Qwen2.5-1M: модель Qwen с открытым исходным кодом и поддержкой 1 миллиона контекстов токенов

1. Введение
Два месяца назад команда Qwen обновила Qwen2.5-Turbo для поддержки контекстов длиной до одного миллиона токенов. Сегодня Qwen официально представила модель Qwen2.5-1M с открытым исходным кодом и соответствующую поддержку фреймворка выводов. Вот основные моменты релиза:
Модели с открытым исходным кодом: Были выпущены две новые модели с открытым исходным кодом, а именно Qwen2.5-7B-Instruct-1M ответить пением Qwen2.5-14B-Instruct-1MВпервые компания Qwen расширила контекст модели Qwen с открытым исходным кодом до длины 1М.
Система рассуждений: Чтобы помочь разработчикам более эффективно внедрять семейство моделей Qwen2.5-1M, команда Qwen полностью открыла доступ к модели Qwen 2.5-1M, основанной на vLLM схема выводов с интегрированным подходом разреженного внимания, который позволяет ускорить обработку 1M помеченных входных данных на 3x - 7x.
Технический отчет: Команда Qwen также поделилась техническими деталями серии Qwen2.5-1M, в том числе дизайнерским мышлением, лежащим в основе систем обучения и вывода, а также результатами экспериментов по абляции.
Ссылка на модель:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
Технический отчет:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
Ссылки на опыт:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. Производительность модели
Сначала рассмотрим производительность моделей семейства Qwen2.5-1M в задачах с длинным контекстом и коротким текстом.
длинная контекстная задача
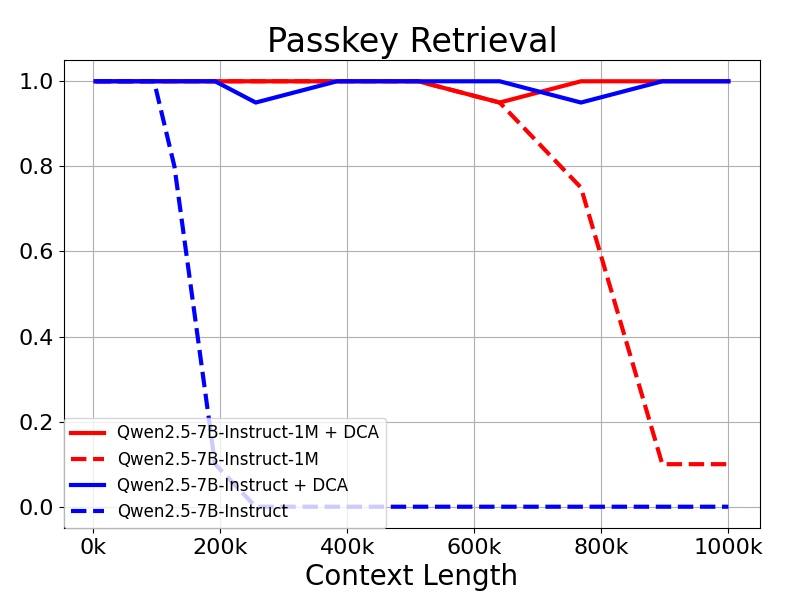
При длине контекста в 1 миллион Жетоны В задаче поиска ключей семейство моделей Qwen2.5-1M точно извлекало скрытую информацию из документов длиной 1M, при этом в модели 7B было допущено лишь несколько ошибок.
