
"Злоупотребление ИИ: 13 ключевых вопросов о новом китайском направлении управления ИИ

Недавно Центральное управление информационных технологий Интернета запустило специальную акцию под названием "Очистить - исправить злоупотребление технологией искусственного интеллекта", которая проводит четкую красную линию для управления рядом вопросов, возникших в ходе современного развития искусственного интеллекта. Эта инициатива призвана направить здоровое развитие технологий ИИ и предотвратить потенциальные риски. Специальная акция сосредоточена на 13 ключевых направлениях и разделена на два этапа с подробными требованиями к продуктам, услугам, контенту и поведенческим нормам в области ИИ.
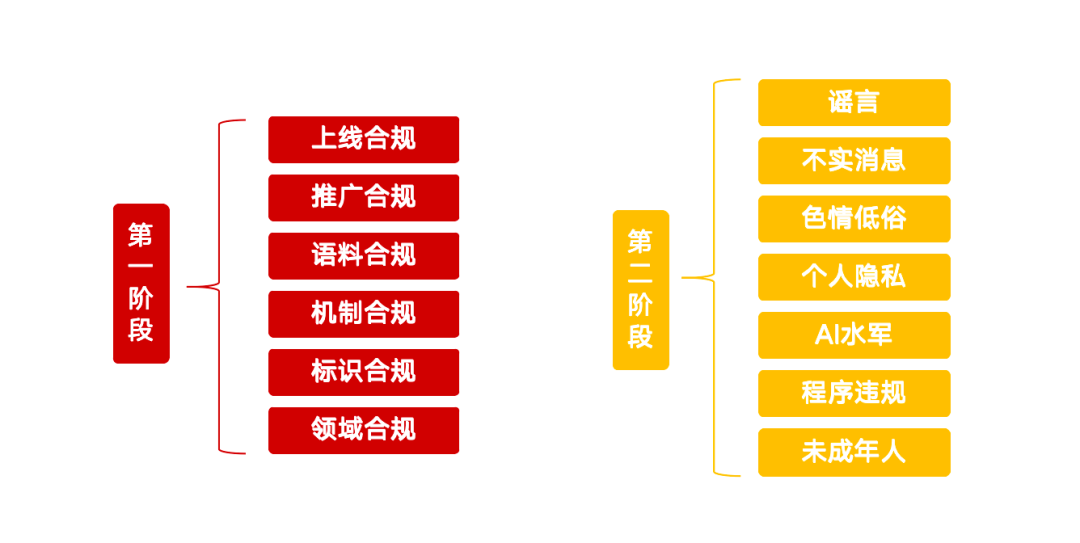
Этап I: управление и инфраструктура источника
Первый этап акции направлен на управление источниками технологий искусственного интеллекта, цель которого - очистка приложений искусственного интеллекта от нарушений, усиление управления маркировкой контента и улучшение способности платформы обнаруживать и идентифицировать контрафакт.
Продукты искусственного интеллекта, не соответствующие требованиям, должны пройти онлайн-тестирование
Регулятор отметил, что приложения, использующие технологию генеративного искусственного интеллекта для предоставления услуг населению, должны пройти процедуру подачи или регистрации крупной модели. Это требование основано на статье 17 Временных мер по управлению услугами генеративного искусственного интеллекта (далее - Временные меры), в которой четко указано, что продукты ИИ должны пройти оценку безопасности перед официальным запуском. Цикл подачи заявки обычно занимает от трех до шести месяцев. Кроме того, закон запрещает предоставлять незаконные и неэтичные функции, такие как "раздевание в один клик", а также клонировать или редактировать биометрические характеристики других людей (например, голоса и лица) без разрешения.
