QwenLong-L1.5 - модель вывода длинных текстов с открытым исходным кодом лаборатории Али Тонги

Что такое QwenLong-L1.5?
QwenLong-L1.5 - это модель вывода длинных текстов с открытым исходным кодом от Alibaba Tongyi Labs, ориентированная на решение сложных задач вывода со сверхдлинными контекстами (например, 1M-4M лексем). Основной прорыв заключается в трех главных инновациях на этапе посттренинга: генерация высококачественных многоходовых данных для вывода с помощью графа знаний, синтаксического анализа SQL и мультиинтеллектуальной структуры; предложение стратегии адаптивного управления энтропией AEPo для динамического баланса стабильности обучения; разработка архитектуры агента памяти для обработки сверхдлинного текста в кусках и обновления сводки памяти в реальном времени. Модель превосходит GPT-5 и Gemini-2.5-Pro в LongBench-V2 и других списках, особенно в задаче со сверхдлинным текстом, а также улучшает возможности общего назначения, такие как математические рассуждения.
Особенности QwenLong-L1.5
- Значительное улучшение в рассуждениях в длинном контексте: Благодаря систематическому посттренинговому обучению QwenLong-L1.5 превосходит все остальные программы в области длинных контекстных выводов, справляясь с задачами, выходящими за пределы физического контекстного окна (256 Кбайт).
- Инновационные стратегии синтеза данных и обучения с подкреплением: Разработан новый процесс синтеза данных, ориентированный на создание сложных задач, требующих многоходовой трассировки и глобально распределенных доказательных рассуждений, с применением стратегий обучения с подкреплением, таких как сбалансированная по задачам выборка и оптимизация политики адаптивного управления энтропией для стабилизации длительного контекстного обучения.
- Мощная система управления памятью: Использование многоступенчатого обучения с подкреплением в сочетании с механизмом обновления памяти позволяет модели обрабатывать более длинные задачи за пределами контекстного окна в 256 Кбайт для одного вывода.
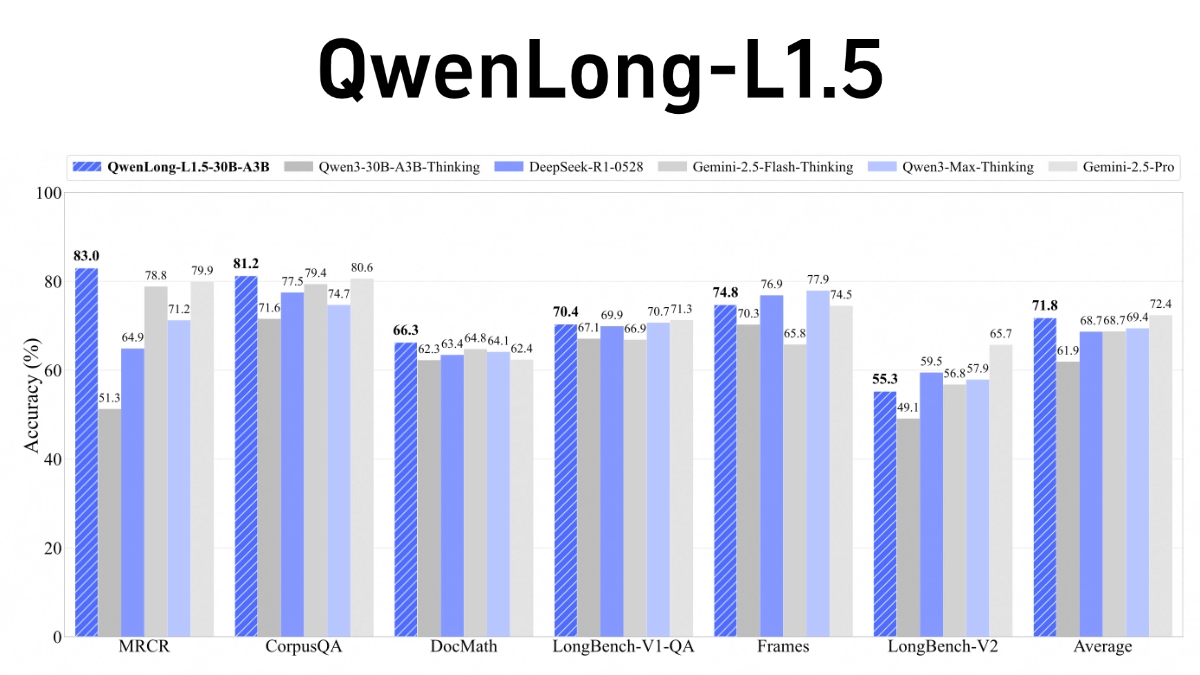
- отличная производительность: В бенчмарках с длинным контекстом QwenLong-L1.5 превосходит свою базовую модель Qwen3-30B-A3B-Thinking в среднем на 9,9 балла, а по производительности сравнима с такими топовыми моделями, как GPT-5 и Gemini-2.5-Pro. На сверхдлинных задачах (от 1 до 4 миллионов токенов) фреймворк memory-smartbody достигает прироста производительности в 9,48 балла по сравнению с базовой моделью smartbody.
