
Meta: подход к адаптации (практическому применению) больших языковых моделей

Оригинальный текст:
https://ai.meta.com/blog/adapting-large-language-models-llms/
https://ai.meta.com/blog/when-to-fine-tune-llms-vs-other-techniques/
https://ai.meta.com/blog/how-to-fine-tune-llms-peft-dataset-curation/
方法-1")
Это первая из трех частей серии статей в блоге, посвященных адаптации больших языковых моделей (LLM) с открытым исходным кодом. В этой статье мы узнаем о различных методах адаптации LLM к данным домена.
вводная
Большие языковые модели (LLM) в широком спектре языковых задач и обработке естественного языка (NLP) бенчмаркингКоличество примеров использования продуктов, основанных на этих "общих" моделях, растет. Количество примеров использования продуктов, основанных на этих "общих" моделях, растет. В этом блоге мы дадим рекомендации для небольших команд разработчиков ИИ-продуктов, которые хотят адаптировать и интегрировать LLM в свои проекты. Начнем с прояснения (часто запутанной) терминологии, связанной с LLM, затем кратко сравним различные подходы к адаптации и, наконец, порекомендуем пошаговую блок-схему для определения правильного подхода для вашего случая использования.
Метод адаптации LLM
предтренировочный курс
Предварительное обучение - это использование триллионов данных. жетоны Процесс обучения LLM с нуля. Модели обучаются с помощью алгоритмов самоконтроля. Чаще всего обучение предсказывает с помощью авторегрессии следующее жетон для выполнения (так называемое каузальное моделирование языка). Предварительное обучение обычно занимает тысячи часов работы GPU (105 - 107 [источник1, источник2]) распределяются между несколькими графическими процессорами. Предварительно обученная модель вывода называется базовая модель.
Непрерывная предварительная подготовка
Непрерывное предварительное обучение (также известное как двухэтапное предварительное обучение) включает в себя дальнейшее обучение базовой модели на новых, невидимых данных о домене. При этом используется тот же алгоритм самоконтроля, что и при первоначальном предварительном обучении. Как правило, изменяются все веса модели и часть исходных данных смешивается с новыми.
тонкая настройка
Тонкая настройка - это процесс адаптации предварительно обученной языковой модели с использованием аннотированного набора данных под наблюдением или с помощью методов обучения с подкреплением. По сравнению с предварительным обучением есть два основных отличия:
- Контролируемое обучение на аннотированных наборах данных - содержащих правильные метки/ответы/предпочтения - не самоконтролируемое обучение
- Требуется меньшее количество жетонов (тысячи или миллионы, а не миллиарды или триллионы, необходимые для предварительного обучения), а главная цель - улучшить выполнение команд, согласованность действий человека, выполнение задач и т.д.
Есть два аспекта понимания текущей сетки тонкой настройки: процент измененных параметров и новые возможности, добавленные в результате тонкой настройки.
Процент изменения параметров
Существует два типа алгоритмов в зависимости от количества изменяемых параметров:
- Полностью отлажена: Как следует из названия, это предполагает изменение всех параметров модели, включая традиционную тонкую настройку небольших моделей, таких как XLMR и BERT (100 - 300 миллионов параметров), а также Ллама 2Тонкая настройка больших моделей, таких как GPT3 (более 1 миллиарда параметров).
- Эффективная точная настройка параметров (PEFT): В отличие от точной настройки всех весов LLM, алгоритм PEFT настраивает только небольшое количество дополнительных параметров или обновляет подмножество параметров предварительного обучения, обычно 1 - 6% от общего числа параметров.
Возможность дополнить базовую модель
Целью тонкой настройки является добавление возможностей к предварительно обученным моделям - например, следование инструкциям, согласование с людьми и т. д. Llama 2 для настройки диалога - это тонкая настройка модели с возможностью добавления следования инструкциям и выравнивания. типичный пример.
