Оценка креативности больших языковых моделей: за пределами парадигмы множественного выбора LoTbench

В большой языковой модели ( LLM ) область исследований, моделирование Leap-of-Thought Способность, или креативность, так же важна, как и способность Chain-of-Thought для представленных навыков логического мышления. Однако в настоящее время наблюдается значительное увеличение числа студентов, нацеленных на LLM Глубокие дискуссии о творчестве и эффективных методах оценки все еще относительно малочисленны, что в определенной степени сдерживает LLM Потенциал развития в творческих приложениях.
Основная причина этого заключается в том, что крайне сложно построить объективный, автоматизированный и надежный процесс оценки абстрактного понятия "креативность".
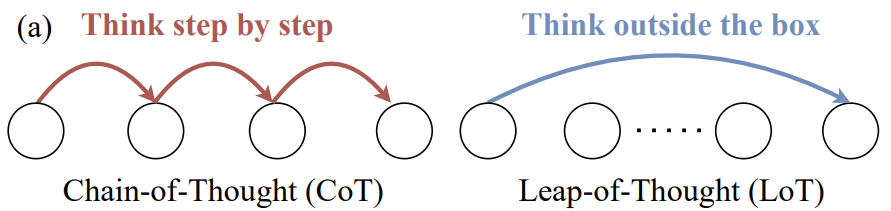
В прошлом многие ответы на LLM В попытках измерить креативность, как показано на рисунке 1, по-прежнему используются вопросы с несколькими вариантами ответов и последовательностью, которые обычно применяются для оценки навыков логического мышления. Эти методы хороши для проверки того, может ли модель определить заранее заданный "лучший" или "наиболее логичный" вариант, но они не очень хороши для оценки истинной креативности - способности генерировать новый и уникальный контент. Но они не так хороши для оценки истинной креативности - способности генерировать новый и уникальный контент.
Например, рассмотрим задание на рисунке 2: На основе картинки и имеющегося текста заполните "? Содержание должно быть креативным и юмористическим.
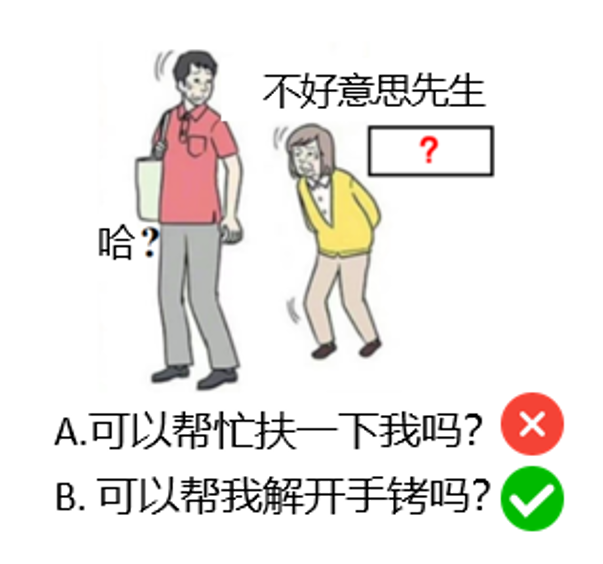
Если это вопрос с несколькими вариантами ответа, укажите варианты "А. Можете ли вы мне помочь?" и "Б. Можете ли вы помочь мне освободиться от наручников?" и "Б. Можете ли вы снять с меня наручники?" и "Б. Можете ли вы помочь мне освободиться от наручников? LLM Скорее всего, будет выбран вариант B, но не потому, что он демонстрирует креативность, а просто потому, что вариант B более "особенный" или "необычный", чем вариант A, и модель способна сделать выбор скорее благодаря распознаванию образов, чем творческому мышлению.
оценка LLM творческих способностей, следует изучить ядро на предмет егосозданиеСпособность к инновационному содержанию, а несудьяСпособность содержания быть инновационным или нет. Традиционные методы оценки, такие как множественный выбор, в большей степени ориентированы на последний показатель и поэтому имеют свои ограничения. В настоящее время основными методами, позволяющими напрямую оценить генеративный потенциал, являются ручная оценка и LLM-as-a-judge (Использовать LLM (в качестве обзора). Ручные оценки, хотя и являются точными и соответствуют человеческим ценностям, дорогостоящи и трудно масштабируемы. В то время как LLM-as-a-judge Эффективность метода при выполнении заданий на оценку креативности еще не сформировалась, и стабильность результатов нуждается в улучшении.
