
Релиз OpenAI: приложения и лучшие практики для моделей вывода ИИ

В области искусственного интеллекта выбор модели имеет решающее значение. openAI, лидер отрасли, предлагает семейство моделей двух основных типов:модель вывода (Модели рассуждений) и Модель GPT (GPT Models). Первая серия представлена моделями серии o, такими как o1 ответить пением o3-miniПоследняя известна своими моделями семейства GPT, такими как GPT-4o. Понимание различий между этими двумя типами моделей и сценариев применения, в которых они превосходят друг друга, имеет решающее значение для полного использования потенциала ИИ.
В этой статье мы подробно рассмотрим этот вопрос:
- Ключевые различия между моделями вывода OpenAI и моделями GPT.
- Когда приоритетнее использовать модели выводов OpenAI.
- Как эффективно управлять моделями вывода для достижения оптимальной производительности.
На днях инженеры Microsoft выпустили Разработка подсказок для моделей вывода OpenAI O1 и O3-mini В результате можно сравнить различия в применении этих двух устройств.
Модели вывода против моделей GPT: стратеги против исполнителей
Модели умозаключений OpenAI серии o, в отличие от привычных моделей GPT, демонстрируют свои сильные стороны в разных типах задач и требуют разных стратегий подсказки. Важно понимать, что эти два типа моделей не просто лучше или хуже, а имеют разную направленность возможностей. Это отражает постоянные усилия OpenAI по расширению границ возможностей своих моделей для удовлетворения потребностей все более сложных приложений, требующих глубоких рассуждений.
OpenAI специально обучила модели серии o, получившие внутреннее кодовое название Planners, мыслить дольше и глубже, что позволило им преуспеть в таких областях, как разработка стратегии, планирование сложных задач и принятие решений на основе большого количества неоднозначной информации. Способность этих моделей выполнять задачи с высокой степенью точности и аккуратности делает их идеальными для областей, в которых традиционно используются человеческие эксперты, таких как специализированные области математики, науки, инженерии, финансовые и юридические услуги.
С другой стороны, GPT-модели OpenAI (внутреннее кодовое название "Workhorses") являются более низкозамедленными и экономичными и предназначены для непосредственного выполнения задач. На практике часто используется комбинация этих двух типов моделей: с помощью моделей o-серии формулируется макростратегия решения проблемы, а затем эффективно выполняются конкретные подзадачи с помощью моделей GPT, особенно в сценариях, где скорость и экономичность более важны, чем абсолютная точность. Такое разделение труда отражает зрелость философии разработки моделей ИИ, которая отделяет планирование от исполнения.
Как выбрать подходящую модель? Понимание ваших потребностей
При выборе модели главное - определить основные требования вашего сценария применения:
- Скорость и стоимость. Если вашими приоритетами являются скорость и экономичность, то модель GPT обычно является более быстрым и экономичным выбором.
- Четко сформулированные задачи. Для приложений с ясными целями и четко определенными границами задач модель GPT способна преуспеть в выполнении заданий.
- Точность и надежность. Если ваша задача требует высочайшего уровня точности и надежности результатов, то модели серии o - это более надежные решения.
- Решение сложных задач. В условиях высокой неоднозначности и сложности модели серии o способны эффективно справляться с этой задачей.
Итак, если для вас важны скорость и стоимость, а в качестве сценариев использования используются в основном простые, четко определенные задачи, то модели OpenAI GPT - идеальный вариант. Однако если для вас важны точность и надежность, и вы решаете сложные, многоэтапные задачи, то модели OpenAI серии o могут лучше соответствовать вашим потребностям.
Во многих реальных рабочих процессах ИИ лучше всего использовать комбинацию этих двух моделей: модели семейства o выступают в роли "планировщика", отвечающего за планирование и принятие решений агентом, а модели семейства GPT - в роли "исполнителя", отвечающего за выполнение конкретных задач. Такая стратегия сочетания позволяет в полной мере использовать сильные стороны обоих типов моделей.