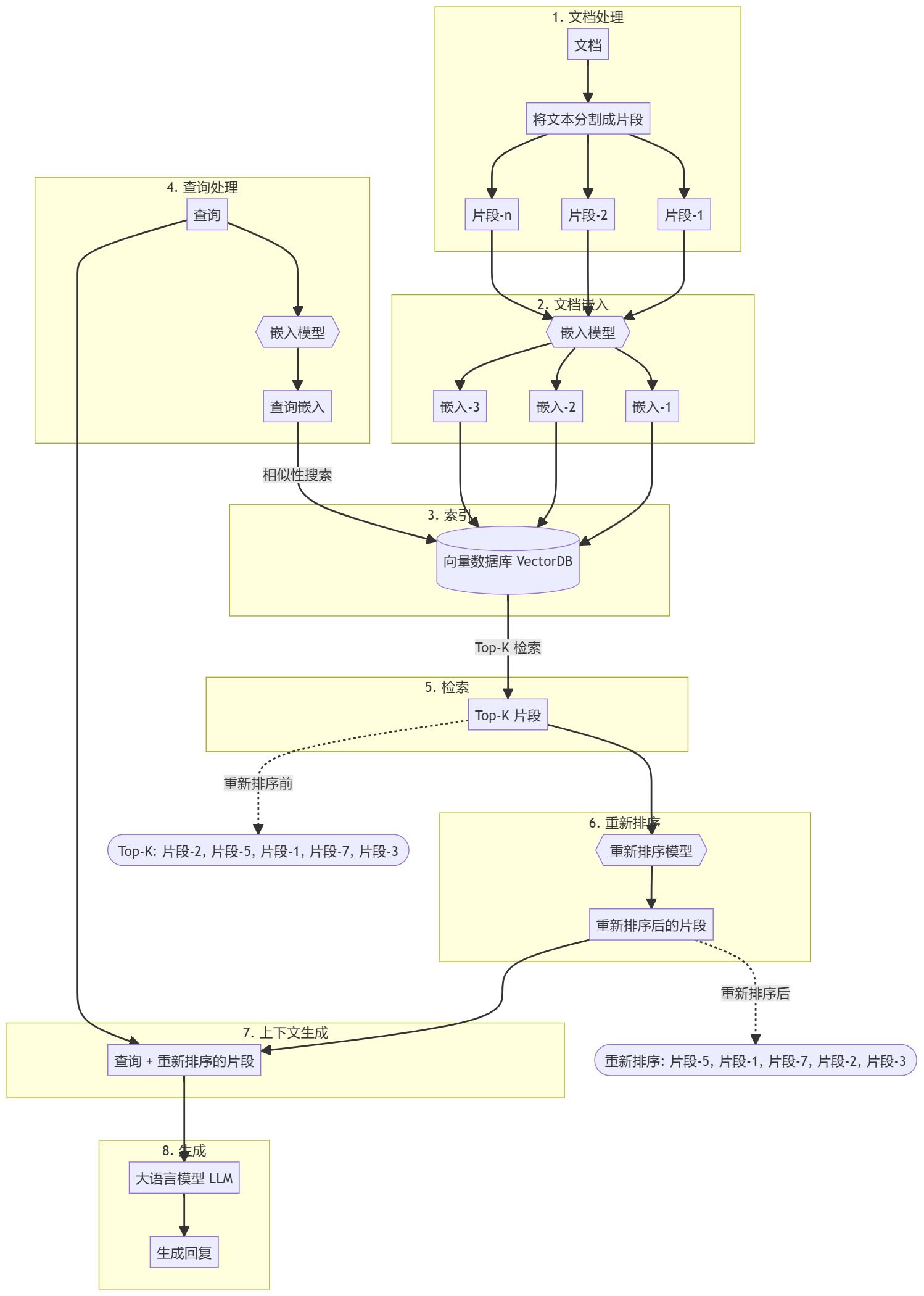
Поиск расширенной генерации (RAG)
Организации также могут адаптироваться к LLM, добавляя базы знаний по конкретной области.RAG - это, по сути, "генерация текста LLM на основе поиска".RAG, который будет запущен в 2020 году, использует динамические контексты подсказок, полученные на основе вопроса пользователя и снабженные подсказками LLM, чтобы направить его на использование найденного контента вместо предварительно обученных - и потенциально устаревших - знаний. -знания.Чат LangChain популярный пример чатбота для вопросов и ответов по документам на основе RAG с LangChain.