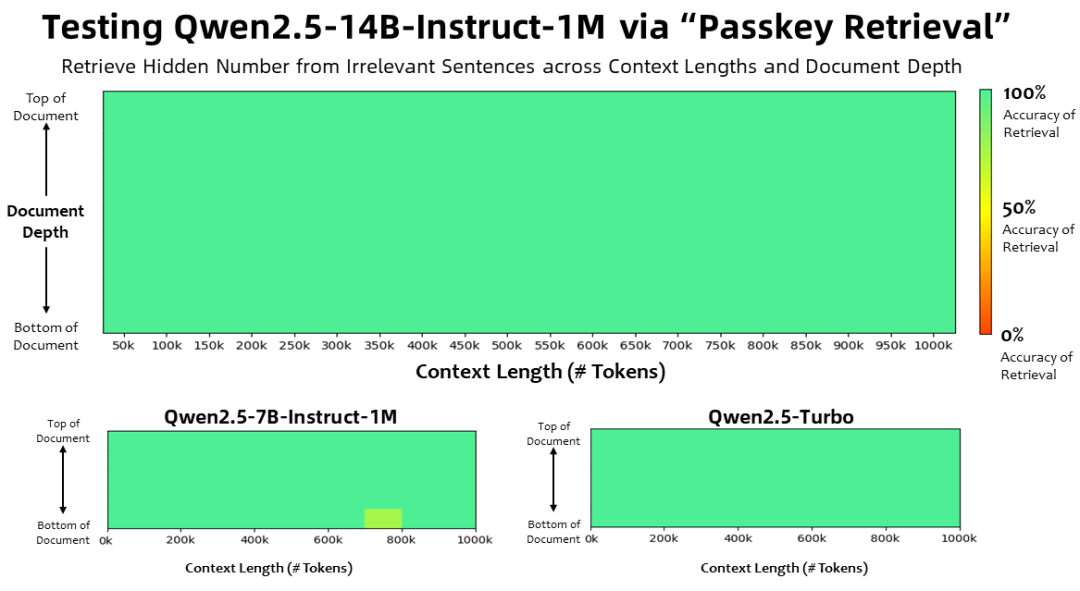
Для более сложных задач понимания длинного контекста были выбраны наборы тестов RULER, LV-Eval и LongbenchChat.
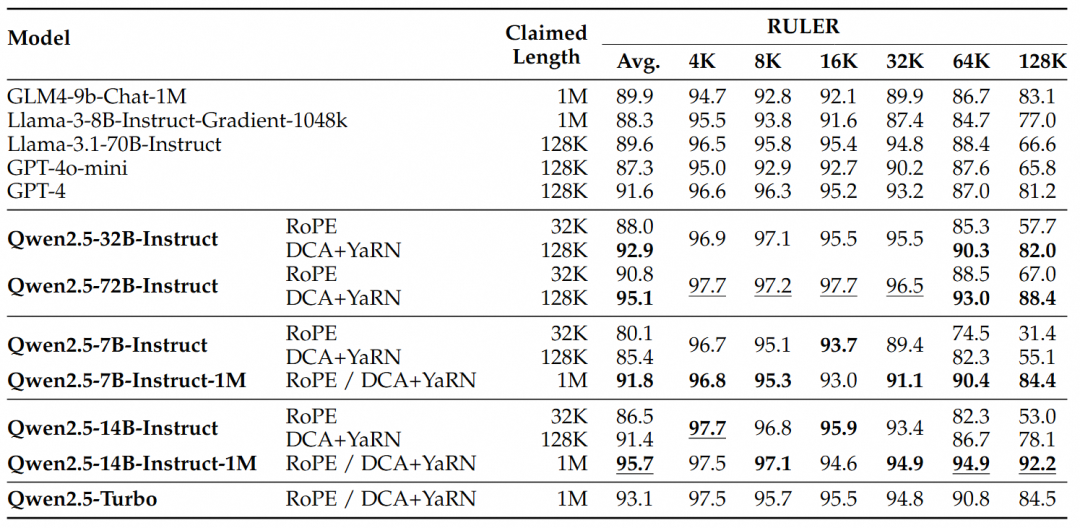
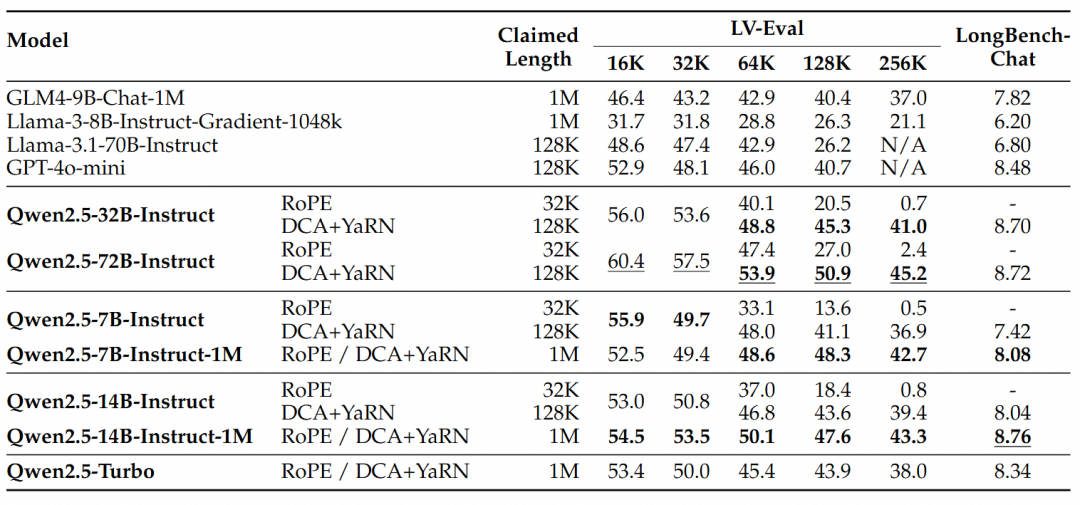
На основании этих результатов можно сделать следующие основные выводы:
- Значительно превосходит 128-килобайтную версию:Модели семейства Qwen2.5-1M значительно превосходят предыдущую 128-килобайтную версию в большинстве задач с длинным контекстом, особенно когда речь идет о задачах длиной более 64 Кбайт.