Например, модели GPT-4o и GPT-4o mini от OpenAI можно использовать в сценариях обслуживания клиентов, где информация о клиенте сначала используется для классификации деталей заказа, выявления проблем с заказом и политики возврата, а затем эти данные поступают в модель o3-mini, которая принимает окончательное решение о целесообразности возврата на основе заданных политик.
Сценарии применения моделей вывода: превосходство в сложности и неоднозначности
В результате сотрудничества с клиентами и внутренних наблюдений компания OpenAI разработала несколько типичных примеров успешного применения своих моделей вывода. Перечисленные ниже сценарии применения не являются исчерпывающими, а скорее представляют собой практические руководства, призванные помочь вам лучше оценить и протестировать модели OpenAI серии o.
1. навигация по неоднозначным задачам: понимание намерений на основе фрагментарной информации
Модели умозаключений особенно хороши при решении задач с неполной или разрозненной информацией. Даже при наличии ограниченной информации модели умозаключений могут эффективно понять истинные намерения пользователя и правильно обработать двусмысленность инструкций. Стоит отметить, что модели умозаключений обычно не спешат делать неразумные догадки или пытаться самостоятельно заполнить информационные пробелы, а проактивно задают уточняющие вопросы, чтобы убедиться, что требования задачи точно поняты. Это хороший пример преимуществ моделей умозаключений при работе с неопределенностью и сложными задачами.
Hebbia, платформа знаний ИИ для юридического и финансового секторов, говорит: "Превосходные возможности o1 в области умозаключений позволяют Matrix, мультиагентной платформе OpenAI, эффективно обрабатывать сложные документы и генерировать подробные, хорошо структурированные и информативные ответы. Например, o1 позволяет Matrix с помощью простых подсказок определить сумму денег, доступную по кредитному договору с ограниченной платежеспособностью. Ни одна другая модель ранее не достигала такого уровня производительности. В интенсивных комплексных тестах 52% на определение кредитного договора o1 показала более значительные результаты по сравнению с другими моделями".
-Hebbia, компания, разрабатывающая платформу знаний на основе искусственного интеллекта для юридического и финансового секторов.
2. поиск информации: найти иголку в стоге сена, точно определить местоположение
При столкновении с огромными объемами неструктурированной информации модель вывода демонстрирует сильное понимание информации и способна точно извлекать наиболее релевантную вопросу информацию, тем самым эффективно отвечая на вопрос пользователя. Это подчеркивает превосходную производительность моделей умозаключений в информационном поиске и фильтрации ключевой информации, особенно при работе с большими массивами данных.
Endex, платформа финансовой аналитики с искусственным интеллектом, рассказывает: "Для глубокого анализа сделок по приобретению компаний модель o1 использовалась для анализа десятков документов компании, включая контракты и договоры аренды, с целью найти потенциальные положения, которые могут негативно повлиять на сделку. Перед моделью была поставлена задача отметить ключевые положения. В ходе работы o1 обнаружила в сноске ключевой пункт о "смене контроля": пункт, который предусматривал немедленное погашение кредита в размере 75 миллионов долларов в случае продажи компании. Высокая внимательность o1 к деталям позволяет ИИ-агентам OpenAI эффективно поддерживать работу финансовых специалистов, точно определяя критически важную информацию".
-Endex, платформа финансовой разведки с искусственным интеллектом
3. обнаружение взаимосвязей и выявление нюансов: углубление в ценность данных
OpenAI обнаружил, что модели умозаключений особенно хороши при анализе плотных, неструктурированных документов длиной в сотни страниц, таких как юридические контракты, финансовые отчеты и страховые заявления. Эти модели эффективно извлекают информацию из сложных документов, устанавливают связи между различными документами и принимают умозаключительные решения на основе фактов, скрытых в данных. Это показывает, что модели умозаключений имеют значительные преимущества при обработке сложных документов и добыче глубокой информации.
