оценка показателей: Оцените эффективность системы RAG, используя подходящие метрики оценки, такие как Recall@k, Precision@k, NDCG (Normalised Discounted Cumulative Gain) и т. д. для поиска. Эти метрики помогут вам объективно оценить эффективность различных стратегий разбиения на части.
Инструменты оценки в Langchain
Langchain предоставляет ряд инструментов оценки, которые могут помочь в оценке и настройке параметров систем RAG. Например, такие инструменты, как DatasetEvaluator и RetrievalQAChain, помогут вам автоматизировать оценку влияния комбинаций различных стратегий чанкинга, моделей поиска и моделей LLM.
Оценка эффективности стратегии разбивки на части
Выбрав правильную стратегию объединения, как оценить ее эффективность? "Лучшее разбиение на части означает лучшее извлечение", но как количественно определить это "лучшее"? Нам нужны метрики, чтобы оценить достоинства стратегий кускования.
Ниже приведены некоторые общие показатели оценки, которые помогут вам оценить влияние стратегии разбиения на части на производительность системы RAG:
- Извлечение индикаторов:
- Вспомнить (Вспомнить@k): означает долю релевантных документов (или фрагментов) среди результатов поиска Top-k. Чем выше показатель recall, тем больше релевантной информации извлекается с помощью стратегии объединения фрагментов.
- Точность (Precision@k): означает долю действительно релевантных документов (или фрагментов) среди результатов поиска Top-k. Чем выше точность, тем выше качество результатов поиска.
- НДКГ (нормализованная дисконтированная кумулятивная прибыль): является более тонкой метрикой оценки качества ранжирования, которая учитывает уровень релевантности и позицию найденных результатов. Более высокий NDCG указывает на лучшее качество ранжирования поиска.
- Индикаторы в вопросах и ответах:
- Актуальность ответа: Оцените, насколько ответы, сгенерированные LLM, соответствуют вопросу. Чем выше релевантность ответов, тем лучше система RAG генерирует содержательные ответы на основе полученной информации.
- Точность/верность ответа: Оценить, насколько ответы, генерируемые LLM, соответствуют полученной контекстуальной информации, избегая "иллюзий" и неточной информации. Более высокая точность ответов указывает на то, что стратегия фрагментации способна обеспечить надежный контекст и направить LLM на создание более достоверных ответов.
- Беглость и согласованность ответов: Несмотря на то, что в основном это зависит от способностей самого LLM, хорошая стратегия разбивки на части может также косвенно улучшить беглость и связность ответов. Например, семантическая разбивка обеспечивает более связный контекст и помогает LLM создавать более естественный язык.
- Актуальность ответа: Оцените, насколько ответы, сгенерированные LLM, соответствуют вопросу. Чем выше релевантность ответов, тем лучше система RAG генерирует содержательные ответы на основе полученной информации.
Инструменты и методологии оценки
- ручная оценка:: Самый прямой и надежный метод. Человеку предлагается оценить результаты поиска и ответы на вопросы и ответы системы RAG на основе заранее определенных критериев оценки. Недостатки ручной оценки заключаются в том, что она является дорогостоящей, требует много времени и крайне субъективна.
- Автоматизированная оценка:: Использование автоматизированных показателей и инструментов оценки, например:
- Извлечение индикаторовНапример, запоминание, точность, NDCG и т.д. могут быть измерены с помощью стандартных инструментов оценки информационного поиска (например.
rank_bm25,sentence-transformersи т.д.) для автоматизированных расчетов. - Индикаторы в вопросах и ответах: Некоторые метрики оценки NLP (например, BLEU, ROUGE, METEOR, BERTScore и т. д.) могут быть использованы для помощи в оценке качества ответов. Однако следует отметить, что автоматизированные метрики оценки вопросов и ответов все еще имеют ограничения и не могут полностью заменить ручную оценку.
- Инструмент оценки Langchain: Langchain предлагает ряд интегрированных инструментов оценки, таких как
DatasetEvaluatorответить пениемRetrievalQAChainЭто упрощает процесс автоматизированной оценки системы RAG.
- Извлечение индикаторовНапример, запоминание, точность, NDCG и т.д. могут быть измерены с помощью стандартных инструментов оценки информационного поиска (например.