Контекстное обучение (ICL)
В ICL мы адаптировали LLM, поместив в подсказки примеры прототипов, и несколько исследований показали, что "демонстрация на примере" эффективна. Эти примеры могут содержать различные типы информации:
- Только текст на входе и выходе - т.е. меньше выборки для обучения
- Следы рассуждений: добавьте промежуточные шаги рассуждений; ср. цепочка мыслей (CoT) Советы
- Дорожка планирования и размышлений: добавьте информацию, которая научит LLM планировать и размышлять о стратегии решения проблем; см. ReACT
Существует множество других стратегий изменения подсказок, которыеРуководство по проектированию наконечниковВключен всеобъемлющий обзор.
Выбор правильного метода адаптации
Чтобы решить, какой из перечисленных методов подходит для конкретного приложения, необходимо учитывать различные факторы: возможности модели, необходимые для решения поставленной задачи, стоимость обучения, стоимость вывода, тип набора данных и так далее. На блок-схеме ниже приведены наши рекомендации, которые помогут вам выбрать подходящий метод адаптации Большой языковой модели (LLM).
方法-1")
❌ Предварительная подготовка
Предварительное обучение - важная часть обучения LLM, использующая варианты предсказания токенов в качестве функций потерь. Его самоконтролируемая природа позволяет проводить обучение на больших объемах данных. Например, Llama 2 была обучена на 2 триллионах токенов. Это требует огромной вычислительной инфраструктуры: стоимость Llama 2 70B 1 720 320 часов работы графического процессора. Поэтому мы не рекомендуем предварительное обучение как эффективный метод адаптации LLM для команд с ограниченными ресурсами.
Поскольку предварительное обучение требует больших вычислительных затрат, обновление весов уже предварительно обученной модели может стать эффективным способом адаптации LLM к конкретной задаче. Любой подход к обновлению весов предварительно обученной модели подвержен явлению катастрофического забывания - термину, используемому для описания того, как модель забывает ранее полученные навыки и знания. Например.данное исследованиепоказывает, что модели, прошедшие тонкую настройку в медицинской области, хуже справляются с заданиями на следование инструкциям и обычными вопросами и ответами. Другие исследования также показали, что общие знания, полученные в ходе предварительного обучения, могут быть забыты во время последующего обучения. Например.данное исследованиеНекоторые свидетельства забывания знаний LLM представлены с точки зрения знаний о предметной области, рассуждений и понимания прочитанного.
❌ Непрерывная предварительная подготовка
Учитывая катастрофическое забывание, последние разработки показывают, что непрерывное предварительное обучение (НПО) может еще больше повысить производительность при меньших вычислительных затратах, необходимых для предварительного обучения. CPT может быть полезно для задач, требующих от LLM приобретения новых навыков преобразования. Например.Сообщается, что...Непрерывное предварительное обучение успешно способствует развитию многоязычия.
Однако CPT по-прежнему остается дорогостоящим процессом, требующим значительных данных и вычислительных ресурсов. Например, набор Pythia прошел второй этап предварительного обучения, в результате которого были созданы ФинПития-6.9BЭта модель разработана для финансовых данных. Эта модель, разработанная специально для финансовых данных, была подвергнута 18-дневному CPT с использованием набора данных, содержащего 24 миллиарда токенов. Кроме того, CPT подвержен катастрофическому забыванию. Поэтому мы не рекомендуем использовать непрерывное предварительное обучение как эффективный подход к адаптации LLM для команд с ограниченными ресурсами.
В заключение следует отметить, что использование алгоритмов самоконтроля и немаркированных наборов данных для адаптации LLM (как это делается при предварительном и непрерывном предварительном обучении) требует больших ресурсов и затрат и не рекомендуется в качестве жизнеспособного подхода.
✅ Полная тонкая настройка и параметрическая эффективная тонкая настройка (PEFT)
Тонкая настройка на небольших наборах данных с метками - более экономичный подход, чем предварительное обучение на наборах данных без меток. Адаптируя предварительно обученную модель к конкретной задаче, можно добиться наилучших результатов в широком спектре приложений и специализаций (например, юридических, медицинских или финансовых).