Перед лицом этих проблем исследователи из Университета Сунь Ятсена, Гарвардского университета, Лаборатории Пэнчэн и Сингапурского университета менеджмента предложили новый способ мышления. Вместо того чтобы напрямую оценивать "добротность" генерируемого контента, они изучают его "добротность", изучая LLM "Стоимость" создания ответа, сопоставимого с содержанием высококачественных человеческих инноваций(что можно интерпретировать как требуемые усилия или стоимость взаимодействия), построили систему под названием LoTbench многораундовой интерактивной автоматизированной парадигмы оценки креативности. Цель метода - обеспечить более достоверную и масштабируемую меру креативности. Результаты соответствующих исследований были опубликованы в IEEE TPAMI Журнал.

- Название диссертации: Парадигма оценки креативности мультимодальных моделей большого языка с учетом причинно-следственных связей
- Ссылка на статью: https://arxiv.org/abs/2501.15147
- Домашняя страница проекта: https://lotbench.github.io
Сценарий миссии: Японская холодная коса
LoTbench Исследование основано на CVPR'24 Продолжение работы, представленной на конференции Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. Generation). Исследователи выбрали форму задания, заимствованную из традиционной японской игры Oogiri, которая в китайском Интернете известна как "японский холодный троллинг", как показано на рисунке 2.
Этот тип заданий требует от участников смотреть на картинки и дополнять текст таким образом, чтобы сочетание картинок и текста создавало инновационный и юмористический эффект. Это задание было выбрано в качестве основы для оценки, исходя из следующих соображений:
- Высокие требования к креативности: Задание представляло собой прямой запрос на создание креативного юмористического контента - типичный вызов креативности.
- Подгонка мультимодальной модели: Ввод графический, вывод текстовый, полностью совместимый с современными мультимодальными
LLMСфера компетенции - Богатые ресурсы данных: Популярность "японского холодного троллинга" в интернет-сообществе позволила накопить большое количество высококачественных примеров человеческих творений и данных с оценочной информацией, что облегчает создание оценочных наборов данных.
Таким образом, "японский холодный плевок" представляет собой полезный инструмент для оценки мультимодальных LLM творчества обеспечивает идеальную и уникальную платформу.
Методология оценки LoTbench

В отличие от традиционных парадигм оценки (например, отбор, ранжирование) LoTbench Основная идея заключается в следующем:Измерение LLM Сколько раундов взаимодействия требуется для создания высококачественного инновационного ответа человека на заданную ( HHCR Ответ: "То же самое". Это требуемое "количество раундов" отражает LLM "Расстояние" или "стоимость" достижения определенной творческой цели.
Как показано в правой части рисунка 3, для данного HHCR (математика) род LoTbench Не является обязательным условием LLM Повторите его в точности, а лучше посмотрите на LLM Можно ли в ходе нескольких попыток сгенерировать идею, которая, хотя и выражена по-разному, имеет сходное творческое ядро и эффект (т.е. DAESO - Разный подход, но одинаково удовлетворительный результат).
LoTbench Конкретный ход процесса показан на рисунке 4:
- Задача Строительство: Выбрано из данных "Японские холодные твиты".
HHCRОбразец. Для каждого раунда требуется, чтобы образец для тестированияLLMСформируйте ответ на основе графической информацииRtчтобы заполнить пробелы в тексте. - Решение DAESO: Судить о сгенерированном
RtСоответствие целиHHCR(Обозначается какR) достигDAESO. Если да, запишите текущее количество раундов для последующих подсчетов очков; если нет, перейдите к шагу 3. - Интерактивные вопросы: Если нет
DAESOЕсли испытание должно проводиться на одном и том же судне, необходимо, чтобыLLMОбщий вопрос, основанный на текущей истории взаимодействияQt(например, попросить подсказки о целевом творческом направлении). - Обратная связь с системой: Система оценки основана на
HHCRВнутренняя логикаLLMПоднятые вопросыQtОтветьте "Да" или "Нет". - Интеграция информации и итерация: Поместите всю информацию о взаимодействии для этого раунда (включая
LLMгенерация, постановка вопросов и обратная связь от системы) и интеграция подсказок, предоставленных системой, для формирования следующего раундаhistory promptЕсли вы не уверены, вернитесь к шагу 1 и начните новый цикл попыток.
Этот процесс продолжается до тех пор, пока LLM созданный DAESO ответ, или был достигнут установленный максимальный лимит раундов.
