
Prompt Advanced Tips: Точный контроль вывода LLM и определение логики выполнения с помощью псевдокода

Как мы все знаем, когда нам нужно дать большой языковой модели выполнить задачу, нам нужно ввести подсказку, чтобы направить ее выполнение, которая описывается с помощью естественного языка. Для простых задач естественный язык может описать их четко, например: "Пожалуйста, переведите следующее на упрощенный китайский:", "Пожалуйста, сгенерируйте резюме следующего:" и так далее.
Однако когда мы сталкиваемся со сложными задачами, например, требующими от модели генерировать определенный формат JSON, или задача имеет несколько ветвей, каждая ветвь должна выполнять несколько подзадач, и подзадачи взаимосвязаны друг с другом, то описания на естественном языке недостаточно.
тема для обсуждения
Вот два вопроса для размышления, которые стоит попробовать задать, прежде чем читать дальше:
- Имеется несколько длинных предложений, каждое из которых необходимо разбить на более короткие предложения длиной не более 80 символов, а затем вывести в формат JSON, который четко описывает соответствие между длинными и короткими предложениями.
Например:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- Оригинальный текст с субтитрами, содержащий только информацию о диалогах, из которого вам нужно извлечь главы, дикторов, а затем перечислить диалоги по главам и параграфам. Если дикторов несколько, каждый диалог должен предваряться диктором, но не в том случае, если один и тот же диктор говорит подряд. (На самом деле это GPT, который я сам использую для организации видеосценариев. Свертка видеосценариев GPT)
Пример ввода:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Образец вывода:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
Суть Prompt
Возможно, вы прочитали много статей в интернете о том, как писать техники Prompt, и запомнили множество шаблонов Prompt, но в чем суть Prompt? Зачем нам нужен Prompt?
Prompt - это, по сути, управляющая инструкция для LLM, описанная на естественном языке, которая позволяет LLM понять наши требования и затем превратить входные данные в желаемые выходные данные, как это необходимо.
Например, часто используемая техника "нескольких выстрелов" заключается в том, чтобы дать LLM понять наши требования на примерах, а затем обратиться к примерам, чтобы вывести желаемые результаты. Например, CoT (Chain of Thought) - это искусственная декомпозиция задачи и ограничение процесса выполнения, чтобы LLM мог следовать указанному нами процессу и шагам, не слишком распыляясь и не пропуская ключевые этапы, и таким образом получать лучшие результаты.
Как в школе, когда учитель рассказывает о математических теоремах, он должен приводить примеры, чтобы мы могли понять смысл теорем на примерах; когда мы проводим эксперименты, нам должны рассказать о шагах эксперимента, и даже если мы не понимаем принципов эксперимента, но можем выполнить эксперимент в соответствии с шагами, мы все равно получим более или менее одинаковые результаты.
Почему иногда результаты работы Prompt оказываются не самыми лучшими?
Это связано с тем, что LLM не может точно понять наши требования, которые ограничены, с одной стороны, способностью LLM понимать и следовать инструкциям, а с другой - ясностью и точностью описания Prompt.
Как точно управлять выходом LLM и определять логику его выполнения с помощью псевдокода
Поскольку Prompt - это, по сути, управляющая инструкция для LLM, мы можем написать Prompt, не ограничиваясь традиционными описаниями на естественном языке, но и использовать псевдокод для точного управления выходом LLM и определения логики его выполнения.
Что такое псевдокод?
Псевдокод - это формальный метод описания алгоритмов, который представляет собой нечто среднее между естественным языком и языком программирования для описания шагов и процессов алгоритма. В различных книгах и статьях по алгоритмам мы часто видим описание псевдокода, даже не обязательно знать язык, но и через псевдокод можно понять выполнение потока алгоритма.
Насколько хорошо LLM понимает псевдокод? На самом деле, понимание псевдокода у LLM довольно сильное, LLM обучался на большом количестве качественного кода и может легко понять смысл псевдокода.