Blue J, платформа искусственного интеллекта для налоговых исследований, отмечает: "Налоговые исследования часто требуют интеграции информации из множества документов для формирования окончательного, убедительного вывода. Заменив модель GPT-4o на модель o1, OpenAI обнаружил, что o1 лучше справляется с рассуждениями о взаимодействии между документами и способен делать логические выводы, которые не очевидны ни в одном отдельном документе. В результате, перейдя на модель o1, OpenAI получила впечатляющее 4-кратное улучшение сквозной производительности".
-Блю Джей, платформа ИИ для налоговых исследований
Модели рассуждений одинаково хорошо разбираются в тонкостях политики и правил и применяют их к конкретным задачам, чтобы прийти к обоснованным выводам.
BlueFlame AI, платформа искусственного интеллекта для управления инвестициями, приводит пример: "В области финансовой аналитики аналитикам часто приходится иметь дело со сложными ситуациями, связанными с правами акционеров, и им необходимо глубоко разбираться в соответствующих юридических сложностях. OpenAI протестировал около 10 моделей от разных производителей, используя сложный, но распространенный вопрос: как поведение финансистов повлияет на существующих акционеров, особенно когда они воспользуются своей привилегией против разводнения? Этот вопрос требует рассуждений об оценке стоимости компании до и после финансирования и учета сложностей циклического разводнения - вопрос, на решение которого даже у ведущих финансовых аналитиков уйдет 20-30 минут. OpenAI обнаружил, что модели o1 и o3-mini прекрасно решают эту задачу! Модели даже сгенерировали четкую вычислительную таблицу, детально показывающую влияние поведения при финансировании на $100 000 акционеров".
-BlueFlame AI, платформа искусственного интеллекта для управления инвестициями
4. многоступенчатое планирование деятельности агентства: стратегический план операций, стратегия успеха
Модели умозаключений играют важнейшую роль в планировании и разработке стратегий агентов. В OpenAI заметили, что модели умозаключений, когда они позиционируются как "планировщики", способны генерировать детальные, многоэтапные решения сложных задач. Впоследствии система может выбрать и назначить наиболее подходящую модель GPT ("исполнитель") для выполнения каждого шага, основываясь на различных требованиях к задержке и интеллекту. Это еще раз демонстрирует преимущества использования комбинации моделей, где модель умозаключений выступает в качестве "мозга" для планирования стратегии, а модель GPT - в качестве "рук и ног" для выполнения.
Argon AI, платформа знаний ИИ для фармацевтической промышленности, сообщает: "OpenAI использует модель o1 в качестве планировщика в своей агентской инфраструктуре, что позволяет ей управлять другими моделями в рабочем процессе для эффективного выполнения многоэтапных задач. OpenAI обнаружил, что модель o1 очень хороша в выборе правильного типа данных и разбиении больших, сложных проблем на более мелкие, управляемые модули, чтобы другие модели могли сосредоточиться на конкретных решениях".
-Аргон ИИ, платформа знаний ИИ для фармацевтической промышленности
Lindy.AI, рабочий ИИ-ассистент, поделился: "Модель o1 обеспечивает мощную поддержку множества рабочих процессов агента Lindy, рабочего ИИ-ассистента OpenAI. Модель способна использовать вызовы функций для извлечения ключевой информации из календаря или электронной почты пользователя, чтобы автоматически помогать ему планировать встречи, отправлять электронные письма и управлять другими аспектами его повседневных задач". OpenAI переключила все прошлые шаги агента Линди, которые вызывали проблемы, на модель o1 и заметила, что функциональность агента Линди стала безупречной практически за одну ночь!"
--Линди.ИИ, помощник по работе с искусственным интеллектом
5. Визуальное мышление: понимание информации, скрывающейся за изображением
На сегодняшний день.o1 это единственная модель вывода, поддерживающая возможности визуального вывода. o1 вместе с GPT-4o Значительная разница междуo1 Даже самая сложная визуальная информация, такая как сложно структурированные графики, таблицы или фотографии с плохим качеством изображения, может быть эффективно обработана. Это подчеркивает важность o1 Уникальные преимущества в области обработки визуальной информации.