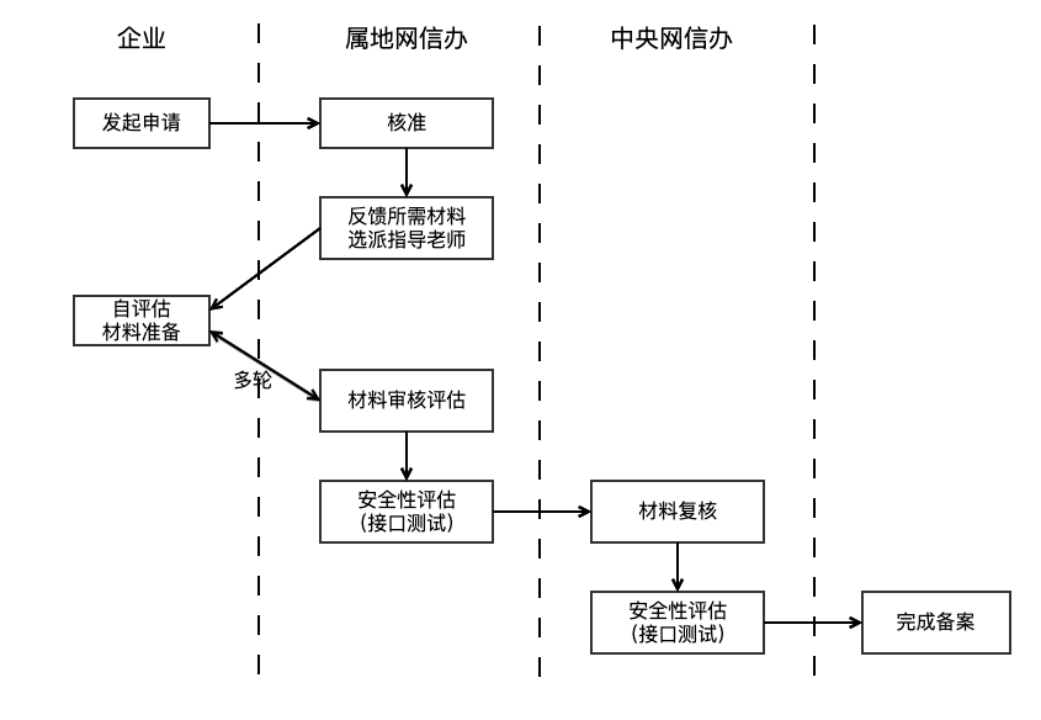
Выявление и регулирование незарегистрированных услуг ИИ стало сложной задачей. Регулирующие органы могут использовать технические средства, такие как веб-краулеры, для мониторинга различных типов платформ, определяя, вызывают ли сервисы API-интерфейсы больших моделей (например, генерация диалогов, синтез изображений) и каковы их технические особенности. Что касается соответствия функциональному дизайну, то помимо внутренней правовой оценки и аудита магазинов приложений, регулирование услуг неофициальных каналов в настоящее время в большей степени опирается на сообщения о жалобах пользователей. Поставщики услуг должны самостоятельно проверять, прошли ли продукты ИИ двойную регистрацию (регистрация крупной модели и регистрация алгоритма), и убедиться, что функциональный дизайн соответствует спецификациям.
Продвижение соответствия: борьба с незаконными учебниками и товарами по продуктам искусственного интеллекта
Специальное действие также направлено на продвижение продуктов ИИ. Учебные пособия, обучающие использованию несоответствующих продуктов ИИ для создания видеороликов с изменением лица и голоса, продажа несоответствующих продуктов, таких как "синтезаторы голоса" и "инструменты для изменения лица", а также маркетинг и продвижение несоответствующих продуктов ИИ - все это включено в меры по исправлению ситуации. Промоутеры обязаны проверять соответствие продуктов ИИ требованиям, прежде чем принимать решение об их продвижении. Платформам необходимо усилить аудит контента, чтобы не только убедиться в том, что сам контент является законным, но и иметь возможность выявлять и проверять на соответствие требованиям продукты ИИ, продвигаемые в контенте, например, с помощью первоначальной проверки семантических моделей, дополненной ручным вмешательством.
Соответствие корпусу: источники данных для обучения и управление ими в фокусе
Соответствие обучающих данных - основа безопасности моделей ИИ. В статье 7 Временных мер подчеркивается, что поставщики услуг должны использовать данные и базовые модели из легитимных источников. Основные требования к безопасности генеративных сервисов ИИ (далее - Основные требования) уточняются и предусматривают, что если корпус содержит более 51 TP3T незаконной и нежелательной информации, то источник не должен быть собран. В то же время четко определено разнообразие источников данных, протоколы открытых источников, учет самостоятельно собранных данных и юридические процедуры для приобретения коммерческих данных.
В силу конфиденциальности данных и технической тайны регулирование учебных корпусов довольно сложно и обычно принимает форму допроса и вещественных доказательств. Кроме того, предприятия сталкиваются с большими трудностями в управлении огромными объемами обучающих данных со сложными источниками и разным качеством. Основные требования рекомендуют предприятиям сочетать фильтрацию по ключевым словам, проверку классификационных моделей и ручную выборку для очистки корпуса от незаконной и нежелательной информации.
