
Выпущен Qwen2.5-VL: поддержка понимания длинного видео, визуальная локализация, структурированный вывод, возможность тонкой настройки с открытым исходным кодом

1.Представление модели
За пять месяцев, прошедших с момента выхода Qwen2-VL, многие разработчики построили новые модели на основе визуальной языковой модели Qwen2-VL, предоставив команде Qwen ценные отзывы. За это время команда Qwen сосредоточилась на создании более полезных визуальных языковых моделей. Сегодня команда Qwen рада представить новейшего члена семейства Qwen: Qwen2.5-VL.
Основные усовершенствования:
- Понимание вещей визуально: Qwen 2.5-VL умеет не только распознавать обычные объекты, такие как цветы, птицы, рыбы и насекомые, но и анализировать текст, диаграммы, значки, графики и макеты на изображениях.
- Agenticity: Qwen2.5-VL играет роль непосредственно визуального агента, с функциональностью рассуждающего и динамического командного инструмента, который может быть использован на компьютерах и мобильных телефонах.
- Понимание длинных видео и захват событий: Qwen 2.5-VL может понимать видео длительностью более 1 часа, и на этот раз у него появилась новая возможность захвата событий путем точного определения соответствующих видеоклипов.
- Возможность визуальной локализации в различных форматах: Qwen2.5-VL может точно определять местоположение объектов на изображении, генерируя ограничительные рамки или точки, а также обеспечивать стабильный вывод координат и атрибутов в формате JSON.
- Создание структурированного вывода: для отсканированных данных, таких как счета, формы, таблицы и т. д., Qwen 2.5-VL поддерживает структурированный вывод их содержимого, что полезно для использования в финансовой, деловой и других сферах.
Архитектура модели:
- Обучение динамическому разрешению и частоте кадров для понимания видео:
Расширение динамического разрешения на временное измерение за счет использования динамической выборки FPS позволяет модели понимать видео с различной частотой дискретизации. Соответственно, команда Qwen обновила mRoPE, добавив выравнивание по ID и абсолютному времени во временном измерении, что позволило модели узнать временной порядок и скорость, в итоге получив возможность точно определять конкретные моменты.
