
OmniVinci - Омнимодальная модель большого языка с открытым исходным кодом от NVIDIA

Что такое OmniVinci?
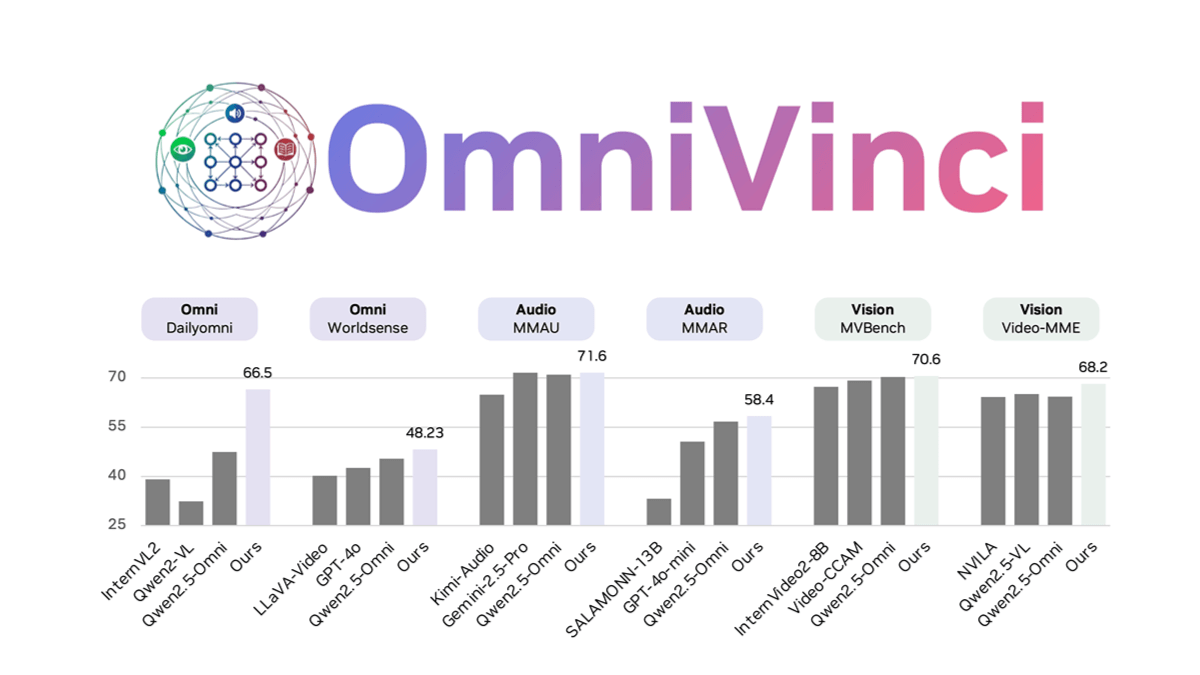
OmniVinci - это крупномасштабная языковая модель с открытым исходным кодом, полностью модальная, разработанная NVIDIA, которая решает проблему модальной фрагментации в мультимодальных моделях за счет инноваций в архитектуре и оптимизации данных. Выравнивание визуальных и аудио вкраплений улучшено с помощью OmniAlignNet, которая использует группировки временных вкраплений для получения информации об относительном временном выравнивании и ограниченные вращательные временные вкрапления для кодирования абсолютной временной информации. OmniVinci генерирует большое количество образцов моно- и омни-модальных диалогов для обучения благодаря синтезу данных и хорошо продуманной стратегии распределения данных. Двухфазная стратегия обучения - унимодальное обучение с последующим совместным омнимодальным обучением - эффективно интегрирует мультимодальное понимание. OmniVinci демонстрирует хорошие результаты в нескольких бенчмарках, например, в DailyOmni он на 19,05 балла превосходит Qwen2.5-Omni, а количество обучающих лексем значительно сокращается. OmniVinci применялся для интерпретации медицинских компьютерных томограмм, обнаружения полупроводниковых приборов и т. д. и продемонстрировал высокую способность к мультимодальному пониманию.