Итоговый балл за креативность Sc на основе обзора n классификатор для отдельных вещей или людей, общий, всеобъемлющий классификатор HHCR Проба, проведение m Результаты были рассчитаны на основе результатов нескольких повторений эксперимента. Расчеты выглядят примерно следующим образом (в формулах HTML):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Среди них.k_ij это модель в первом j Второе повторение эксперимента для первого i классификатор для отдельных вещей или людей, общий, всеобъемлющий классификатор HHCR образцы, успешно генерируя DAESO Количество раундов, используемых для ответа.
Этот показатель креативности Sc Со следующими характеристиками:
- Обратные отношения: Оценка и количество необходимых раундов
kОбратно пропорционально. Чем меньше количество раундов, темLLMЧем быстрее вы достигнете целевого уровня креативности, тем выше ваш балл и тем более креативным вы являетесь. - Нижний предел нулевых точек: в случае, если
LLMПостоянные сбои в генерации в пределах максимального количества раундовDAESO(эквивалентно числу раундов, стремящемуся к бесконечности), его оценка по этой выборке стремится к 0, что свидетельствует о недостаточной креативности при выполнении этого задания. - Надежность: Это достигается за счет использования нескольких
HHCRОбразцы усреднялись по нескольким повторениям эксперимента, и при подсчете баллов учитывались разнообразие и сложность идей, что уменьшало эффект рандомизации одного эксперимента.
Как определить "сходства и различия" ( DAESO )?
DAESO Определение LoTbench Одна из главных трудностей методологии.
Зачем он вам нужен DAESO Суждение? Одна из ключевых особенностей заданий на креативность - их открытость и разнообразие. Люди могут придумать множество разных, но одинаково креативных и юмористических ответов на один и тот же сценарий "японский холодный тролль". Как показано на рис. 5, "вибрирующий будильник" и "вибрирующий мобильный телефон" основаны на основной идее "объект бьется и издает звук благодаря своей вибрации", и достигают схожих юмористических эффектов. Юмористический эффект схож.
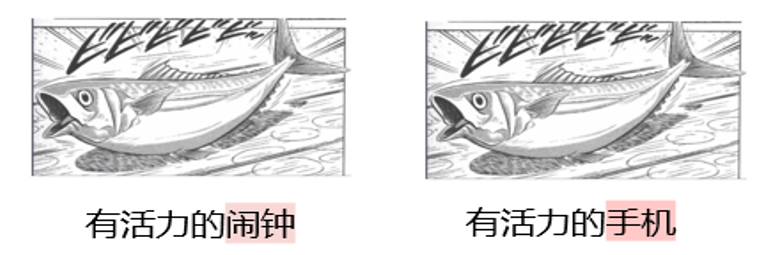
Такое глубокое творческое сходство невозможно точно уловить с помощью простого сопоставления поверхностей текста или обычных расчетов семантического сходства. Например, хотя "энергичная блоха" также содержит слово "энергичный", в ней отсутствует функциональная ассоциация "звукового напоминания", подразумеваемая "будильником" или "мобильным телефоном". Функциональная ассоциация "звуковое напоминание", подразумеваемая "будильником" или "мобильным телефоном", отсутствует. Поэтому важно ввести механизм определения "сходств и различий".
Как реализовать DAESO Суждение?
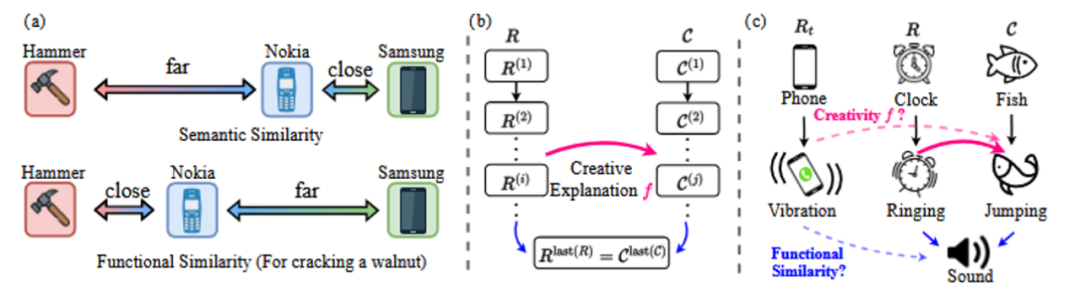
В статье исследователь предлагает два варианта ответа, которые должны удовлетворить DAESO Для этого необходимо, чтобы одновременно выполнялись два условия:
- Все те же основные инновации: Творческая логика или юмор, лежащие в основе обоих ответов, по сути, одинаковы.
- Функциональное сходство: Эти два ответа схожи в том, что касается "функции" или "роли сцены", которая провоцирует юмор.