Как написать псевдокод Prompt?
Псевдокод хорошо знаком программистам, а для непрограммистов можно написать простой псевдокод, просто запомнив несколько основных правил. Несколько примеров:
- Переменные, которые используются для хранения данных, например, для представления входных данных или промежуточных результатов с помощью определенных символов
- Тип, используемый для определения типа данных, таких как строки, числа, массивы и т.д.
- функция, определяющая логику выполнения конкретной подзадачи
- Поток управления, используемый для управления процессом выполнения программы, например, циклы, условные суждения и т.д.
- Оператор if-else, если выполняется условие A, то выполняется задача A, в противном случае выполняется задача B.
- Цикл for, выполняющий задание для каждого элемента массива.
- В цикле while, когда выполняется условие A, задача B будет выполняться непрерывно.
Теперь давайте напишем псевдокод Prompt, используя в качестве примера два предыдущих вопроса для размышления.
Псевдокод для вывода определенного формата JSON
Желаемый формат JSON можно наглядно описать с помощью псевдокода, похожего на определение типа в TypeScript:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Организация сценариев субтитров с помощью псевдокода
Если представить себе, что вы пишете программу для выполнения этой задачи, то в ней может быть много этапов, например, извлечение глав, затем извлечение дикторов и, наконец, свертка диалогов по главам и дикторам. С помощью псевдокода мы можем разложить эту задачу на несколько подзадач, для которых даже не нужно писать конкретный код, а нужно лишь четко описать логику выполнения подзадач. Затем пошагово выполнить эти подзадачи и, наконец, интегрировать полученный результат.
Мы можем использовать некоторые переменные для хранения, например subject, иspeakers, иchapters, иparagraphs и т.д.
При выводе мы также можем использовать циклы For для перебора глав и параграфов, а также операторы If-else, чтобы определить, нужно ли нам выводить имя докладчика.
Ваша задача - реорганизовать транскрипты видео для удобства чтения и распознавать дикторов в многоместных диалогах. Вот псевдокод, как это сделать Вот псевдокоды того, как это сделать
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Посмотрим, что из этого получится:
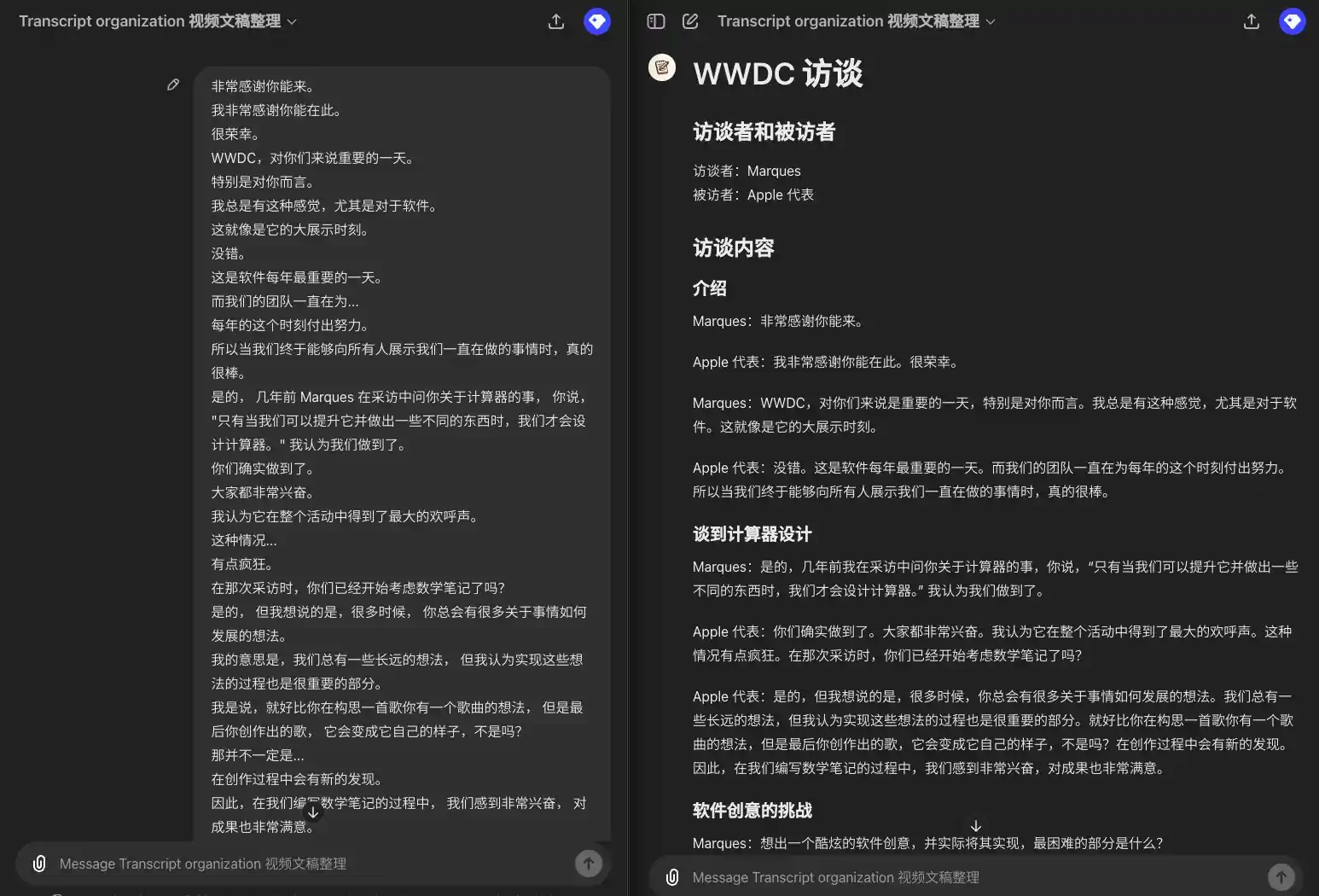
Составление стенограмм доступа к WWDC
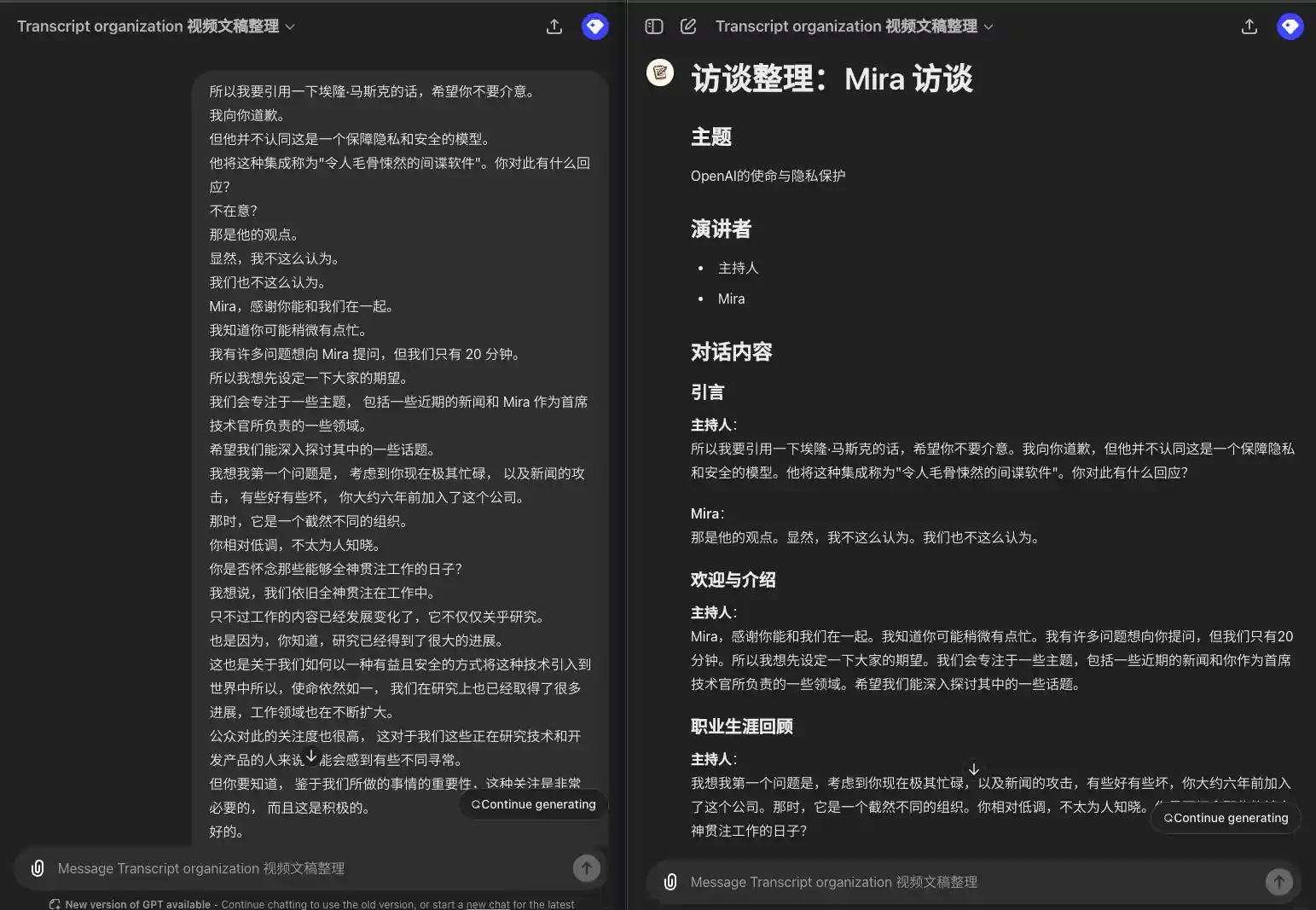
Многочисленные ораторы, шоу ораторов
1 Динамик, динамик не показан
Вы также можете просто использовать GPT, который я сгенерировал с помощью этого Prompt:Транскрипционная организация GPT
Заставьте ChatGPT рисовать несколько изображений одновременно с помощью псевдокода
Недавно я также узнал об очень интересном использовании этого термина от тайваньского нетизена, сэнсэя Юн Санг-чи.Заставьте ChatGPT рисовать несколько изображений одновременно с помощью псевдокода.