- Преимущества производительности очевидны:Модель Qwen2.5-14B-Instruct-1M не только выигрывает у Qwen2.5-Turbo, но и стабильно превосходит GPT-4o-mini на множестве наборов данных, обеспечивая выбор модели с открытым исходным кодом для задач с длинным контекстом.
короткая последовательная задача
Помимо производительности в задачах с длинными последовательностями, не менее важна производительность модели в коротких последовательностях. Модели серии Qwen2.5-1M и предыдущие 128K-версии сравнивались в широко распространенных академических бенчмарках, а для сравнения был добавлен GPT-4o-mini. 
Его можно найти:
- Производительность Qwen2.5-7B-Instruct-1M и Qwen2.5-14B-Instruct-1M в задаче с коротким текстом сопоставима с производительностью их 128-килобайтных версий, что гарантирует, что базовые возможности не пострадали в результате добавления возможностей обработки длинных последовательностей.
- По сравнению с GPT-4o-mini, Qwen2.5-14B-Instruct-1M и Qwen2.5-Turbo демонстрируют схожую производительность в задаче с коротким текстом, хотя длина контекста в восемь раз больше, чем у GPT-4o-mini.
3. Ключевые технологии
Длительное контекстное обучение
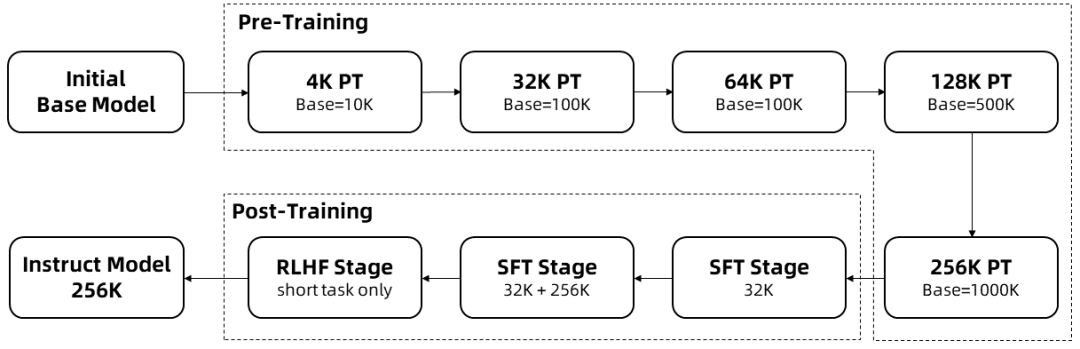
Обучение длинных последовательностей требует больших вычислительных ресурсов, поэтому для увеличения длины контекста в Qwen2.5-1M с 4K до 256K в несколько этапов использовалось пошаговое увеличение длины:
Начиная с промежуточной контрольной точки предварительно обученного Qwen2.5, длина контекста в этой точке равна 4К.
На этапе предварительной подготовкиКроме того, длина контекста была постепенно увеличена с 4K до 256K, а базовая частота RoPE была увеличена с 10 000 до 10 000 000 с помощью схемы Adjusted Base Frequency.
На этапе тонкой настройки мониторингаВ два этапа, чтобы сохранить производительность на коротких последовательностях:
Фаза I: Тонкая настройка производится только на коротких инструкциях (длиной до 32К), где используются те же данные и количество шагов, что и в 128К версии Qwen2.5.
Фаза II: Для повышения производительности длинных задач при сохранении качества коротких реализована смесь коротких (до 32К) и длинных (до 256К) инструкций.