Тонкая настройка, особенно параметрическая эффективная тонкая настройка (PEFT), требует лишь малой доли вычислительных ресурсов, необходимых для предварительного/непрерывного предварительного обучения. Таким образом, это приемлемый метод адаптации LLM для команд с ограниченными ресурсами. В этой серииЧасть 3В ней мы подробно рассказываем о тонкой настройке, включая полную тонкую настройку, PEFT и практическое руководство по ее выполнению.
✅ Извлечение дополненного поколения (RAG)
RAG - еще один популярный метод адаптации LLM. Если вашему приложению необходимо извлекать информацию из динамической базы знаний (например, боту для викторины), RAG может стать хорошим решением. Сложность системы на основе RAG заключается в основном в реализации поискового механизма. Стоимость аргументации в таких системах может быть выше, поскольку подсказки включают в себя извлеченные документы, а большинство провайдеров используют модель на основе маркеров. В этой серииЧасть 2в которой мы обсуждаем RAG в более широком смысле и сравниваем его с тонкой настройкой.
✅ Контекстное обучение (ICL)
Это наиболее экономичный способ адаптации LLM. ICL не требует дополнительных обучающих данных или вычислительных ресурсов, что делает его экономически эффективным подходом. Однако, как и в случае с RAG, стоимость и задержка вывода могут увеличиться из-за обработки большего количества лексем в момент вывода.
резюме
Создание системы на основе LLM - это итеративный процесс. Мы рекомендуем начать с простого подхода и постепенно повышать сложность, пока не достигнете своей цели. Приведенная выше блок-схема описывает этот итерационный процесс и обеспечивает прочную основу для вашей стратегии адаптации LLM.
благодарственная записка
Мы благодарим Сураджа Субраманиана и Варуна Вонтимитту за конструктивные замечания по организации и подготовке этой статьи.
Часть II: Настраивать или не настраивать
Это вторая из серии записей в блоге об адаптации больших языковых моделей (LLM) с открытым исходным кодом. В этом посте мы обсудим следующий вопрос: "Когда следует проводить тонкую настройку, а когда стоит обратить внимание на другие технологии?"
вводная
До появления больших языковых моделей тонкая настройка обычно использовалась для моделей меньшего масштаба (100-300 миллионов параметров). Наиболее продвинутые доменные приложения были построены с использованием контролируемой тонкой настройки (SFT) - то есть предварительно обученные модели обучались на аннотированных данных из собственного домена и последующих задач. Однако с появлением больших моделей (> 1 млрд параметров) вопрос тонкой настройки становится более тонким. Самое главное, что большие модели требуют больше ресурсов и коммерческого оборудования для тонкой настройки. В таблице 1 ниже приведен список пиковых значений использования памяти GPU для тонкой настройки моделей Llama 2 7B и Llama 2 13B в трех сценариях. Вы можете заметить, что такие модели, как QLoRA Такие алгоритмы облегчают тонкую настройку больших моделей с использованием ограниченных ресурсов. Например, в таблице 1 показан пиковый объем памяти GPU для трех сценариев тонкой настройки (полная тонкая настройка, LoRA и QLoRA) на Llama 2 7B. Аналогичное сокращение памяти в результате параметрической эффективной тонкой настройки (PEFT) или квантования также показано на Llama 1. отчетность Прием. Помимо вычислительных ресурсов, катастрофическое забывание (подробнее см. в этой серии Часть I) является общим недостатком точной настройки всех параметров. Метод PEFT направлен на устранение этих недостатков путем обучения небольшого числа параметров.
方法-1") Таблица 1: Память (ГБ) на LLama 2 7B для различных методов тонкой настройки (источник (информации и т.д.)Для количественной оценки QLoRA используется 4-битное значение NormalFloat.
Таблица 1: Память (ГБ) на LLama 2 7B для различных методов тонкой настройки (источник (информации и т.д.)Для количественной оценки QLoRA используется 4-битное значение NormalFloat.