Функциональное сходство отличается от чистого семантического сходства. Как показывает пример на рис. 6(a), в конкретном функциональном сценарии "разбивание грецких орехов" функциональное сходство между "мобильным телефоном Nokia" и "молотком" может быть выше, чем семантическое сходство между "мобильным телефоном Samsung" и "мобильным телефоном Samsung". Семантическое сходство между "мобильным телефоном Nokia" и "молотком" может быть выше, чем между "мобильным телефоном Samsung" и "мобильным телефоном Samsung".
Только совпадение интерпретации основной инновации может привести к ответу, отклоняющемуся от темы (например, "энергичная блоха" на рис. 5, которой не хватает функции "голосового напоминания"); только совпадение функционального сходства может не передать суть идеи (например, "энергичный барабан" на рис. 5, который также является голосовым объектом, но ему не хватает ощущения ударов из-за его собственной "вибрации"). Энергичный барабан" в примере на рис. 5 также является звуковым объектом, но ему не хватает ощущения ударов из-за его собственной "энергичности").
в конкретном выражении DAESO При реализации суждения исследователь сначала предоставляет новый набор критериев для каждого HHCR Образцы были промаркированы с подробным объяснением источника их юмора и креативности. Затем информация о названии (подписи) изображения была объединена и использована с LLM себя, в текстовом пространстве, за возможность HHCR Постройте причинно-следственную цепочку (как показано на рис. 6(c)), чтобы разобрать ее творческую композицию. И наконец, разработайте конкретные указания (инструкцию) для другого LLM (например. GPT-4o mini ) На основе этой информации измеряемый ответ оценивается в текстовом пространстве Rt сотрудничество с компанией Targets. HHCR Неважно, оба ли из вышеперечисленных вариантов DAESO Условия.
Исследования показали, что использование GPT-4o mini идти вперёд DAESO Суждение, что точность 80%-90% может быть достигнута при меньших вычислительных затратах. Учитывая LoTbench Будет проведено несколько повторов эксперимента, с одним DAESO Влияние небольших ошибок в суждениях на итоговый средний балл еще больше снижается, что обеспечивает надежность общей оценки.
Результаты оценки
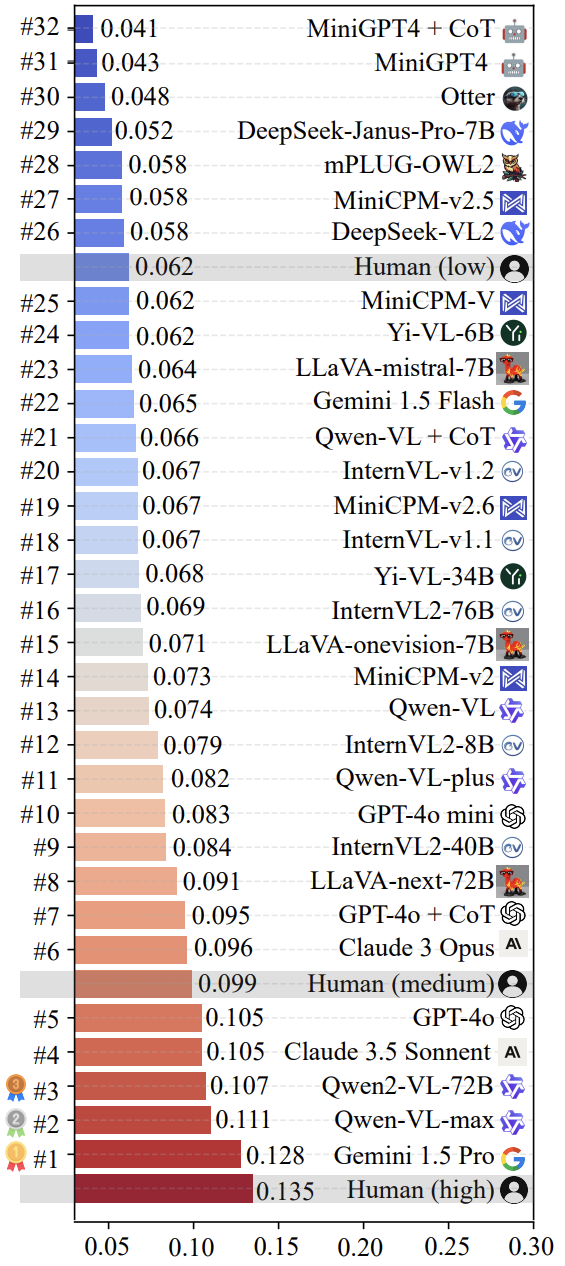
Исследовательская группа использовала LoTbench Обзор некоторых современных мультимодальных LLM Была проведена оценка. Как показано на рис. 7, результаты показывают, что на основе LoTbench Стандартная мера существующих LLM креативности обычно не считается сильным, по сравнению с высоким качеством творческой реакции человека ( HHCR ) все еще не дотягивают до этого уровня. Однако по сравнению с общечеловеческим уровнем (не обозначенным на рисунке, но предполагаемым) или первичным человеческим уровнем, некоторые из лучших LLM (например. Gemini 1.5 Pro ответить пением Qwen-VL-max ) продемонстрировал некоторую конкурентоспособность, а также намекнул на LLM Обладает потенциалом, способным превзойти человечество в плане творчества.