На этапе интенсивного обучениякоторая обучает модель на коротких текстах (до 8 тыс. лексем). Мы обнаружили, что даже при обучении на коротких учебниках увеличение предпочтительного для человека выравнивания хорошо распространяется на задачи с длинным контекстом. В результате вышеописанного обучения мы получили модель Instruct, которая может обрабатывать последовательности длиной до 256 тыс. токенов.
С помощью вышеописанного обучения была получена модель тонкой настройки инструкций с длиной контекста 256 К.
Экстраполяция длины
В описанном выше процессе обучения длина контекста модели составляет всего 256K токенов. Для того чтобы увеличить ее до 1M токенов, используется метод экстраполяции длины.
В настоящее время крупномасштабные языковые модели, основанные на вращательном позиционном кодировании, демонстрируют снижение производительности в задачах с длинным контекстом, что в основном связано с большим относительным позиционным расстоянием между запросом и ключом, которое не учитывается в процессе обучения при вычислении весов внимания. Для решения этой проблемы в Qwen2.5-1M используется подход Dual Chunk Attention (DCA), который решает эту проблему, принимая чрезмерно большие относительные позиции и переставляя их на меньшие значения.
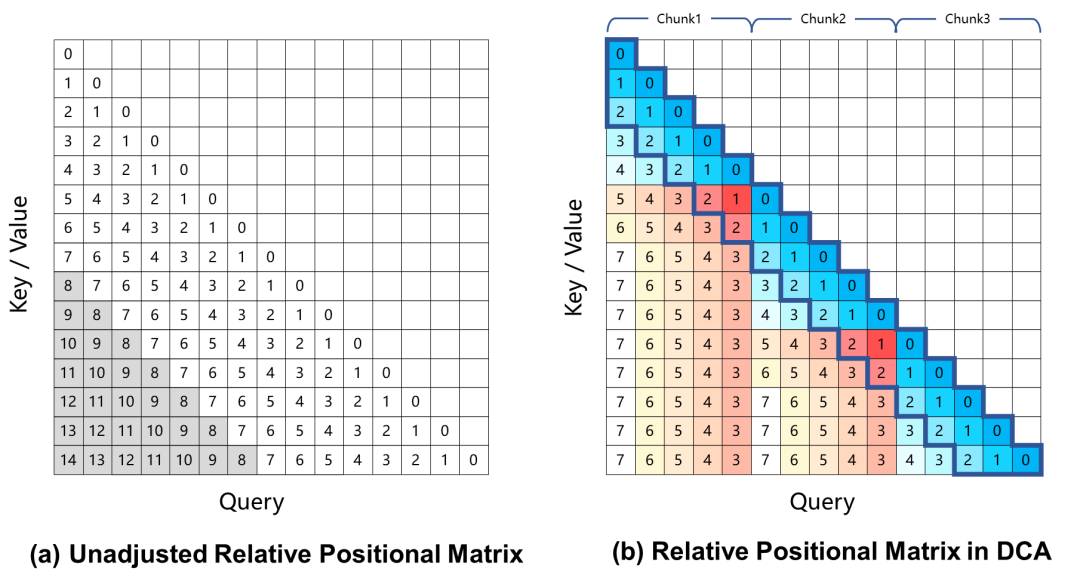
Модель Qwen2.5-1M и предыдущая версия 128K были оценены с использованием метода экстраполяции длины и без него.
Результаты показывают, что даже модели, обученные только на 32К токенов, такие как Qwen2.5-7B-Instruct, не справляются с контекстом Passkey, состоящим из 1М токенов. Поиск Задача также достигает почти идеальной точности. Это демонстрирует возможности DCA по значительному увеличению длины поддерживаемых контекстов без дополнительного обучения.
