
Pix2Text: бесплатный инструмент для распознавания текста на изображениях с открытым исходным кодом

Pix2Text Общее представление
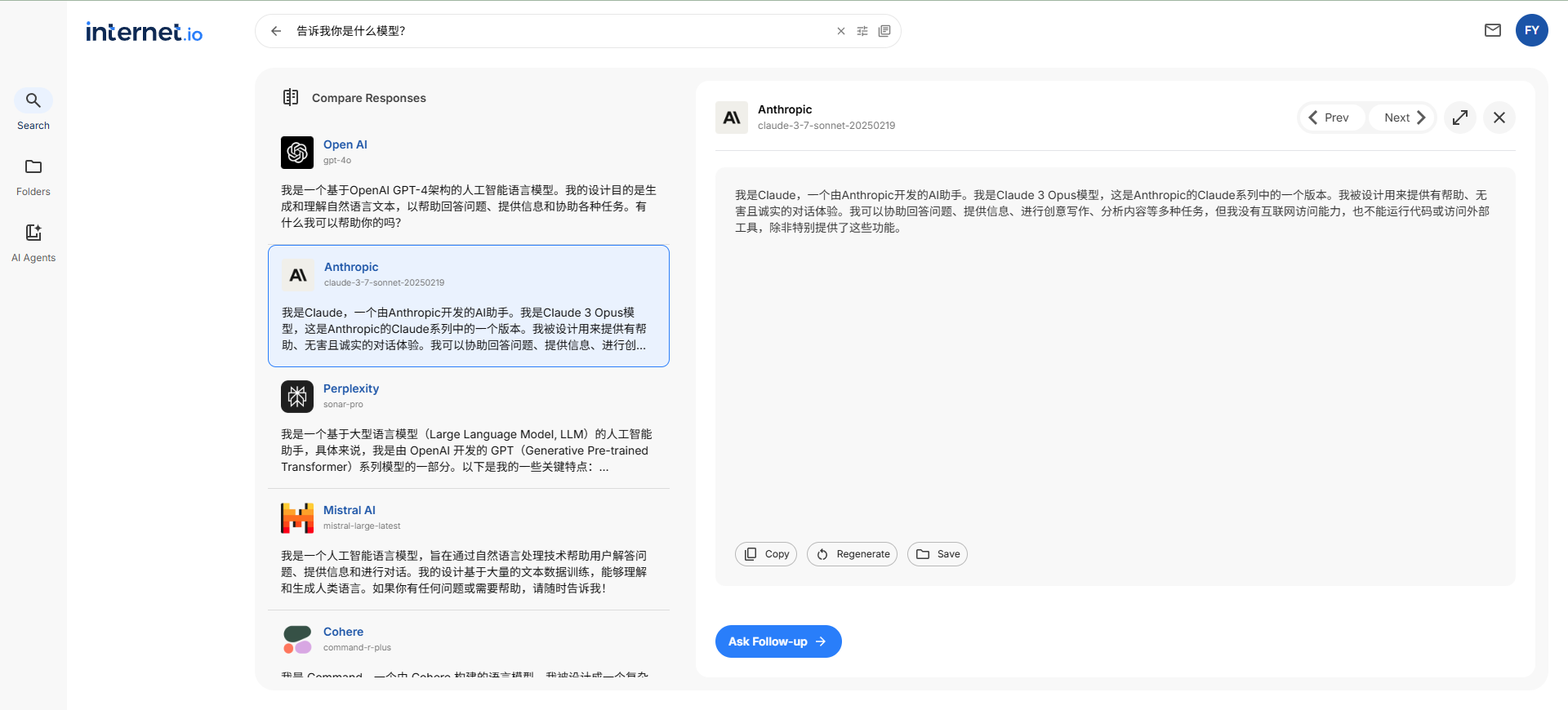
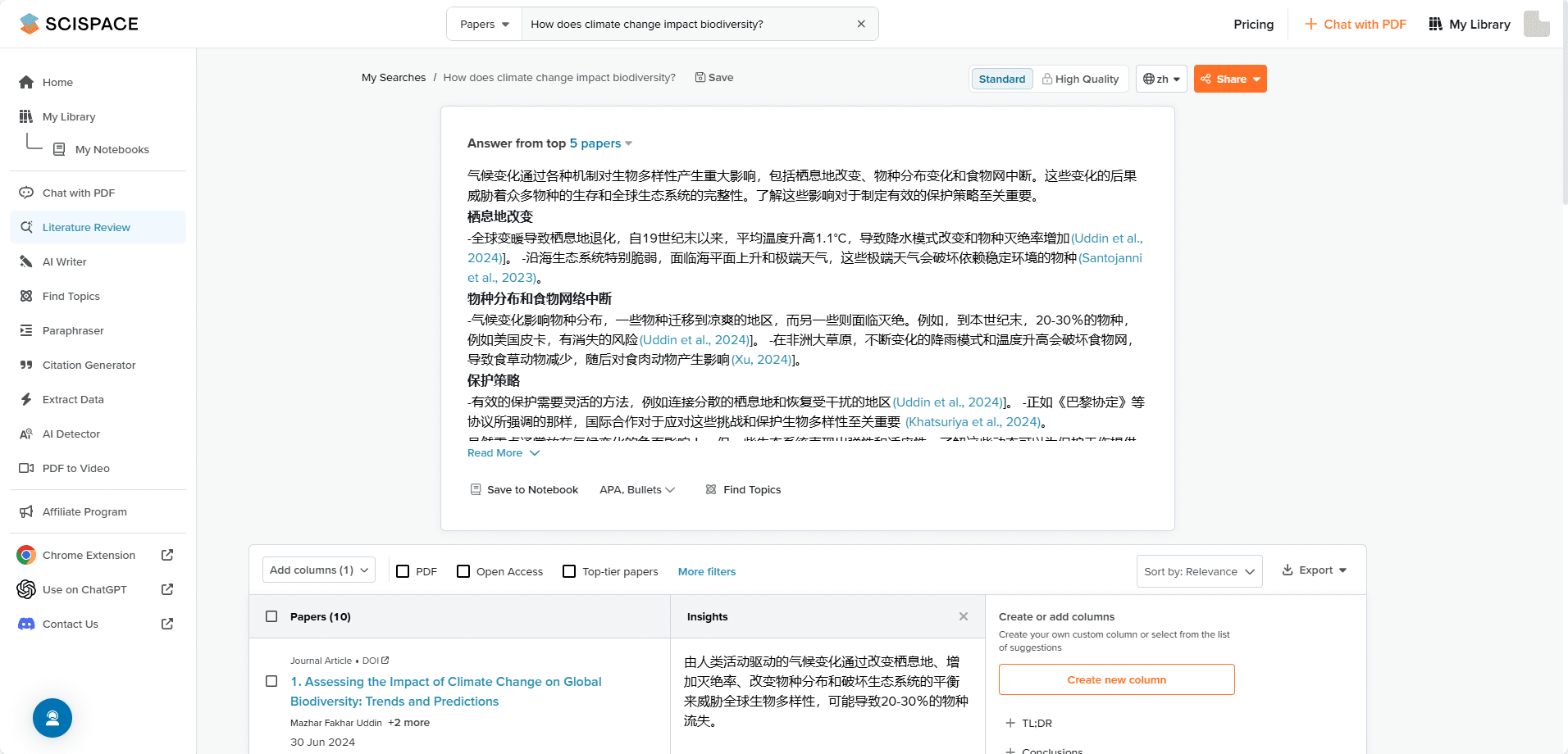
Pix2Text (P2T) - это бесплатный инструмент с открытым исходным кодом, призванный заменить Mathpix, обеспечивающий распознавание текста и математических формул с изображений. Пользователи могут использовать инструмент бесплатно через веб-версию, распознавая до 10 000 символов в день. P2T поддерживает распознавание и преобразование текста, таблиц, математических формул и т. д. из изображений в формат LaTeX или Markdown для удобства редактирования и использования.

Список функций Pix2Text
- Распознавание текста на изображениях: распознавание китайского и английского текста на изображениях и преобразование его в редактируемый текст.