Рекомендации по процессу оценки
- Создание набора данных для оценки:: Подготовьте набор данных для оценки, содержащий вопросы и соответствующие стандартные ответы. Набор данных должен, насколько это возможно, охватывать типичные сценарии применения и типы вопросов для систем RAG.
- Выбор показателей оценки:: Выбор соответствующих показателей поиска и вопросов-ответов в зависимости от цели оценки. Возможно одновременное использование комбинации ручной и автоматизированной оценки.
- Запуск системы RAG: Запустите систему RAG на наборе оценочных данных, используя различные комбинации стратегий разбиения на части, моделей поиска и моделей LLM, чтобы зафиксировать результаты оценки.
- Анализ и сравнение: Сравните показатели оценки различных стратегий, проанализируйте их сильные и слабые стороны и выберите оптимальную комбинацию стратегий.
- Итеративная оптимизация: На основе результатов оценки параметры стратегии объединения, модели поиска и модели LLM постоянно корректируются для итеративной оптимизации с целью повышения производительности системы RAG.
Подводя итог: выберите ту стратегию разбивки на части, которая лучше всего вам подходит
В данной статье подробно рассматриваются методы разбиения документов на куски, имеющие решающее значение для приложений RAG, начиная с базовой рекурсивной сегментации символов, более интеллектуального семантического разбиения и агентного разбиения, и заканчивая уточненными стратегиями разбиения для различных форматов документов, а также методами выбора и оценки размеров кусков и параметров перекрытия.
Обзор основных положений
- Масса куска определяет массу RAG: Хорошая стратегия разбивки на части - краеугольный камень построения высокопроизводительной системы RAG.
- Не существует универсальной стратегии разбивки на части: Различные стратегии разбиения документов на части имеют свои преимущества и недостатки и подходят для разных сценариев. Вы должны выбрать наиболее подходящую стратегию, исходя из конкретных требований вашего проекта, характеристик документа и ограничений по ресурсам.
- Рекурсивная сегментация символов: Простой, быстрый и экономичный для создания прототипов и проектов, требующих минимальных затрат.
- семантическое измельчение: Понимание семантики текста и создание семантически связных фрагментов улучшает качество поиска, но требует больших вычислительных затрат.
- Агентурное расщепление: Имитирует человеческое понимание, является более интеллектуальным, гибким и может работать со сложными документами, но является дорогостоящим и Prompt engineering сложным.
- Разбивка на части для различных форматов: Для различных форматов, таких как Markdown, HTML, PDF, код и т. д., требуется стратегия тонкой разбивки на части, чтобы использовать структурную информацию документа.
- Размер кусков и их перекрытие: Необходимо настраивать в соответствии с характеристиками документа и результатами экспериментов, абсолютного оптимального значения не существует.
- Оценка - ключевой момент:: Количественная оценка эффективности стратегии разбиения на части с помощью метрик оценки и ручной оценки, а также итеративная оптимизация.
Как выбрать? Мой совет.
- Быстрое прототипирование:: Приоритетные попыткиРекурсивная сегментация символовRAG - это быстрый способ создать прототип RAG и проверить осуществимость системы.
- Стремление к высокому качеству: Если качество RAG очень востребовано и вычислительные ресурсы позволяют, можно попробоватьсемантическое измельчение.
- Работа со сложными документами:: Для документов со сложной структурой и семантическими переходами.Агентурное расщеплениеЭто может быть предпочтительным вариантом, но необходимо тщательно взвесить стоимость и эффективность.
- Специфический формат: Если вы работаете с документами в определенном формате, таком как Markdown, HTML, PDF, код и т. д., обязательно используйтеСтратегия целенаправленного расчлененияСтруктурная информация документа используется полностью.
- Непрерывная итеративная оптимизация:: Выбор стратегии чанкинга - это не одномоментный процесс. В реальных проектах необходимо постоянноЭкспериментирование, оценка и итеративная оптимизацияЧтобы найти оптимальное решение для чанкинга.
Надеюсь, эта статья поможет вам глубже понять технологию чанкинга RAG, а также выбрать и применить соответствующие стратегии чанкинга в реальных проектах для создания более мощных приложений RAG!
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...