Соответствие механизмам: усиленные меры по обеспечению безопасности
Предприятиям необходимо создать механизмы безопасности, такие как аудит контента и распознавание намерений, соответствующие масштабам их бизнеса, а также эффективный процесс управления учетными записями, не соответствующими требованиям, и регулярную систему самооценки безопасности. В отношении таких сервисов, как автоматические ответы ИИ, доступ к которым осуществляется через API-интерфейсы, социальные платформы должны быть внимательны и строги. Глава 7 "Основных требований" требует от поставщиков услуг отслеживать вводимые пользователями данные и принимать такие меры, как ограничение услуг для пользователей, которые неоднократно вводят незаконную информацию. Кроме того, компании должны иметь в своем штате сотрудников по надзору, соответствующих масштабам их услуг, ответственных за отслеживание политики и анализ жалоб с целью повышения качества и безопасности контента. Надежный механизм контроля рисков является необходимым условием для запуска продуктов ИИ.
Соответствие маркировке: реализация требований к маркировке контента, созданного искусственным интеллектом
Для повышения прозрачности Меры по маркировке синтетического контента, созданного искусственным интеллектом (далее - Меры по маркировке), предусматривают, что поставщики услуг должны добавлять явные или неявные маркировки к глубоко синтезированному контенту и обеспечивать включение явных маркировок в файл, а неявных - в метаданные, когда пользователь скачивает или копирует файл. Этот подход сопровождается национальным стандартом "Метод идентификации синтетического контента, генерируемого искусственным интеллектом, с помощью технологии сетевой безопасности", который вступит в силу с 1 сентября 2025 года. Предприятия должны проводить самопроверку на основе этого стандарта и внедрять технические средства для обнаружения контента, созданного искусственным интеллектом, на своих платформах и предоставлять предупреждения о подозрительном контенте. Регулирующие органы могут также повысить уровень просвещения пользователей для улучшения общественного признания контента, созданного ИИ.
Соответствие доменам: внимание к рискам безопасности в ключевых отраслях
Продукты ИИ, которые были поданы на предоставление услуг Q&A в таких ключевых областях, как здравоохранение, финансы и несовершеннолетние, должны установить отраслевые аудиты безопасности и меры контроля. Предотвращение явления "предписания ИИ", побуждения к инвестированию или использования "иллюзии ИИ" для введения пользователей в заблуждение. Управление соответствием нормативным требованиям в этих специфических областях является сложным и сегментированным, требующим знаний экспертов в данной области и специализированного свода нормативных требований. Отраслевые регуляторы и головные компании будут играть ключевую роль в установлении стандартов и обеспечении мер безопасности. Общие решения включают обнаружение галлюцинаций, ручное утверждение ключевых операций и т. д. для защиты от риска потери контроля со стороны ИИ.
Этап II: пресечение использования ИИ для незаконной и противоправной деятельности
Второй этап специальных действий будет направлен на использование технологий искусственного интеллекта для создания и распространения слухов, недостоверной информации, порнографического и вульгарного контента, а также для выдачи себя за других людей и участия в деятельности киберсквад.
Противодействие использованию искусственного интеллекта для создания и публикации слухов
В сферу исправления входят фабрикация слухов, связанных с текущими делами и средствами к существованию людей, из воздуха, злонамеренная интерпретация политики, фабрикация деталей на основе чрезвычайных ситуаций, выдача информации за официальные релизы, а также злонамеренное руководство, используя когнитивные предубеждения ИИ. Китайская объединенная интернет-платформа по развенчанию слухов действует уже давно, но в эпоху ИИ снижение стоимости производства слухов и повышение их достоверности ставят новые задачи в области управления. Регулирование в основном опирается на мониторинг общественного мнения и сообщения пользователей, а штрафы за слухи об ИИ в ключевых областях могут быть ужесточены. Поставщикам услуг необходимо улучшить свои возможности по выявлению слухов, генерируемых ИИ, например, использовать инструменты ИИ для калибровки точности контента, отслеживать аномальное поведение учетных записей и вручную проверять контент в горячих точках.
Устранение использования ИИ для производства и публикации недостоверной информации
К таким видам поведения относятся соединение и редактирование несвязанных графических и видеоматериалов для создания смешанной информации, размывание и изменение фактических элементов, пересказ старых новостей, публикация преувеличенных или псевдонаучных материалов, связанных с профессиональной деятельностью, распространение суеверий с помощью гаданий и предсказаний искусственного интеллекта и так далее. По сравнению со слухами, недостоверная информация может быть менее субъективной и вредоносной, но ее скрытую природу и потенциальное влияние нельзя игнорировать. Управление в основном зависит от контент-платформ, которые должны укреплять экологическое строительство, выявлять некачественный контент с помощью технических средств и принимать меры по ограничению распространения соответствующего контента и создателей или налагать штрафы.
