
MinerU2.5 - открытая модель синтаксического анализа документов из Шанхайской лаборатории искусственного интеллекта и Пекинского университета

Что такое MinerU2.5?
MinerU2.5 - это модель визуального языка, разработанная совместно Шанхайской лабораторией искусственного интеллекта и командой Пекинского университета и предназначенная для эффективного разбора изображений документов высокого разрешения. Основная инновация заключается в двухфазном дизайне "обнаружение глобального макета с последующим распознаванием локального содержимого": первая фаза быстро определяет структуру документа и порядок чтения по миниатюрам низкого разрешения, а вторая фаза точно распознает ключевые области после обрезки до исходного разрешения. Модель имеет разрешение всего 1,2B, но может сохранять высокую точность при работе с документами в формате 8K, а измеренная скорость обработки при использовании одной карты RTX 4090 составляет до 2,12 страниц/секунду, что значительно лучше, чем у аналогичных решений. Уникальность также проявляется в специальной оптимизации сложных элементов, таких как таблицы и формулы, например, сжатие длины HTML-последовательности с помощью промежуточного языка OTSL, а также технология атомарной декомпозиции и реорганизации формул для решения проблемы иллюзии длинной структуры формул.
Особенности MinerU2.5
- Эффективная архитектура двухэтапного синтаксического анализаПрименяется стратегия разделения "сначала грубое, потом тонкое": на первом этапе анализируется глобальный макет уменьшенного изображения, чтобы быстро определить текстовые блоки, таблицы, формулы и другие структурные элементы документа; на втором этапе определяется тонкое содержание области высокого разрешения только в исходном разрешении, чтобы эффективно сбалансировать вычислительные затраты и сохранение деталей.
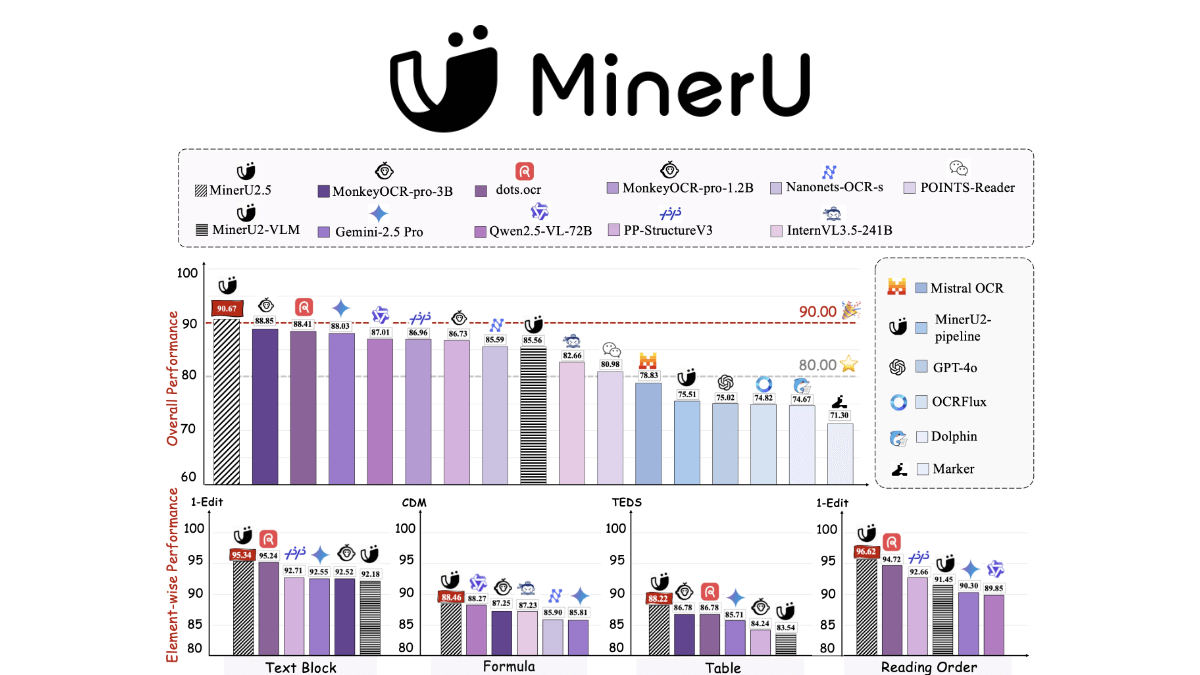
- Превосходная точность и производительность: Несмотря на то, что количество параметров составляет всего 1.2B, точность комплексного разбора в нескольких авторитетных бенчмарках, таких как OmniDocBench, olmOCR-bench и т.д., превосходит таковую у Близнецы 2.5 Pro, GPT-4o, Qwen2.5-VL-72B и других высококлассных мультимодальных макромоделей общего назначения, а также значительно превосходит профессиональные инструменты для разбора документов, такие как dots.ocr и MonkeyOCR.