Safetykit, платформа для мониторинга торговцев с помощью искусственного интеллекта, отмечает: "OpenAI стремится автоматизировать проверку рисков и соответствия требованиям для миллионов онлайн-продуктов, включая реплики роскошных ювелирных изделий, исчезающие виды и регулируемые товары. В самой сложной задаче OpenAI по классификации изображений модель GPT-4o была точна только на 50%. и
o1Модель достигает впечатляющей точности до 88% без каких-либо изменений в существующих процессах OpenAI".-Safetykit, платформа для мониторинга торговых предприятий с искусственным интеллектом
Внутренние тесты OpenAI также показали, чтоo1 Модель способна определять крепеж и материалы по высокодетализированным архитектурным чертежам и генерировать комплексную спецификацию материалов. Одно из самых удивительных явлений, наблюдаемых OpenAI, заключается в том, чтоo1 Модель способна устанавливать связи между различными изображениями - например, она может взять легенду на одной странице архитектурного чертежа и точно применить ее к другой странице без явных указаний. В примере ниже мы видим, что для "Деревянной колонны 4x4 PT"o1 Модель смогла правильно распознать, что "PT" означает "обработанный давлением", согласно легенде. Это хорошая демонстрация того, что o1 возможности модели в понимании сложной визуальной информации и междокументных рассуждениях.

6. обзор кода, отладка и улучшение качества: стремление к совершенству, оптимизация кода
Модели вывода отлично справляются с проверкой и улучшением кода и особенно хороши при работе с крупными базами кода. Учитывая относительно высокую латентность моделей выводов, задачи проверки кода обычно выполняются в фоновом режиме. Это позволяет предположить, что, несмотря на задержку, модели вывода имеют важное применение в анализе кода и контроле качества, особенно в сценариях, не требующих высокой производительности в реальном времени.
Стартап CodeRabbit, специализирующийся на рецензировании ИИ-кода, сообщает: "OpenAI предлагает услуги по автоматизированному рецензированию ИИ-кода на платформах хостинга кода, таких как GitHub и GitLab. Процесс рецензирования кода по своей сути нечувствителен к задержкам, но требует глубокого понимания изменений кода в нескольких файлах. Именно здесь модель o1 демонстрирует превосходство - она надежно обнаруживает тонкие изменения в кодовой базе, которые могут быть легко пропущены человеческим рецензентом. После перехода на модели серии o компания OpenAI увидела 3-кратное увеличение конверсии продуктов".
-CodeRabbit, стартап, специализирующийся на рецензировании кода с помощью искусственного интеллекта
несмотря на то, что GPT-4o ответить пением GPT-4o mini Модель может лучше подходить для сценариев кодирования с низкой задержкой, но OpenAI также отмечает, что o3-mini Модель отлично подходит для случаев генерации кода, нечувствительного к задержкам. Это означает, что o3-mini Он также имеет потенциал в области генерации кода, особенно в сценариях приложений, требующих высокого качества кода и относительно щадящих задержку.
Стартапы, работающие на основе искусственного интеллекта для завершения кода Codeium прокомментировал: "Даже перед лицом сложных задач по кодированию
o3-miniМодели также способны последовательно генерировать высококачественный, убедительный код и очень часто дают правильное решение, когда проблема хорошо определена. Другие модели могут быть пригодны только для небольших, быстрых итераций кода, ноo3-miniМодели специализируются на планировании и реализации сложных систем проектирования программного обеспечения".-Codeium, стартап по расширению кода, управляемый искусственным интеллектом.