- расширить свои финансовые возможности: Модель имеет открытый исходный код для удобства использования исследователями и разработчиками.
Основные преимущества QwenLong-L1.5
- Возможность обработки сверхдлинных текстов: Может решать задачи, превышающие его физическое контекстное окно (256 Кбайт), и подходит для обработки сверхдлинных текстовых рассуждений и анализа, таких как длинные документы, сложные наборы данных и т.д.
- Инновационные стратегии обучения: Сочетание методов обучения с подкреплением, таких как сбалансированная по задачам выборка и адаптивная оптимизация политики с контролем энтропии (AEPO), позволяет эффективно повысить стабильность и производительность модели в задачах с длительным контекстом.
- Эффективное управление памятью: Благодаря механизму обновления памяти и многоступенчатому обучению с подкреплением, модель может эффективно управлять информацией в длинных текстах и достигать эффективной обработки сверхдлинных задач (от 1 до 4 миллионов лексем).
- Превосходная производительность: В бенчмарках с длинным контекстом QwenLong-L1.5 значительно превосходит свою базовую модель и даже конкурирует с такими топовыми моделями, как GPT-5 и Gemini-2.5-Pro.
Каков официальный сайт QwenLong-L1.5?
- Репозиторий GitHub:: https://github.com/Tongyi-Zhiwen/Qwen-Doc
- Библиотека моделей HuggingFace:: https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
- Технический документ arXiv:: https://arxiv.org/pdf/2512.12967
Применимые люди QwenLong-L1.5
- исследователь в области обработки естественного языка (NLP)Возможности QwenLong-L1.5 по обработке длинных контекстов и инновационные стратегии обучения предоставляют исследователям новые инструменты для изучения таких передовых проблем, как осмысление длинных текстов и управление памятью, способствуя прогрессу исследований в области обработки естественного языка.
- Разработчики искусственного интеллекта: Благодаря открытому исходному коду он идеально подходит для создания приложений для обработки длинных текстов, таких как интеллектуальное обслуживание клиентов, анализ документов, создание контента и т. д., что может помочь разработчикам быстро создать высокопроизводительные функции обработки длинных текстов.
- специалист по анализу данных: При работе с крупными текстовыми массивами данных QwenLong-L1.5 может эффективно выполнять анализ и вывод длинных текстов, предоставляя ученым мощную поддержку для анализа данных и задач машинного обучения.
- Корпоративная техническая команда: Для предприятий, которым приходится иметь дело с длинными текстами, таких как финансовая, юридическая, медицинская и другие отрасли, QwenLong-L1.5 может помочь команде более эффективно работать с длинными текстовыми данными, такими как контракты, отчеты, медицинские карты и другие длинные текстовые данные, и повысить эффективность бизнеса.
- Академические исследователи: В академических исследованиях, особенно в областях, связанных с анализом длинных текстов, таких как литературные исследования, анализ исторических документов и т.д., QwenLong-L1.5 может быть использован в качестве инструмента, помогающего исследователям выудить глубокую информацию из текста.
- педагогВ сфере образования QwenLong-L1.5 может использоваться для помощи в преподавании, например, для автоматического исправления длинных эссе и анализа научных работ, предоставляя преподавателям более эффективные инструменты поддержки обучения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...