Особенности OmniVinci
- мультимодальное пониманиеСпособность обрабатывать визуальную, аудио и текстовую информацию одновременно, что позволяет осуществлять кросс-модальное понимание и рассуждения, например, подробное описание может быть создано на основе видеоконтента, включающего как визуальную, так и аудиоинформацию.
- Инновации в модельной архитектуре: Улучшение выравнивания визуальных и аудио вкраплений с помощью OmniAlignNet, использование группировки временных вкраплений для захвата информации об относительном временном выравнивании визуальных и аудио сигналов и кодирование абсолютной временной информации с помощью ограниченных вращательных временных вкраплений для улучшения понимания моделью мультимодальных сигналов.
- Синтез и оптимизация данных: Генерировать большое количество унимодальных и омнимодальных образцов диалога с помощью синтеза данных и хорошо продуманной стратегии распределения данных для оптимизации обучающих данных и улучшения обобщающей способности и производительности модели.
- Двухэтапная стратегия обучения: Двухэтапная стратегия унимодального обучения и совместного обучения полным модальностям используется для развития способностей к визуальному и аудиальному восприятию по отдельности, а затем их интеграции для достижения кросс-модального восприятия, что эффективно повышает способность модели к мультимодальному рассуждению.
- Эффективное обучение: В процессе обучения OmniVinci достигает отличной производительности, используя небольшое количество обучающих маркеров (0,2 триллиона), что значительно снижает потребление обучающих ресурсов по сравнению с другими моделями.
Основные преимущества OmniVinci
- Мощное мультимодальное понимание: Способность обрабатывать информацию из нескольких модальностей, таких как зрение, звук и текст одновременно, что позволяет осуществлять межмодальное понимание и рассуждения.
- Эффективные стратегии обучения: Двухэтапный подход к обучению, когда за одномодальным обучением следует совместное обучение с использованием всех модальностей, позволяет эффективно интегрировать мультимодальное понимание, сокращая при этом расход ресурсов на обучение.
- Инновационная архитектура модели: Улучшенное выравнивание визуальных и аудио вкраплений с помощью OmniAlignNet, группировка временных вкраплений и ограниченное вращательное временное вкрапление улучшают понимание мультимодальных сигналов моделью.
- Оптимизированная подготовка данных: Генерировать большое количество высококачественных унимодальных и омнимодальных образцов диалогов с помощью синтеза данных и хорошо продуманных стратегий распределения данных для оптимизации обучающих данных и улучшения обобщения модели.
- Отличная производительность: превосходит другие модели в нескольких бенчмарках, например, значительно превосходит другие модели в таких задачах, как DailyOmni, MMAR и Video-MME, при значительном сокращении количества обучающих лексем.
Какой официальный сайт OmniVinci
- Веб-сайт проекта:: https://nvlabs.github.io/OmniVinci/
- Репозиторий Github:: https://github.com/NVlabs/OmniVinci
- Библиотека моделей HuggingFace:: https://huggingface.co/nvidia/omnivinci
- Технический документ arXiv:: https://arxiv.org/pdf/2510.15870
Для кого предназначен OmniVinci?
- Исследователи искусственного интеллекта: Ученые с исследовательскими интересами в области мультимодального обучения, крупномасштабного моделирования языка и кросс-модального понимания могут изучить новые направления исследований и технологические прорывы с помощью OmniVinci.
- Инженер по машинному обучениюИнженеры, разрабатывающие и оптимизирующие мультимодальные приложения, могут использовать OmniVinci для повышения производительности моделей в реальных проектах.
- Практикующие специалисты медицинской отраслиНапример, радиологи и медицинские исследователи могут использовать мультимодальное понимание OmniVinci для более точной интерпретации медицинских изображений и связанных с ними данных.
- Специалисты по промышленной автоматизации: В "умном" производстве используйте возможности OmniVinci по обработке изображений и звука для повышения эффективности проверки оборудования и контроля качества.
- Разработчик робототехникиИнженеры, разрабатывающие интеллектуальные роботизированные системы, могут использовать OmniVinci для улучшения способности робота чувствовать и понимать окружающую среду.
- специалист по анализу данныхУченые, которым требуется обработка больших объемов данных и мультимодальный анализ данных, могут использовать OmniVinci для повышения эффективности обработки данных и точности анализа.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...