7. оценка моделей и бенчмаркинг: объективная оценка и выбор лучших из лучших
OpenAI также обнаружил, что модели выводов хорошо работают при сравнении и оценке ответов других моделей. Валидация данных очень важна для обеспечения качества и надежности наборов данных, особенно в таких чувствительных областях, как здравоохранение. Традиционные методы проверки опираются на заранее определенные правила и шаблоны, но такие методы, как o1 ответить пением o3-mini Такие продвинутые модели способны понимать контекст и рассуждать о нем, что позволяет использовать более гибкие и интеллектуальные методы проверки. Это позволяет предположить, что модели вывода могут выступать в роли "рефери" для оценки качества результатов других моделей, что очень важно для итеративной оптимизации систем ИИ.
Braintrust, платформа для оценки ИИ, отмечает: "Многие клиенты используют функцию LLM-as-a-judge в платформе Braintrust как часть процесса оценки. Например, компания, работающая в сфере здравоохранения, может использовать такой инструмент, как
gpt-4oТакая мастер-модель позволяет обобщить историю болезни пациента, а затем использоватьo1модель для оценки качества аннотаций. Один из клиентов Braintrust обнаружил, что использование4oОценка F1 составляет 0,12, когда модель используется в качестве рефери, а переключение наo1После моделирования оценка F1 подскочила до 0,74! В этих примерах использования они обнаружили, чтоo1Рассудочная способность модели позволяет улавливать нюансы результатов завершения, особенно в самых сложных и трудных задачах по подсчету очков".-Braintrust, платформа для оценки искусственного интеллекта
Советы по эффективному созданию моделей рассуждений: простота превыше всего
Рассуждающие модели, как правило, работают лучше всего, когда они получают четкие и ясные подсказки. Некоторые традиционные методы разработки подсказок, такие как указание модели "думать шаг за шагом", могут оказаться неэффективными для повышения производительности, а иногда и вовсе могут быть контрпродуктивными. Ниже приведены некоторые лучшие практики, или вы можете просто обратиться к примерам подсказок, чтобы начать работу.
- Сообщения разработчиков заменяют системные сообщения. через (щель)
o1-2024-12-17В последующих версиях модель выводов стала поддерживать сообщения разработчика, а не традиционные системные сообщения, чтобы соответствовать поведению цепочки инструкций, описанной в спецификации модели. - Сохраняйте простоту и прямоту подсказок. Разумные модели хорошо понимают и реагируют на четкие и лаконичные инструкции. Поэтому четкие и прямые инструкции более эффективны для рассуждающих моделей, чем сложные техники разработки подсказок.
- Избегание цепочек мыслей Совет. Нет необходимости просить модель рассуждения "продумать шаг за шагом" или "объяснить процесс рассуждения", поскольку она уже обладает внутренними возможностями рассуждения. Такие излишние подсказки могут, наоборот, ухудшить работу модели.
- Используйте разделители для повышения ясности. Использование разделителей, таких как Markdown, XML-теги и заголовки разделов, для четкого обозначения различных частей входных данных помогает модели точно понять содержание различных разделов.
- Приоритет отдается попыткам найти нулевой образец, прежде чем рассматривать меньшие образцы:. Модели вывода обычно дают хорошие результаты, не нуждаясь в небольшом количестве примеров. Поэтому рекомендуется сначала попробовать написать подсказки с нулевым образцом без примеров. Если у вас есть более сложные требования к выходным результатам, может быть полезно включить в подсказки примеры входных данных и желаемых выходных результатов. Однако важно убедиться, что примеры полностью соответствуют инструкциям подсказки, так как отклонения между ними могут привести к плохим результатам.
- Дайте четкие и конкретные указания. Если есть явные ограничения, которые могут ограничить диапазон ответов модели (например, "Предложите решение с бюджетом менее 500 долларов"), четко сформулируйте эти ограничения в подсказке.
- Уточнение конечной цели. В инструкциях как можно конкретнее опишите критерии, по которым будут оцениваться успешные ответы, и поощряйте модель продолжать рассуждения и итерации до тех пор, пока критерии успеха не будут достигнуты.