Прототипы, которые могут выиграть от доработки
Мы определили следующие сценарии как распространенные варианты использования, которые могут выиграть от доработки:
- Настройка тона, стиля и формата: Для конкретных случаев использования может потребоваться большая языковая модель, отражающая особенности личности или обслуживающая определенную аудиторию. Тонкая настройка модели biglanguage с помощью пользовательского набора данных позволит сформировать ответы чатбота в соответствии с конкретными требованиями или предполагаемым опытом аудитории. Мы также можем захотеть структурировать выходные данные определенным образом - например, в формате JSON, YAML или Markdown.
- Повышайте точность и справляйтесь с нестандартными ситуациями: Тонкая настройка может быть использована для исправления иллюзий или ошибок, которые трудно исправить с помощью разработки подсказок и контекстного обучения. Она также может повысить способность модели выполнять новые навыки или задачи, которые трудно выразить в подсказках. Этот процесс может помочь исправить неудачи, когда модели не могут следовать сложным подсказкам, и повысить их надежность в получении желаемого результата. Мы приводим два примера:
- Точность Phi-2 при анализе настроений финансовых данных Модернизирован с 34% до 85%.
- ChatGPT Точность анализа настроения комментариев на Reddit Увеличение на 25 процентных пунктов (от 48% до 73%), используя всего 100 примеров.
Как правило, при небольших начальных значениях точности (< 50%) тонкая настройка на нескольких сотнях примеров позволяет добиться значительного улучшения.
- Решить проблемы недопредставленности: Хотя большие языковые модели обучаются на больших объемах данных общего назначения, они не всегда хорошо разбираются в тонкостях жаргона, терминологии и идиосинкразии каждой нишевой области. В таких разнообразных областях, как юриспруденция, здравоохранение или финансы, тонкая настройка моделей помогает повысить точность решения последующих задач. Мы приводим два примера:
- Как это труды Было отмечено, что медицинская карта пациента содержит очень конфиденциальные данные, которые обычно не попадают в открытый доступ. Поэтому системы, основанные на больших языковых моделях для обобщения медицинских карт, нуждаются в тонкой настройке.
- Тонкая настройка недопредставленных языков, таких как индийские языки, с помощью методов PEFT Помогает выполнять все задания.
- Снижение затрат: Тонкая настройка позволяет перенести навыки из больших моделей, таких как Llama 2 70B/GPT-4, в меньшие модели, такие как Llama 2 7B, что позволяет снизить стоимость и время ожидания без ущерба для качества. Кроме того, тонкая настройка снижает потребность в длинных или специфических подсказках (например, используемых при разработке подсказок), тем самым экономя жетоны и еще больше снижая затраты. Например.эта статья Показано, как можно добиться экономии средств за счет усовершенствования более дорогой модели GPT-4 для точной настройки судьи GPT-3.5.
- Новые задачи/возможности: Часто новые возможности достигаются за счет тонкой настройки. Мы приводим три примера:
- Тонкая настройка больших языковых моделей для Более эффективное использование контекста конкретного поисковика Или вообще игнорировать его
- Тонкая настройка больших языковых моделей Судьи для оценки других больших языковых моделейОценка показателей, таких как подлинность, соответствие или полезность, является ключевым элементом в разработке и реализации программы.
- Тонкая настройка больших языковых моделей для Добавить контекстное окно
Сравнение с технологиями адаптации в других областях
Тонкая настройка по сравнению с контекстным (менее выборочным) обучением
Контекстное обучение (ICL) - это мощный способ повысить производительность систем, основанных на больших языковых моделях. Учитывая его простоту, вам следует попробовать ICL, прежде чем приступать к тонкой настройке. Кроме того, эксперименты с ICL помогут вам оценить, улучшает ли тонкая настройка производительность последующих задач. При использовании ICL обычно учитываются следующие моменты:
- С увеличением количества примеров, которые необходимо показать, возрастает стоимость и время вывода.
- С увеличением количества примеров большая языковая модель Часто упускают из виду некоторые из. Это означает, что вам может понадобиться система на основе RAG, которая находит наиболее релевантные примеры на основе исходных данных.
- Большие языковые модели могут выплевывать знания, предоставленные им в качестве примеров. Эта проблема также существует при тонкой настройке.
