
Qwen3.5-Omni - 阿里通义推出的新一代全模态大模型

Qwen3.5-Omni是什么
Qwen3.5-Omni是阿里通义推出的新一代全模态大模型,支持文本、图片、音频、音视频的原生理解与生成。采用Hybrid-Attention MoE架构,支持256K超长上下文,可处理10小时音频或400秒720P视频,具备113种语言识别和36种语言语音合成能力。核心突破包括自然涌现的音视频指令编码能力,能直接将音视频内容转化为可执行代码,新增了语义打断、音色克隆等实时交互功能。相比上一代,在215项国际基准测试中达到最先进水平,尤其在音频理解能力上超越了Gemini-3.1 Pro。
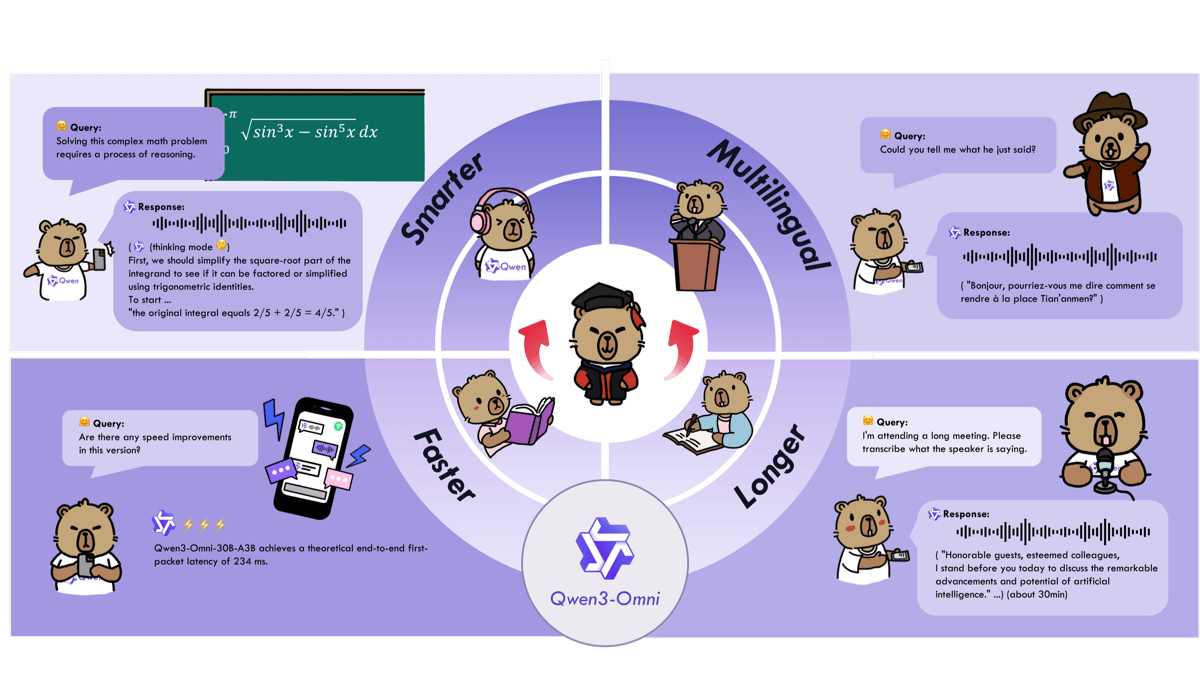
Qwen3.5-Omni的功能特色
- 全模态原生理解:统一架构原生支持文本、图像、音频、视频四种模态输入,无需分阶段处理,实现真正的端到端多模态理解。
- Аудио- и видеовзаимодействие в режиме реального времени:支持低延迟的实时音视频对话,能够同时接收音频和视频流输入,并即时输出文本和自然语音响应。
- 流式语音合成:采用多码本语音编码器,支持实时流式语音输出,延迟降至最低,语音自然度和表现力接近人类水平。
- 双版本架构设计:提供 Instruct 版(Thinker+Talker双组件,支持语音输出)和 Thinking 版(仅Thinker组件,适合纯文本推理场景)。
- 多语言语音支持:覆盖119种文本语言、19种语音输入语言和10种语音输出语言,支持跨语言语音合成和零样本语音克隆。
- 语音克隆能力:支持零样本语音生成,可根据参考音频克隆说话人音色,实现个性化语音输出。
- 视觉-音频联合理解:能同时处理视频画面和音频内容,进行跨模态关联分析,如视频内容描述、音画同步理解等。
- Комплексная обработка звука:原生支持语音输入的自动语音识别(ASR)、语音情感识别、语音内容理解,无需外部ASR模块。
- 灵活行为控制:通过系统提示词(System Prompt)自定义模型行为,可调整说话风格、响应长度、情感表达等。
- 工具调用与推理:支持函数调用、代码生成、复杂推理任务,多模态训练不损害文本和图像的单模态性能。
Qwen3.5-Omni的核心优势
- 性能全面领先:在36项音频/视频基准测试中,32项达到开源SOTA,22项刷新全球SOTA,ASR和语音对话性能可比肩 Близнецы 2.5 Pro。
- 文本能力不降级:多模态联合训练不损害单模态性能,文本和图像理解能力保持与 Qwen3 系列同等水平。
- 超低延迟交互:采用 AuT(Audio-Text)预训练策略和流式多码本语音编码器,实现实时音视频对话的最低延迟响应。
- 创新MoE架构:基于混合专家(Mixture-of-Experts)架构的 Thinker-Talker 设计,总参数量30B,激活参数仅3B,高效平衡性能与资源消耗。
- 端到端一体化:原生端到端架构无需外部ASR、TTS模块串联,避免错误累积,提升系统稳定性和响应速度。
- 开源可商用:采用 Apache 2.0 许可证开源,模型权重、训练代码、推理框架全部开放,支持商业用途。
- 多语言覆盖广:支持119种文本语言、19种语音输入语言和10种语音输出语言,全球化适用性强。
- Гибкий подход к развертыванию:支持本地部署(需高端GPU)、云端API调用(DashScope)、Hugging Face在线体验等多种使用方式。
- 零样本语音能力:无需微调即可实现语音克隆和跨语言语音合成,降低个性化语音应用门槛。
- 生态工具完善:提供 Qwen-Audio-Chat、Qwen2.5-Omni-Chat 等配套工具,以及详细的部署文档和示例代码。
Qwen3.5-Omni官网是什么
- Репозиторий Github:: https://github.com/QwenLM/Qwen3-Omni
- Библиотека моделей HuggingFace:https://huggingface.co/collections/Qwen/qwen3-omni
使用Qwen3.5-Omni的操作步骤