- Контроль форматирования в формате Markdown. через (щель)
o1-2024-12-17Начиная с версии 1, модели выводов в API по умолчанию не генерируют ответы с форматированием в формате Markdown. Если вы хотите, чтобы модель включала форматирование Markdown в свои ответы, добавьте строкуFormatting re-enabled.
Примеры использования API модели выводов
Модели умозаключений уникальны своим процессом "мышления". В отличие от традиционных языковых моделей, модели умозаключений глубоко задумываются и строят длинную цепочку рассуждений, прежде чем дать ответ. Как говорится в официальном описании OpenAI, эти модели глубоко задумываются, прежде чем ответить пользователю. Этот механизм позволяет моделям умозаключений справляться с такими задачами, как решение сложных головоломок, кодирование, научные рассуждения и многоэтапное планирование рабочих процессов агентов.
Подобно модели GPT в OpenAI, OpenAI предоставляет две модели вывода для удовлетворения различных потребностей:o3-mini Модель отличается меньшими размерами и высокой скоростью, в то время как жетон Затраты также относительно невелики; и o1 Модели, с другой стороны, обменивают больший масштаб и немного меньшую скорость на более мощное решение задач.o1 Модели обычно генерируют более качественные ответы при решении сложных задач и демонстрируют лучшие показатели обобщения в разных областях.
быстрый старт
Чтобы помочь разработчикам быстро начать работу, OpenAI предоставляет простой в использовании интерфейс API. Вот пример быстрого старта, как использовать модель вывода в завершении чата:
Использование моделей вывода в завершении чата
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Интенсивность рассуждений: управление глубиной мышления в модели
В приведенном выше примереreasoning_effort Этот параметр (во время разработки этих моделей его ласково называли "соком") используется для того, чтобы определить, сколько вычислений для выводов выполняет модель перед генерацией ответа. Пользователь может указать для этого параметра low, иmedium возможно high Одно из трех значений. Где.low Модель ориентирована на скорость и снижение стоимости токенов, в то время как high Режим позволяет модели проводить более глубокие и всесторонние рассуждения, но увеличивает потребление токенов и время отклика. По умолчанию установлено значение medium, направленный на достижение баланса между скоростью и точностью вычислений. Разработчики могут гибко регулировать интенсивность вывода в соответствии с потребностями реальных сценариев применения для достижения оптимальной производительности и экономической эффективности.
Как работает рассуждение: глубокий анализ процесса "мышления" моделей
Модель вывода опирается на традиционные входные и выходные лексемы, вводя Рассуждения о токенах Это концепция. Эти маркеры умозаключений являются аналогом "мыслительного процесса" модели, и модель использует их для декомпозиции своего понимания подсказок пользователя и изучения множества возможных путей для генерации ответов. Только после завершения генерации маркеров умозаключений модель выводит окончательный ответ, дополняющий маркер, видимый пользователю, и отбрасывает маркер умозаключения из контекста.
На следующем рисунке показан пример многоэтапного диалога между пользователем и помощником. На каждом этапе диалога входные и выходные лексемы сохраняются, а лексемы вывода отбрасываются моделью.