- Мощная способность адаптироваться к сложным сценамБлагодаря архитектуре мультимодального слияния он глубоко интегрирует распознавание текста и визуальный анализ макета и может эффективно справляться со сценариями, в которых традиционный OCR не справляется, например с отсутствующими строками таблицы, перекошенным текстом и сложными формулами. Его производительность стабильна в экстремальных условиях, таких как многоколоночная верстка, интерференция иллюстраций, нечеткие искажения и сканирование с низким разрешением, и он поддерживает распознавание смешанной аранжировки на 20+ языках, таких как китайский, английский, японский и корейский.
- Чрезвычайно практичное и эффективное развертываниеМодель имеет небольшие размеры, легко интегрируется и обеспечивает высокую скорость разбора от 1,7 до 2 страниц в секунду на потребительских видеокартах, таких как RTX 3090 или 4090, что делает ее идеальным решением для таких реальных задач, как создание базы знаний RAG (retrieval-enhanced generation) и извлечение документов в больших объемах.
- Всесторонняя поддержка задач со структурированными результатамиАнализ макета: инновационно реконструирует анализ макета в многозадачную проблему, которая одновременно предсказывает положение, категорию, угол поворота и порядок чтения элементов документа в одном умозаключении. Поддерживает вывод результатов разбора в Markdown, JSON и другие структурированные форматы для последующей обработки и применения.
Основные преимущества MinerU2.5
- Усовершенствованная архитектура двухступенчатого синтаксического анализаПрименяется стратегия разделения, при которой первый этап выполняет эффективный глобальный анализ макета на уменьшенных изображениях для выявления элементов структуры документа, а второй этап выполняет тонкое распознавание контента на областях высокого разрешения в исходном разрешении, эффективно балансируя между вычислительными затратами и сохранением деталей.
- Отличная производительностьВ OmniDocBench, olmOCR-bench и других авторитетных бенчмарках точность синтаксического анализа значительно превосходит точность синтаксического анализа лучших общих мультимодальных больших моделей, таких как Gemini 2.5 Pro, GPT-4o, Qwen2.5-VL-72B и т.д., а также значительно опережает профессиональные инструменты синтаксического анализа документов, такие как dots.ocr, MonkeyOCR, PP-. StructureV3 и другие профессиональные инструменты синтаксического анализа документов.
- Расширенная парадигма многозадачности: Переосмысливая анализ макета как многозадачную задачу, он одновременно предсказывает положение, категорию, угол поворота и порядок чтения элементов документа в одном выводе, эффективно решая такие сложные задачи, как разбор повернутых элементов.
- Чрезвычайно практично и эффективноМодель имеет небольшие размеры, легко интегрируется и может выполнять высокоскоростной разбор 1,7 страниц в секунду на потребительских видеокартах, что идеально подходит для практических сценариев применения, таких как построение базы знаний RAG (Retrieval Augmented Generation), извлечение крупных документов и т.д.
Каков официальный сайт MinerU2.5?
- Библиотека моделей HuggingFace:: https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
- Технический документ arXiv:: https://arxiv.org/pdf/2509.22186
Люди, для которых предназначен MinerU2.5
- Группа по оцифровке и управлению знаниями на предприятииОн подходит для предприятий, которым необходимо решить задачу оцифровки большого количества договоров, отчетов, архивов и других бумажных документов, и может эффективно завершить разбор отсканированных документов, PDF-файлов и других неструктурированных данных в библиотеке, а также значительно повысить эффективность построения базы знаний RAG (Retrieval Augmented Generation).
- Разработчики и команды инженеров по искусственному интеллектуМодель имеет полностью открытый исходный код, небольшой эталонный размер (1,2 Б), поддерживает развертывание на потребительских видеокартах (например, RTX 4090) и идеально подходит для разработчиков и инженерных команд, желающих интегрировать высокопроизводительные возможности OCR в свои продукты без необходимости полагаться на крупные API с закрытым исходным кодом.
- Научно-исследовательские институты и академические круги: Предоставляет мощную базовую модель с открытым исходным кодом для академических исследований в области понимания документов, мультимодального макромоделирования и т.д., на основе которой исследователи могут проводить дальнейшие эксперименты, тонкую настройку или сравнение методов.
- Финансовые, юридические и правительственные учрежденияMinerU2.5 отвечает высоким требованиям к высокоточному извлечению структурированной информации, отлично справляясь со сценариями со сложным набором текста и отсутствующими строками формы, когда необходимо обработать большое количество сложно структурированных форм, договоров и бланков.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...