- Опыт работы в Интернете:访问 Hugging Face 官方 Demo 页面,直接上传音频/视频文件或开启麦克风进行实时对话,无需本地部署。
- API 调用(推荐)::
- 注册阿里云 DashScope 账号并获取 API Key
- 通过 OpenAI 兼容接口调用,支持文本、音频、视频多模态输入
- 使用流式响应模式获取实时语音和文本输出
- 本地部署环境准备::
- 确保拥有 CUDA 12.1+ 环境
- Установите зависимость:
pip install transformers accelerate flash-attn - 根据视频长度准备充足显存(30秒视频约需88GB,建议使用 FlashAttention 2 优化)
- Скачать модель::
- 从 Hugging Face 或 ModelScope 下载模型权重
- 可选版本:Instruct版(支持语音输出)或 Thinking版(纯文本推理)
- 本地推理代码示例::
- 加载模型和处理器
- 准备多模态输入(文本+音频/视频路径)
- 设置生成参数(temperature、max_new_tokens等)
- 执行推理并获取文本+语音输出
- Развертывание Docker:使用官方提供的 Docker 镜像快速启动服务,适合生产环境部署。
- 自定义语音克隆:提供参考音频文件,通过系统提示词指定音色克隆参数,实现个性化语音输出。
- 多轮对话维护: Использование
apply_chat_template构建对话历史,支持文本、音频、视频混合的多轮交互。
Qwen3.5-Omni的适用人群
- AI应用开发者:需要构建实时语音助手、多模态对话系统、智能客服等应用的开发者,可利用端到端架构快速集成音视频能力。
- создатель контента:视频博主、播客主播、短视频创作者,可使用语音克隆和跨语言合成功能批量生成多语言配音内容。
- Практикующие специалисты в сфере образования:在线教育平台、语言学习App开发者,可借助实时语音交互和多语言能力打造沉浸式学习体验。
- 企业IT团队:需要部署私有化多模态AI服务的中大型企业,可利用开源模型和本地部署方案满足数据安全需求。
- 音视频处理工程师:从事语音识别、视频分析、字幕生成等工作的技术人员,可替代传统ASR+TTS串联方案。
- производитель интеллектуального оборудования:智能音箱、机器人、车载系统等硬件开发者,可集成实时音视频对话能力提升产品交互体验。
Qwen3.5-Omni的常见问题FAQ
Q:本地部署需要什么样的硬件配置?
A:以30B模型为例,处理30秒视频约需88GB显存(BF16精度),60秒视频约需108GB显存。建议使用支持 FlashAttention 2 的高端GPU(如A100/H100)进行部署,或使用量化版本降低显存需求。
Q:Instruct版和Thinking版有什么区别?
A:Instruct版包含 Thinker(思考组件)+ Talker(说话组件),支持语音输出;Thinking版仅包含 Thinker 组件,适合纯文本推理场景,显存需求更低(30秒视频约78GB)。
Q:支持哪些编程语言调用?
A:官方提供 Python SDK,同时兼容 OpenAI API 格式,支持 HTTP 请求调用。也可通过 transformers 库直接加载模型进行本地推理。
Q:是否支持商业用途?
A:是的,模型采用 Apache 2.0 许可证开源,模型权重、代码均可免费用于商业项目。
Q:语音克隆功能如何使用?
A:提供参考音频文件,通过系统提示词指定音色克隆参数,模型支持零样本语音生成,无需针对特定说话人进行微调。
Q:实时对话的延迟是多少?
A:采用 AuT 预训练策略和流式多码本设计,延迟已降至最低水平,具体延迟取决于网络环境和硬件配置,可实现接近实时的语音交互体验。
Q:是否支持中文语音?
A:支持,覆盖119种文本语言、19种语音输入语言和10种语音输出语言,中文语音交互效果优秀。
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...