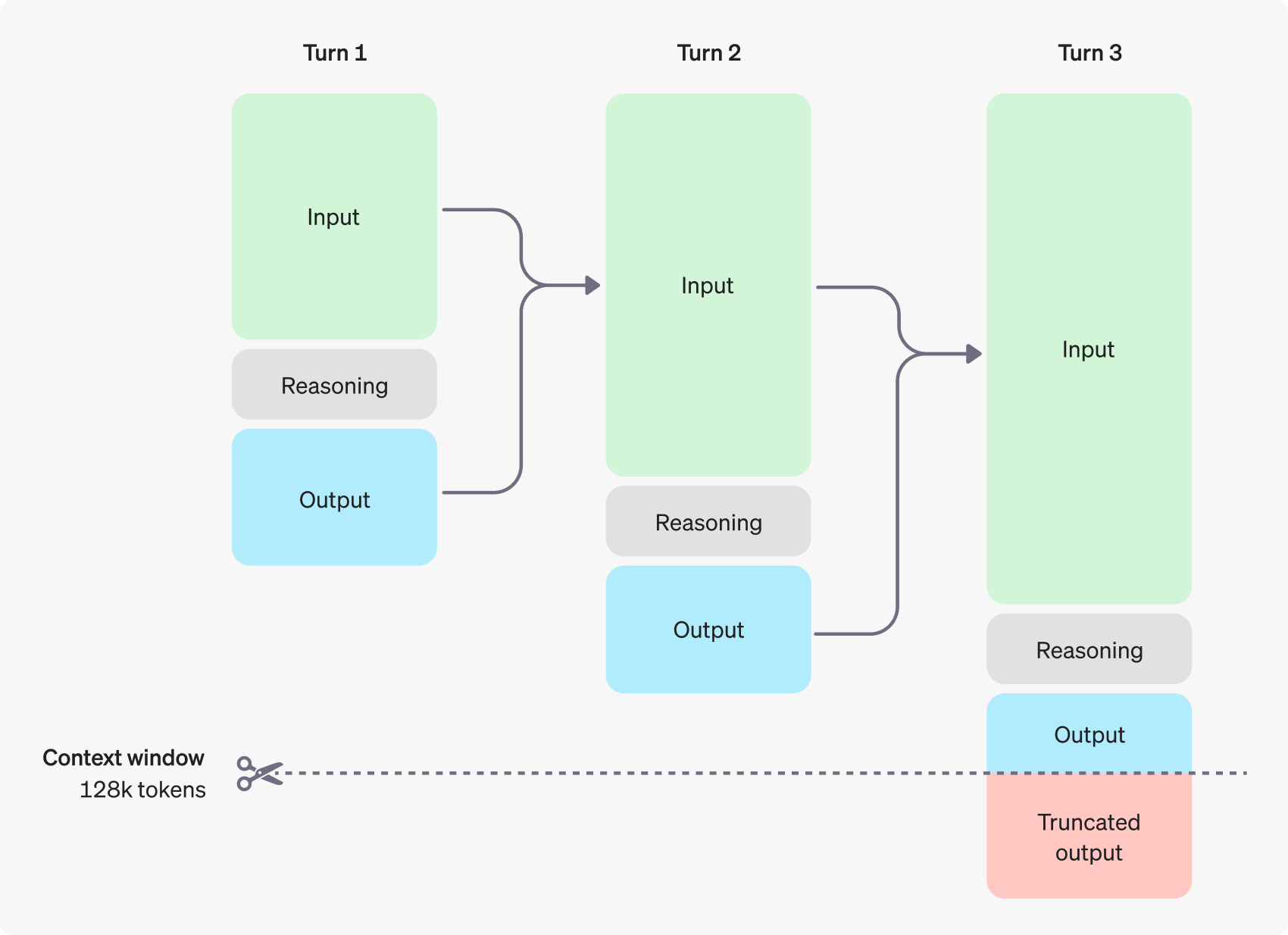
Стоит отметить, что хотя токены выводов не видны через интерфейс API, они все равно занимают пространство контекстного окна модели, учитываются в общем объеме использования токенов и должны оплачиваться так же, как и токены вывода. Поэтому на практике разработчикам необходимо учитывать влияние токенов выводов и соответствующим образом управлять контекстным окном модели и потреблением токенов.
Управление контекстными окнами: обеспечение моделей достаточным "пространством для размышлений"
При создании запроса на завершение важно убедиться, что в контекстном окне достаточно места для маркеров выводов, генерируемых моделью. В зависимости от сложности проблемы, модели может потребоваться сгенерировать от сотен до десятков тысяч маркеров выводов. completion_tokens_details поле, чтобы узнать точное количество лексем, использованных моделью для конкретного запроса:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Длина контекстного окна для различных моделей доступна пользователю на странице Model Reference. Правильная оценка и управление контекстным окном необходимы для обеспечения эффективной работы модели вывода.