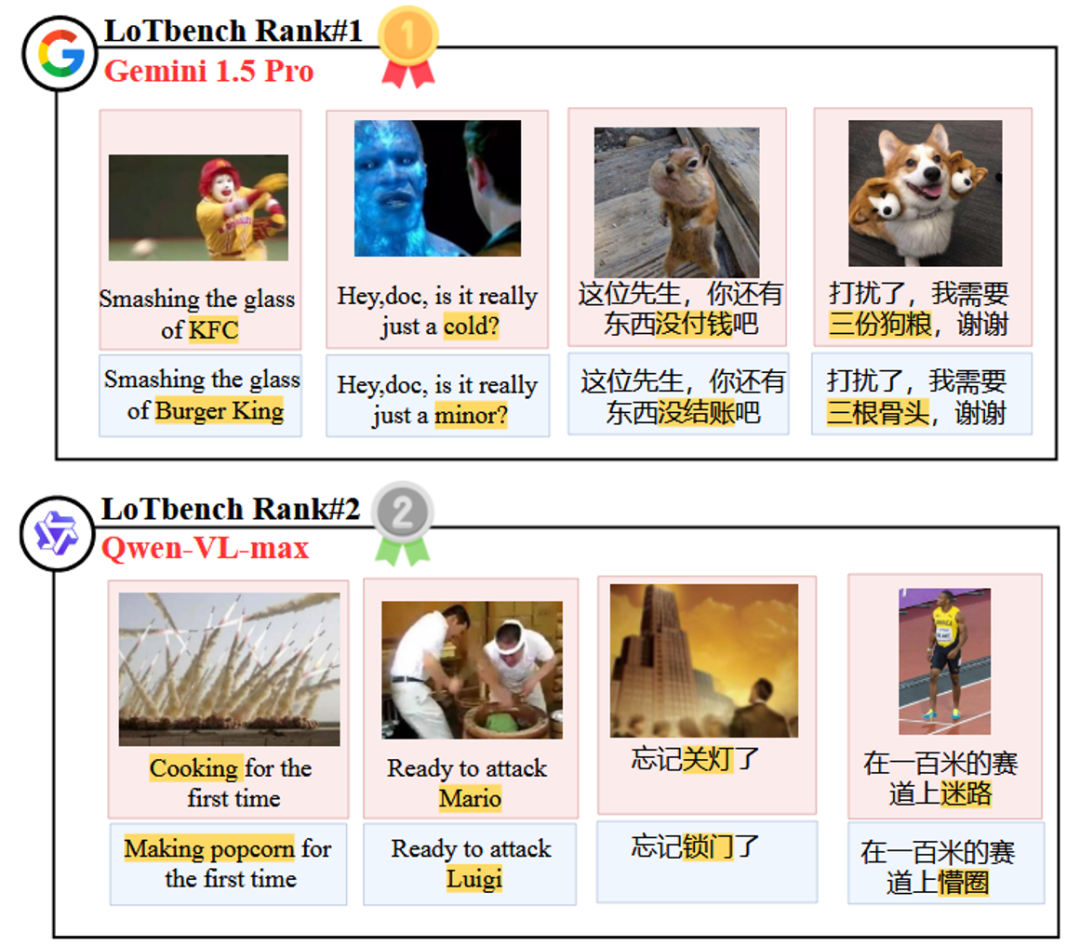
На рисунке 8 показаны два первых места в списке Gemini 1.5 Pro ответить пением Qwen-VL-max специфический для модели компонент HHCR (выделено красным) генерируется DAESO Ответ (выделено синим цветом).
Стоит отметить, что недавний широко разрекламированный DeepSeek-VL2 ответить пением Janus-Pro-7B Также оценивались серийные модели. Результаты показали, что их креативность в LoTbench примерно на уровне человеческих первичек. Это позволяет предположить, что при совершенствовании мультимодальных LLM Остается еще много возможностей для изучения глубокого творческого потенциала
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...