механизм разреженного внимания (в физике частиц)
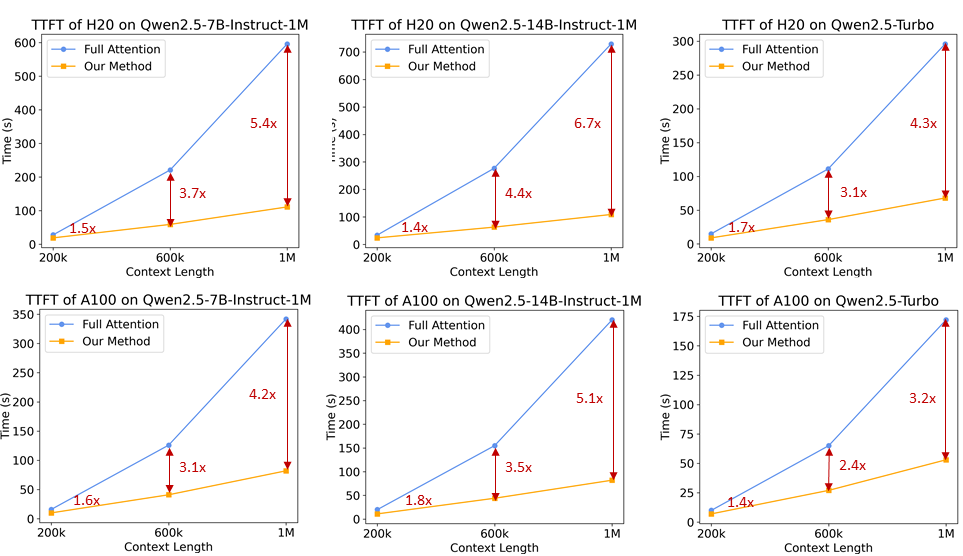
Для языковых моделей с длинным контекстом скорость вывода имеет решающее значение для удобства пользователей. Чтобы ускорить фазу предварительного заполнения, исследовательская группа представила механизм разреженного внимания, основанный на MInference. Кроме того, предложено несколько улучшений:
- Chunked Prefill: Если модель используется непосредственно для обработки последовательностей длиной до 1 миллиона, активационные веса слоя MLP занимают огромный объем памяти, до 71 ГБ в случае Qwen2-5-7B. Если взять в качестве примера Qwen2.5-7B, то эта часть накладных расходов достигает 71 ГБ. Адаптируя Chunked Prefill с Sparse Attention, входная последовательность может быть разбита на фрагменты длиной 32768 и заполнена по одному, а использование памяти для активационных весов на MLP-слое может быть уменьшено на 96,71 TP3T, что значительно снижает потребность устройства в памяти.
- Интегрированная схема экстраполяции длины: Мы также интегрировали схему экстраполяции длины на основе DCA в механизм разреженного внимания, что позволило нашей системе вывода получить более высокую эффективность и точность вывода для задач с длинными последовательностями.
- Оптимизация разреженности: оригинальный метод MInference требует автономного поиска для определения оптимальной конфигурации разреженности для каждой головки внимания. Этот поиск обычно выполняется на коротких последовательностях и не всегда хорошо работает с более длинными последовательностями из-за больших требований к памяти для полных весов внимания. Мы предлагаем метод, который позволяет оптимизировать конфигурацию спарсинга для последовательностей длиной 1 миллион, тем самым значительно снижая потери точности из-за разреженного внимания.
- Другие оптимизации: Мы ввели другие оптимизации, такие как оптимизация эффективности операторов и динамическое распараллеливание конвейеров, чтобы полностью использовать потенциал всего фреймворка.
Благодаря этим усовершенствованиям система выводов позволяет сократить число 1M. жетон Скорость предварительной популяции последовательностей такой длины увеличилась с 3,2 раза до 6,7 раза.
4. развертывание модели
Подготовка системы
Для достижения наилучшей производительности рекомендуется использовать GPU с архитектурой Ampere или Hopper, поддерживающий оптимизированные ядра.
Убедитесь, что следующие требования соблюдены:
- Версия CUDA: 12.1 или 12.3
- Версия Python: >=3.9 и <=3.12
Требования к памяти для обработки последовательностей длиной 1 М:
- Qwen2.5-7B-Instruct-1M: Требуется не менее 120 ГБ видеопамяти (сумма нескольких GPU).
- Qwen2.5-14B-Instruct-1M: Требуется не менее 320 ГБ видеопамяти (сумма нескольких GPU).
Если память GPU не соответствует этим требованиям, вы все равно можете использовать Qwen2.5-1M для более коротких задач.
Установка зависимостей
На данный момент вам нужно клонировать репозиторий vLLM из пользовательской ветки и установить его вручную. Исследовательская группа работает над фиксацией этой ветки в проекте vLLM.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
Запуск API-службы, совместимой с OpenAI
Указывает, что модель должна быть загружена из ModelScope
export VLLM_USE_MODELSCOPE=True
Выпуск совместимых с OpenAI API-сервисов
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
Описание параметра:
--tensor-parallel-size- Установите количество используемых графических процессоров. Модели 7B поддерживают до 4 GPU, а модели 14B - до 8 GPU.
--max-model-len- Определяет максимальную длину входной последовательности. Уменьшите это значение, если возникнут проблемы с нехваткой памяти.