Исправление ситуации с использованием искусственного интеллекта для производства и распространения порнографического и вульгарного контента
Использование ИИ для создания порнографических или непристойных изображений и видео, таких как "раздевание в один клик" и рисование ИИ, а также создание мягкой порнографии, порнографических изображений второго поколения, кровавого насилия, гротескных и гротескных изображений и "мелкого желтого текста" - все это подлежит пресечению. Хотя технология искусственного интеллекта повышает эффективность производства контента, она также может быть использована не по назначению для создания такого нежелательного контента. Традиционные методы проверки, такие как библиотеки ключевых слов, семантические модели и классификация изображений ("модели идентификации порнографии"), являются относительно зрелыми для идентификации пользовательского контента (UGC). Однако распределение признаков контента, созданного искусственным интеллектом, может отличаться от распределения признаков пользовательского контента, и поставщикам услуг необходимо уделять внимание обновлению данных для обучения моделей, чтобы поддерживать точность идентификации.
Расследование и борьба с использованием искусственного интеллекта для выдачи себя за других людей с целью совершения преступлений, связанных с нарушением авторских прав
Такие действия, как выдача себя за общественных деятелей с помощью подмены лица, клонирования голоса и других методов глубокой подделки с целью обмана или получения прибыли, подмена и дискредитация общественных деятелей или исторических фигур, использование ИИ для выдачи себя за друзей и родственников с целью мошенничества, а также неправомерное использование ИИ для "воскрешения мертвых" и неправомерное использование информации об умерших, - все это является предметом борьбы. Такие риски связаны с утечкой и неправомерным использованием данных о личной жизни. Важно повышать осведомленность населения о защите частной жизни и в долгосрочной перспективе создать механизм отслеживания данных, чтобы обеспечить соблюдение требований по всей цепочке передачи данных.
Противодействие использованию ИИ в кибернаемнической деятельности
"Водная армия ИИ" - это новый вариант сетевой водной армии. Использование технологий ИИ для "поднятия" массовой регистрации и работы социальных аккаунтов, использование контент-ферм ИИ или промывки рукописей ИИ для массовой генерации низкокачественного гомогенизированного контента, а также использование программного обеспечения для контроля групп ИИ, социальных роботов для контроля и оценки и другие виды поведения будут жестко пресекаться. Управление должно начинаться с двух измерений - контента и аккаунта, выявления низкокачественного и AIGC-контента на платформе, мониторинга поведенческих характеристик аккаунтов, публикующих AIGC-контент, и автоматизации быстрого вмешательства, чтобы увеличить стоимость зла водных армий.
Регулирование поведения услуг и приложений продуктов ИИ
Производство и распространение поддельных и поддельных веб-сайтов и приложений ИИ, предоставление несоответствующих функций приложениями ИИ (например, предоставление "горячего поиска и расширения горячих списков" средствами авторинга), предоставление вульгарных и мягких порнографических диалоговых услуг программами социальных чатов ИИ, а также продажа и продвижение несоответствующих приложений, услуг или курсов ИИ, которые отвлекают пользователей, - все это входит в сферу действия мер по исправлению ситуации. Это еще раз подчеркивает соответствие требованиям при запуске и распространении продуктов ИИ, а также добавляет определение "оболочки" и незаконных функций. Поставщики услуг должны придерживаться изначального намерения, чтобы технологии служили людям.
Защита прав и интересов несовершеннолетних от ИИ
ИИ-приложения, склоняющие несовершеннолетних к зависимости, или контент, влияющий на их физическое и психическое здоровье, все еще существует в режиме для несовершеннолетних, - еще одно направление этой специальной акции. Модели ИИ основаны на вероятностной статистике, и существует непредсказуемость генерируемого ими контента, который может выдавать неверные значения и представлять потенциальный риск для роста несовершеннолетних. Поэтому применение ИИ в сценариях обучения несовершеннолетних требует особой осторожности и строгого контроля за использованием сценариев; в других продуктах с высокой частотой контакта с несовершеннолетними следует усилить режим для несовершеннолетних и ограничить права на применение ИИ.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...