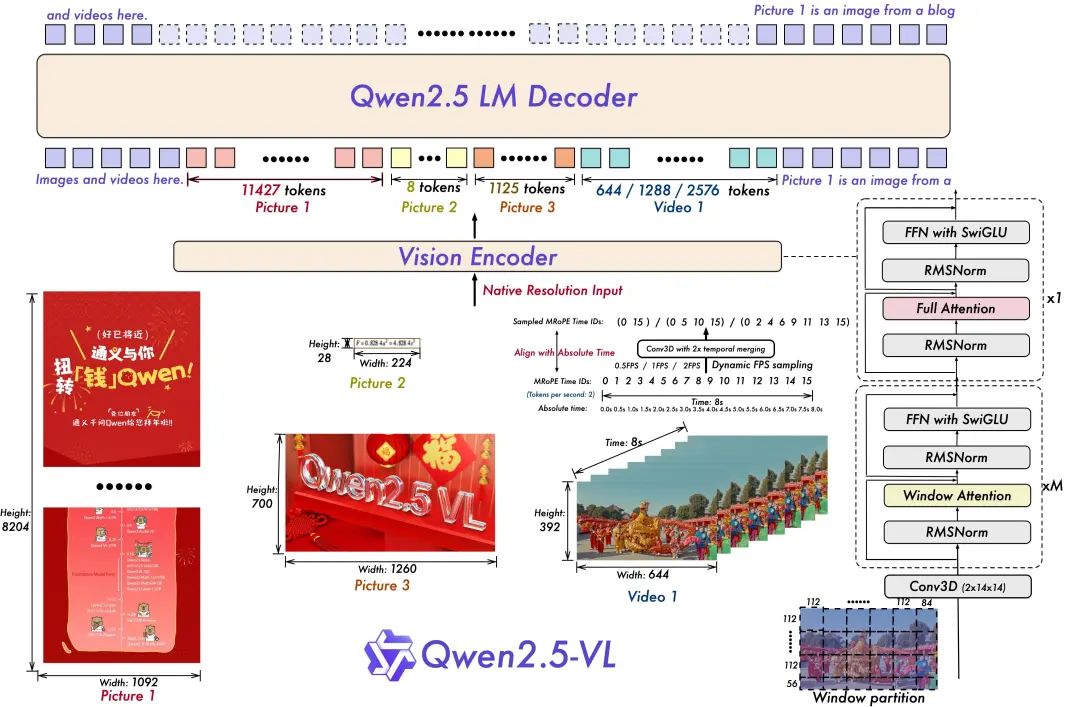
- Оптимизированный и эффективный визуальный кодер
Команда Qwen улучшила скорость обучения и вывода за счет стратегического внедрения механизма оконного внимания в ViT. Архитектура ViT была дополнительно оптимизирована с помощью SwiGLU и RMSNorm, чтобы согласовать ее со структурой Qwen 2.5 LLM.
В этом открытом источнике есть три модели с параметрами 3 миллиарда, 7 миллиардов и 72 миллиарда. Это репо содержит скорректированную командой модель 72B Qwen2.5-VL Модели.
Образцовый ансамбль:
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Опыт моделирования:
https://chat.qwenlm.ai/
Технологический блог:
https://qwenlm.github.io/blog/qwen2.5-vl/
Код Адрес:
https://github.com/QwenLM/Qwen2.5-VL
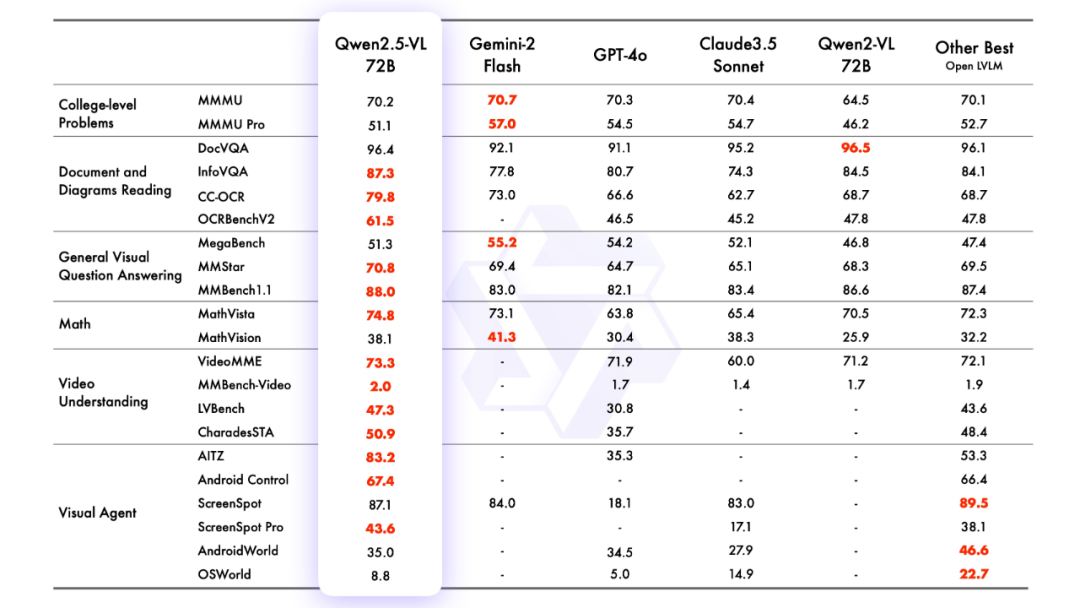
2.эффект моделирования
оценка моделирования
Г-н Хосе Мария Гонсалес
3.моделируемое рассуждение
Рассуждения с помощью трансформаторов
Код для Qwen2.5-VL находится в последних версиях трансформаторов, и рекомендуется собирать его из исходных текстов с помощью команды:
pip install git+https://github.com/huggingface/transformersДля облегчения работы с различными типами визуального ввода, как и в случае с API, предоставляется набор инструментов. Сюда входят base64, URL, чередующиеся изображения и видео. Установить его можно с помощью следующей команды:
pip install qwen-vl-utils[decord]==0.0.8Рассуждения о коде:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Вызывается напрямую с помощью API-инференции Magic Hitch
API-инференция платформы Magic Match также впервые обеспечивает поддержку моделей серии Qwen2.5-VL. Пользователи Magic Match могут использовать его непосредственно через вызовы API. Конкретный способ использования API-Inference можно найти на странице модели (например, https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct):