--max-num-batched-tokens- Устанавливает размер блока для Chunked Prefill. Меньшее значение уменьшает использование памяти при активации, но может замедлить вывод.
- Рекомендуемое значение - 131072 для оптимальной производительности.
--max-num-seqs- Ограничьте количество последовательностей, обрабатываемых одновременно.
Взаимодействие с моделями
Для взаимодействия с развернутой моделью можно использовать следующие методы:
Вариант 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
Вариант 2. Используйте Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
Вы также можете изучить другие фреймворки, такие как Qwen-Agent, чтобы позволить моделям читать PDF-файлы и т. д.
5. Используйте API-инференцию Magic Hitch, чтобы напрямую вызвать
API-Inference платформы Magic Match также впервые обеспечивает поддержку моделей Qwen2.5-7B-Instruct-1M и Qwen2.5-14B-Instruct-1M. Пользователи Magic Hitch могут использовать модели напрямую с помощью вызовов API. Конкретное использование API-вызовов может быть описано на странице модели (например, https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M ):

Или смотрите документацию по API-Inference: https://www.modelscope.cn/docs/model-service/API-Inference/intro.
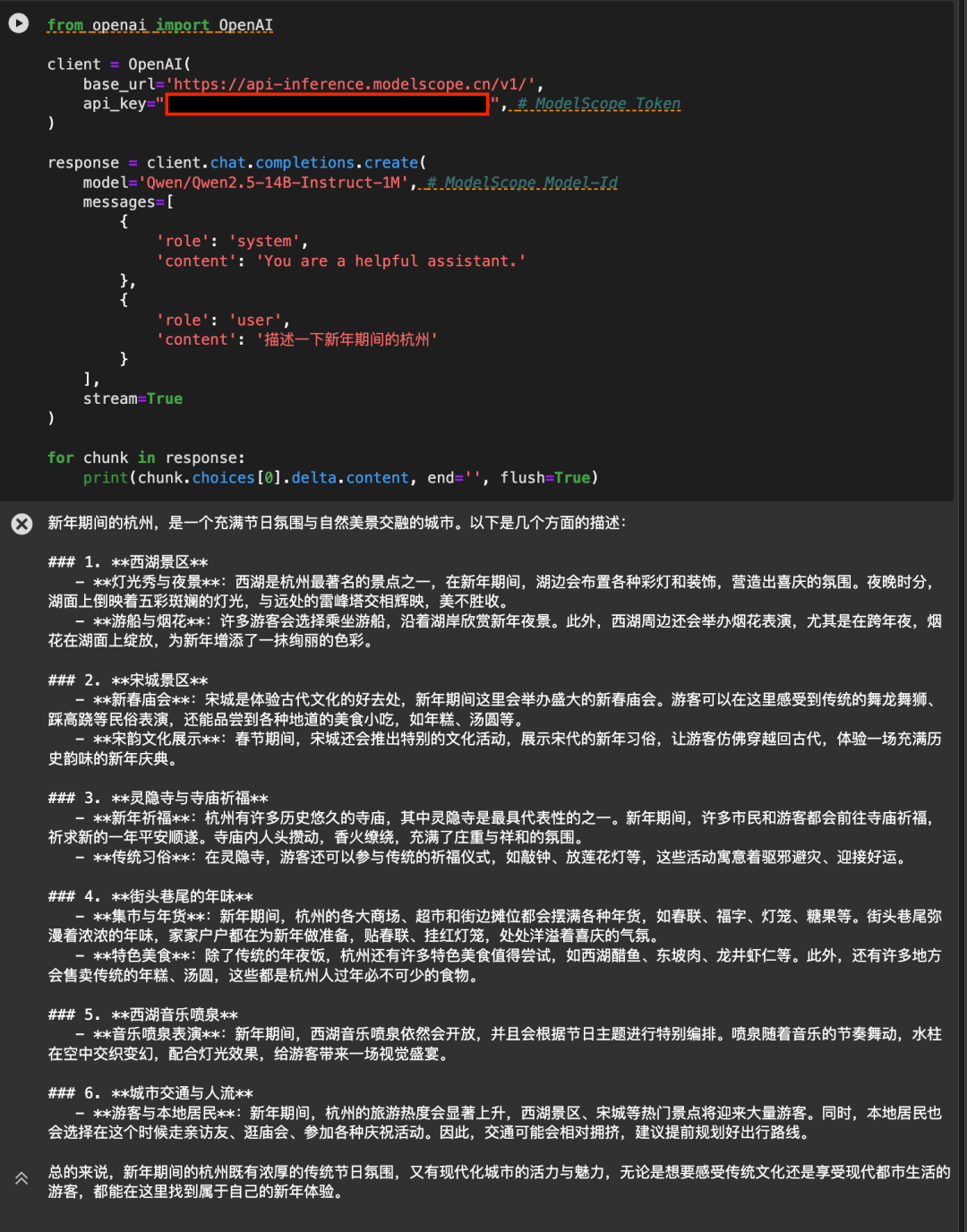
Спасибо AliCloud Hundred Refinement Platform за арифметическую поддержку за кулисами.