- Распознавание математических формул: распознавание математических формул на изображениях и преобразование их в формат LaTeX.
- Распознавание таблиц: распознавание таблиц на изображениях и преобразование их в формат Markdown.
- Конвертация PDF: преобразование содержимого PDF-файла в формат Markdown.
- Бесплатное использование: до 10 000 символов в день.
Помощь Pix2Text
Установка и использование
Pix2Text доступен в веб-версии, которая не требует от пользователя установки какого-либо программного обеспечения. Просто зайдите на сайт Веб-сайт Pix2Text и загрузите изображение или PDF-файл, который необходимо распознать, и вы сможете получить результат распознавания.
Функции Поток операций
- Доступ к веб-сайту: Откройте браузер и посетите Веб-сайт Pix2Text.
- Загрузка файлов: Нажмите на кнопку "Загрузить файл" на странице и выберите изображение или PDF-файл для распознавания.
- Выбор типа идентификации: Выберите для распознавания текста, математических формул или таблиц.
- Посмотреть результаты: Нажмите на кнопку "Начать распознавание" и подождите несколько секунд, пока не появится результат распознавания.
- Результаты загрузки: Результаты распознавания можно скопировать или загрузить в виде файла LaTeX или Markdown.
Подробные функции
- Распознавание текста по изображению: Поддержка распознавания китайского и английского текста для различных документов, книг, рукописных заметок и других изображений.
- Распознавание математических формулПередовая модель обнаружения и распознавания математических формул позволяет точно идентифицировать математические формулы на изображениях и преобразовывать их в представления LaTeX, что удобно для академических исследований и написания диссертаций.
- Распознавание форм: Распознает структуры таблиц на изображениях и преобразует их в формат Markdown для удобства использования в документах.
- Преобразование PDFКонвертируйте PDF-файлы в формат Markdown для пользователей, которым необходимо редактировать и организовывать содержимое PDF-файлов.
- Бесплатное использованиеPix2Text бесплатен в использовании и распознает до 10 000 символов в день, что делает его подходящим для отдельных пользователей и небольших команд.
Советы и рекомендации
- Высококачественные изображения: Загрузка четких изображений может повысить точность распознавания.
- идентификация сегментов: Для длинных документов можно загружать изображения для распознавания по сегментам, чтобы обеспечить точное распознавание каждого сегмента.
- Результаты проверки: Результаты распознавания могут содержать небольшое количество ошибок, поэтому пользователям рекомендуется проверять и вычитывать их перед использованием.
Развертывание проекта Pix2Text
монтаж
- Адрес с открытым исходным кодом:https://github.com/breezedeus/Pix2Text
- Подготовка среды Python: Убедитесь, что установлен Python 3.6 и выше.
- Установите Pix2Text::
pip install pix2textЕсли вам нужно распознать текст на нескольких языках, используйте следующую команду для установки дополнительных пакетов:
pip install pix2text[multilingual]Если установка идет медленно, можно указать внутренний источник установки, например, использовать источник установки AliCloud:
pip install pix2text -i https://mirrors.aliyun.com/pypi/simple
пользоваться
- инструмент командной строки::
- Распознавать текст на картинках:
pix2text image.jpg - Распознавание файлов PDF:
pix2text document.pdf
- Распознавать текст на картинках:
- HTTP-сервис::
- Запустите службу HTTP:
pix2text serve - Распознавание изображений с помощью HTTP-запросов:
curl -F "file=@image.jpg" http://localhost:5000/ocr
- Запустите службу HTTP:
- Использование веб-версии::
- Посетите онлайн-версию сайта Pix2Text и перетащите изображение в указанную область, чтобы получить результат распознавания.
типичный пример
- Распознавание текста по изображению: Входное изображение: !пример Выходной текст:
这是一个示例文本。 - Распознавание математических формул: Входной рисунок: !пример Выходная формула:
$$E=mc^2$$ - Распознавание форм: Входное изображение: !пример Выходная таблица:
| Header1 | Header2 | |---------|---------| | Data1 | Data2 |
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...