PengChengStarling: более компактный и быстрый многоязычный инструмент для преобразования речи в текст, чем Whisper-Large v3

Общее введение
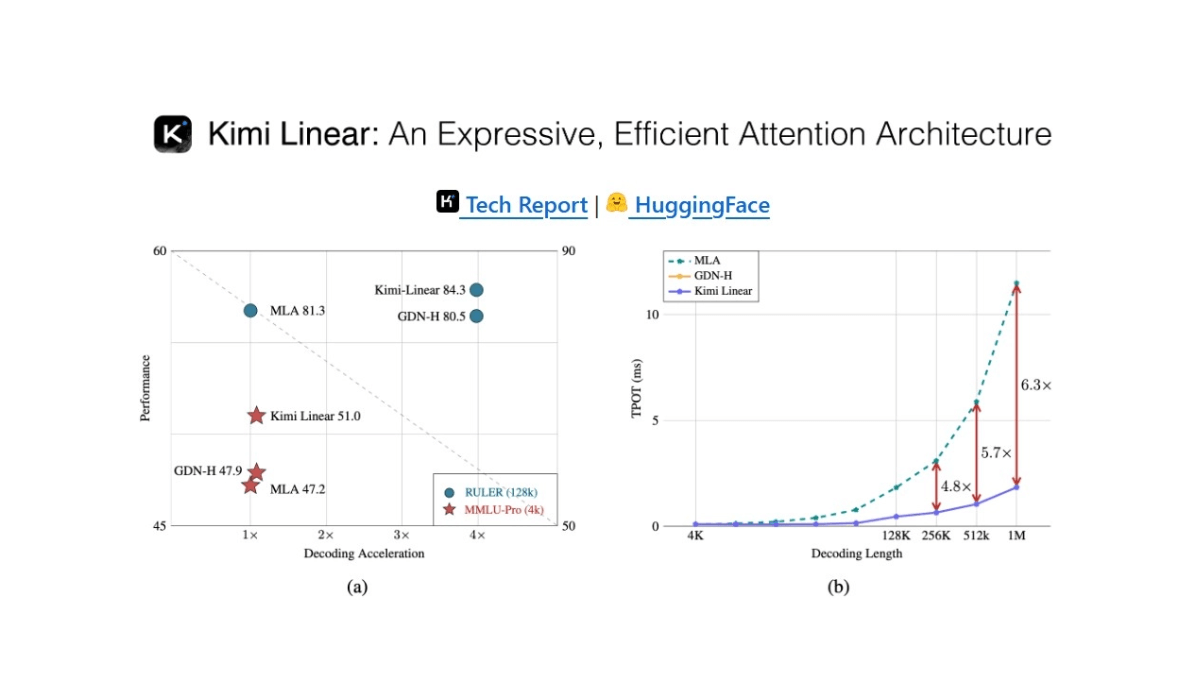
PengChengStarling (PengCheng Labs) - это многоязычный инструмент автоматического распознавания речи (ASR), способный преобразовывать речь на разных языках в соответствующий текст. Этот инструментарий разработан на основе проекта icefall и обеспечивает полный процесс распознавания речи, включая обработку данных, обучение модели, вывод, тонкую настройку и развертывание. pengChengStarling поддерживает потоковое распознавание речи на восьми языках, включая китайский, английский, русский, вьетнамский, японский, тайский, индонезийский и арабский. Основные сценарии его применения включают голосовые помощники, средства перевода, генерацию субтитров и голосовой поиск. Размер модели составляет 20% от Whisper-Large v3, а скорость распознавания в 7 раз выше, чем у Whisper-Large v3.
Его особенности заключаются в том, что он может обрабатывать многоязычный речевой ввод в единой структуре, поддерживать распознавание речи в реальном времени, распознавание во время разговора, может использоваться как запись международной конференции в текст, многоязычное видео автоматически генерирует субтитры, кросс-язычная система обслуживания клиентов.

Список функций
- Обработка данных: поддерживает предварительную обработку нескольких наборов данных для создания требуемого формата входных данных.
- Обучение модели: обеспечивает гибкие конфигурации обучения для поддержки многоязычных задач распознавания речи.
- Вывод: эффективная скорость вывода с поддержкой потокового распознавания речи.
- Тонкая настройка: поддерживает тонкую настройку моделей в соответствии с требованиями конкретных задач.
- Развертывание: предоставляет модели в форматах PyTorch и ONNX для легкого развертывания.
Использование помощи
Процесс установки
- Хранилище проектов клонирования:
git clone https://github.com/yangb05/PengChengStarling
cd PengChengStarling
- Установите зависимость:
pip install -r requirements.txt
export PYTHONPATH=/tmp/PengChengStarling:$PYTHONPATH
Подготовка данных
Прежде чем начать процесс обучения, исходные данные необходимо предварительно обработать и преобразовать в нужный формат. Как правило, для этого необходимо адаптироватьzipformer/prepare.pyпопал в точкуmake_*_listметод для созданияdata.listФайл. После завершения сценарий сгенерирует соответствующие разрезы и fbank-функции для каждого набора данных, которые будут использованы в качестве входных данных для PengChengStarling.
обучение модели
- Настройте параметры обучения: в
config_trainкаталог для настройки параметров, необходимых для обучения. - Начните обучение:
./train.sh
вывод
- Подготовка данных для выводов: предварительная обработка данных в нужном формате.
- Начните рассуждать:
./eval.sh
тонкая настройка
- Подготовка данных для тонкой настройки: предварительная обработка данных в нужный формат.
- Приступайте к тонкой настройке:
./train.sh --finetune
развертывания
PengChengStarling предоставляет модели в двух форматах: словарь состояний PyTorch и формат ONNX. Вы можете выбрать подходящий формат для развертывания в зависимости от ваших потребностей.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...