Или смотрите документацию по API-Inference:
https://www.modelscope.cn/docs/model-service/API-Inference/intro
Вот пример следующего изображения, вызывающего API с помощью модели Qwen/Qwen2.5-VL-72B-Instruct:

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
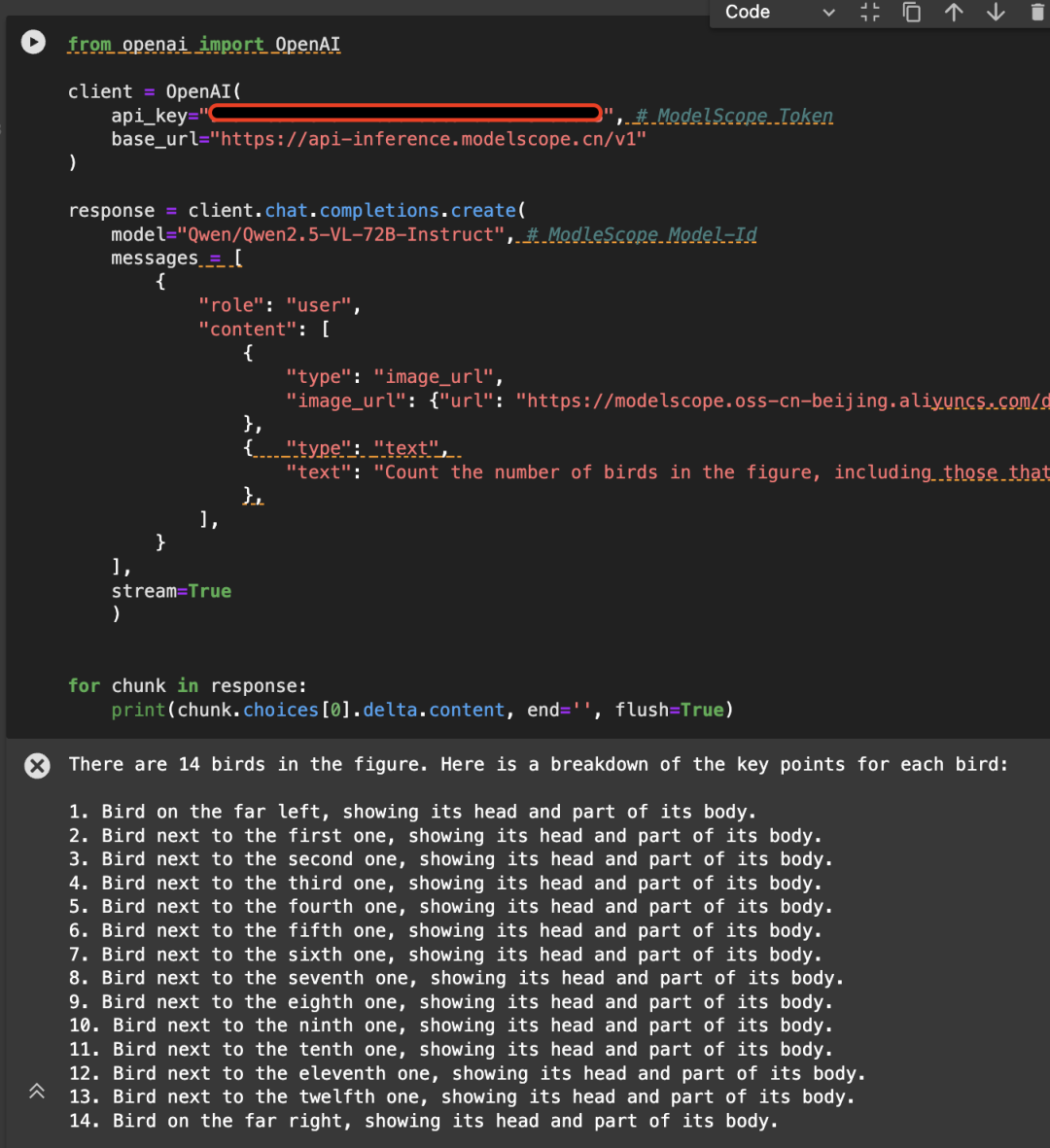
4. Тонкая настройка модели
Мы представляем использование ms-swift для тонкой настройки Qwen/Qwen2.5-VL-7B-Instruct. ms-swift - это сообщество magic ride, официально предоставляющее большую модель и мультимодальный фреймворк для тонкой настройки большой модели. адрес ms-swift с открытым исходным кодом:
https://github.com/modelscope/ms-swift
Здесь мы покажем запускаемые демо-версии тонкой настройки и приведем формат самоопределяемого набора данных.
Прежде чем приступать к тонкой настройке, убедитесь, что ваша среда готова.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Сценарий тонкой настройки OCR изображений выглядит следующим образом:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Ресурсы видеопамяти для обучения:

Скрипт тонкой настройки видео приведен ниже:
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Ресурсы видеопамяти для обучения:

Пользовательский формат набора данных выглядит следующим образом (поле system необязательно), просто укажите `--dataset `:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
Сценарий тонкой настройки задачи заземления выглядит следующим образом:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Ресурсы видеопамяти для обучения:

Формат пользовательского набора данных задачи заземления следующий:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
По завершении обучения вывод производится на валидном наборе, полученном в ходе обучения, с помощью следующей команды.
Здесь `--adapters` нужно заменить на последнюю папку контрольных точек, созданную в ходе обучения. Поскольку папка adapters содержит файлы параметров для обучения, нет необходимости дополнительно указывать `--model`:
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Переместите модель в ModelScope:
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...