Контроль затрат: тонкая настройка и оптимизация потребления токенов
Чтобы эффективно управлять стоимостью модели вывода, пользователи могут использовать max_completion_tokens параметр, ограничивающий общее количество лексем, генерируемых моделью, включая лексемы вывода и дополняющие лексемы.
В более ранних моделяхmax_tokens Параметр контролирует как количество лексем, генерируемых моделью, так и количество лексем, видимых пользователю, которые всегда одинаковы. Однако для моделей вывода общее количество лексем, генерируемых моделью, может превышать количество лексем, которые в итоге видит пользователь, из-за введения внутренних лексем вывода.
Учтите, что некоторые приложения могут полагаться на max_tokens соответствует количеству токенов, возвращаемых API, OpenAI ввел специальный параметр max_completion_tokens Этот параметр позволяет более явно контролировать общее количество лексем, генерируемых моделью, включая лексемы вывода и видимые пользователем лексемы дополнения. Эта явная настройка параметра обеспечивает плавный переход для существующих приложений, использующих новую модель, избегая потенциальных проблем совместимости. Для всех предыдущих моделей параметрmax_tokens Функция параметра остается неизменной.
Предоставление пространства для рассуждений: избегайте прерывания "размышлений"
Если количество сгенерированных токенов достигает предела контекстного окна или установленного пользователем max_completion_tokens API вернет ответ о завершении чата со значением finish_reason Поле устанавливается на length. Это может произойти до того, как модель сгенерирует какие-либо видимые пользователю дополнительные маркеры, что означает, что пользователь может заплатить за маркеры ввода и маркеры вывода, но в конечном итоге не получить никаких видимых ответов.
Чтобы избежать этого, всегда следите за тем, чтобы в контекстном окне было достаточно места, или поместите max_completion_tokens openAI рекомендует при первом опробовании этих моделей вычислений зарезервировать место не менее чем на 25 000 лексем для процессов вывода и вывода. По мере того как пользователи будут знакомиться с количеством маркеров, необходимых для их подсказок, размер буфера можно будет регулировать по мере необходимости для более детального контроля затрат.
Совет: раскрытие потенциала моделей рассуждений
Существуют некоторые ключевые различия, о которых пользователь должен знать при запросе моделей вывода и моделей GPT. В целом, модель умозаключений, как правило, дает лучшие результаты при выполнении задач, в которых даются только высокоуровневые указания. Это контрастирует с моделью GPT, которая обычно лучше работает при получении очень точных инструкций.
- Модели рассуждений, как у опытных старших коллег -- Пользователям можно доверить самостоятельную работу над конкретными деталями, просто сообщив им, чего они хотят добиться.
- Модель GPT больше похожа на младшего помощника -- Они работают лучше всего, когда у них есть четкие и подробные инструкции по созданию конкретного результата.
Чтобы узнать больше о лучших практиках использования моделей вывода, обратитесь к официальному руководству OpenAI.
Пример совета: демонстрация сценария применения
Кодирование (рефакторинг кода)
Модели OpenAI серии o демонстрируют мощные возможности понимания алгоритмов и генерации кода. Следующий пример демонстрирует, как модель o1 может быть использована для рефакторинга по определенным критериям React Компонент.
рефакторинг кода
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Код (планирование проекта)
Модель o-серии OpenAI также хорошо подходит для разработки многоэтапных планов проектов. В следующем примере показано, как использовать модель o1 для создания полной структуры файловой системы для приложения на Python и генерации кода на Python, реализующего требуемую функциональность.
Планирование и создание проекта на языке Python
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Исследования в области НТИМ
Модели OpenAI серии o продемонстрировали отличную производительность в исследованиях STEM (Science, Technology, Engineering and Mathematics). Эти модели часто показывают впечатляющие результаты при выполнении заданий, предназначенных для поддержки базовых исследовательских задач.
Поднятие вопросов, связанных с исследованиями в области фундаментальных наук
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
официальный пример
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...