Теперь, если вы хотите сделать ChatGPT Рисунок, как правило, генерирует только одну картинку за раз, если вы хотите генерировать более одной картинки за раз, вы можете использовать псевдокод, чтобы разбить задачу генерации нескольких картинок на несколько подзадач, а затем выполнить несколько подзадач одновременно, и, наконец, интегрировать результат на выходе.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

резюме
На примере выше мы видим, что с помощью псевдокода мы можем более точно контролировать выходной результат LLM и определять логику его выполнения, а не ограничиваться описанием на естественном языке. Когда мы сталкиваемся со сложными задачами или задачами с несколькими ветвями, каждая из которых должна выполнять несколько подзадач, и эти подзадачи связаны друг с другом, использование псевдокода для описания подсказки будет более понятным и точным.
Когда мы пишем Prompt, мы помним, что Prompt - это, по сути, управляющая инструкция для LLM, описанная на естественном языке, которая позволяет LLM понять, что мы хотим, и затем превратить входные данные в ожидаемые выходные данные, как это требуется. Что касается формы описания Prompt, то она может быть гибкой и представлять собой множество форм, таких как few-shot, CoT, псевдокод и т. д.
Другие примеры:
Генерируйте мета-подсказки "псевдокода" для точного контроля форматирования вывода
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...