Использование Ollama и llamafile
Для того чтобы облегчить ваше локальное использование, Magic Hitch предоставляет версию GGUF и llamafile модели Qwen2.5-7B-Instruct-1M. Ее можно вызвать с помощью фреймворка Ollama или использовать llamafile напрямую.
1. Звонок Олламы
Сначала установите ollama в разделе enable:
ollama serve
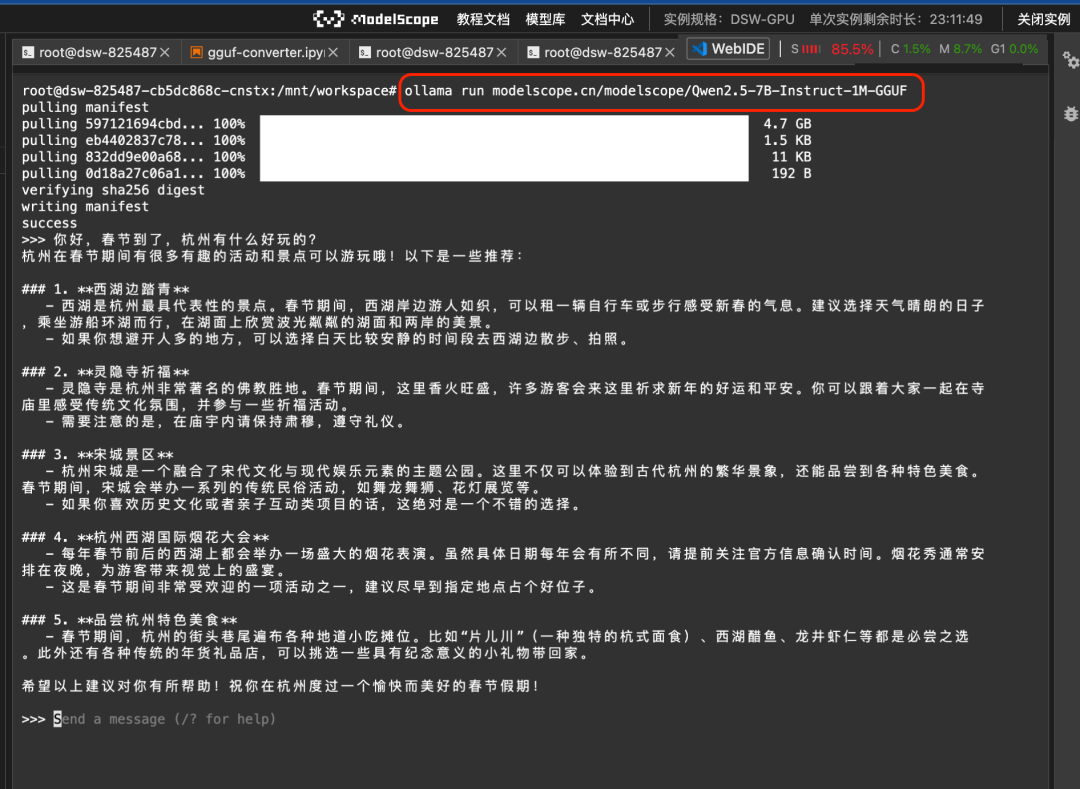
Затем вы можете запустить модель GGUF на Magic Hitch напрямую с помощью команды ollama run:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFРезультаты забега:
2. llamafile модель pull-up напрямую
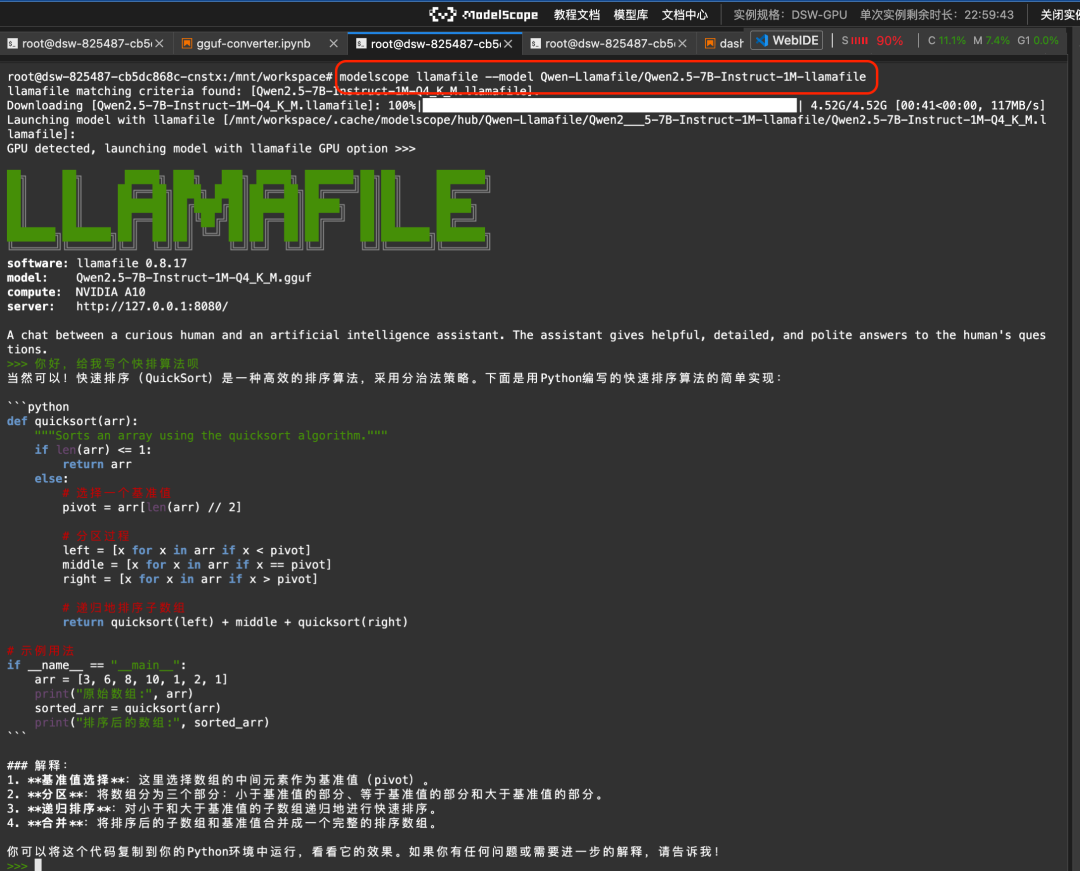
Llamafile Предоставляет решение, в котором большая модель и среда выполнения заключены в одном исполняемом файле. Благодаря интеграции командной строки Magic Ride и llamafile, вы можете запускать большую модель одним щелчком мыши в различных операционных системах, таких как Linux/Mac/Windows:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileРезультаты забега:
Дополнительную документацию можно найти на сайте https://www.modelscope.cn/docs/models/advanced-usage/llamafile.
6. Тонкая настройка модели
Здесь мы представляем тонкую настройку Qwen/Qwen2.5-7B-Instruct-1M с помощью ms-swift.
Прежде чем приступить к тонкой настройке, убедитесь, что среда установлена правильно:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Мы предоставляем запускаемые демо-версии тонкой настройки и стили для пользовательских наборов данных, а скрипты тонкой настройки выглядят следующим образом:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
Использование видеопамяти при обучении:

Пользовательский формат набора данных: (просто укажите его напрямую, используя `--dataset `)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
Сценарий рассуждений:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
Переместите модель в ModelScope:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. Что дальше?
Хотя семейство Qwen2.5-1M предлагает отличные возможности с открытым исходным кодом для решения задач обработки длинных последовательностей, исследовательская группа прекрасно понимает, что модели с длинным контекстом еще многое могут улучшить. Наша цель - создать модели, которые будут отлично справляться как с короткими, так и с длинными задачами, чтобы они были действительно полезны в реальных сценариях применения. Для этого команда работает над более эффективными методами обучения, архитектурой моделей и подходами к рассуждениям, чтобы эти модели могли быть развернуты эффективно и с оптимальной производительностью даже в условиях ограниченных ресурсов. Команда уверена, что эти усилия откроют новые возможности для длинных контекстных моделей, значительно расширят сферу их применения и продолжат расширять границы области, так что следите за новостями!
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...