тонкая настройка против. и РАГ
По общему мнению, когда базовая производительность большой языковой модели неудовлетворительна, можно "начать с RAG, оценить ее производительность и перейти к тонкой настройке, если она окажется недостаточной", или "RAG может иметь преимущества" перед тонкой настройкой (источник (информации и т.д.)). Однако мы считаем, что эта парадигма является чрезмерным упрощением, поскольку во многих случаях RAG не только не является альтернативой тонкой настройке, но скорее дополняет ее. В зависимости от особенностей проблемы следует попробовать один или, возможно, оба подхода. Принятие эта статья Вот несколько вопросов, которые вы можете задать, чтобы определить, подходит ли для вашей проблемы тонкая настройка или RAG (а возможно, и то, и другое):
- Нужны ли вашему приложению внешние знания? Тонкая настройка обычно не относится к внедрению новых знаний.
- Вашему приложению требуется особый тон/поведение/словарь или стиль? Для таких требований обычно подходит тонкая настройка.
- Насколько ваше приложение терпимо к галлюцинациям? В приложениях, где подавление фальши и фантазийных измышлений является критически важным, система RAG предоставляет встроенные механизмы для минимизации галлюцинаций.
- Сколько имеется помеченных данных для обучения?
- Насколько статичны/динамичны данные? Если задача требует доступа к динамическому корпусу данных, то тонкая настройка может оказаться неподходящим подходом, поскольку знания о большой языковой модели быстро устаревают.
- Насколько прозрачность/интерпретируемость необходима для больших приложений языкового моделирования? RAG может в основном предоставлять ссылки, которые полезны для интерпретации больших результатов языкового моделирования.
- Стоимость и сложность: есть ли у команды опыт создания поисковых систем или опыт их тонкой настройки?
- Насколько разнообразны задачи в вашем приложении?
В большинстве случаев наилучшие результаты дает гибридное решение, включающее тонкую настройку и RAG, и тогда встает вопрос о стоимости, времени и дополнительной выгоде от одновременного применения обоих методов. Обратитесь к приведенным выше вопросам, чтобы принять решение о необходимости RAG и/или тонкой настройки, и проведите внутренние эксперименты, проанализировав ошибки, чтобы понять возможный прирост метрик. Наконец, для изучения тонкой настройки необходима надежная стратегия сбора и улучшения данных, которую мы рекомендуем использовать в качестве предварительного условия для начала тонкой настройки.
благодарственная записка
Мы благодарим Сураджа Субраманиана и Варуна Вонтимитту за конструктивные замечания по организации и подготовке этой статьи.
Часть III: Как настроить: фокусировка на эффективных наборах данных
方法-1")
Это третья статья из серии блогов об адаптации больших языковых моделей (LLM) с открытым исходным кодом. В этой статье мы рассмотрим некоторые правила составления качественных обучающих наборов данных.
вводная
Тонкая настройка LLM - это сочетание искусства и науки, и лучшие практики в этой области еще только формируются. В этой статье блога мы сосредоточимся на переменных дизайна тонкой настройки и дадим рекомендации по лучшей практике тонкой настройки моделей в условиях ограниченных ресурсов. Мы предлагаем следующую информацию в качестве отправной точки для разработки стратегии экспериментов по тонкой настройке.
Полная точная настройка по сравнению с параметрической эффективной точной настройкой (PEFT)
Весь объем тонкой настройки и PEFT в академия ответить пением практическое применение Все они, как было показано, улучшают производительность последующих задач при применении в новых областях. Выбор одного из них в конечном итоге зависит от доступных вычислительных ресурсов (в смысле часов работы GPU и памяти GPU), производительности на задачах, отличных от целевой задачи (компромисс "научиться-забыть"), и стоимости ручного аннотирования.
Полнообъемная тонкая настройка, скорее всего, будет страдать от двух проблем:крушение модели ответить пением катаклизмическое забытье. Коллапс модели - это когда выход модели сходится к конечному набору выходов, а хвосты исходного распределения содержания исчезают. Катастрофическое забывание, как в этой серии Часть I Обсуждаемые вопросы могут привести к тому, что модель потеряет свою силу. Некоторые первые эмпирические исследования показали, чтоПо сравнению с техникой PEFT, техника тонкой настройки полного объема более подвержена этим проблемамХотя необходимы дополнительные исследования.
Метод PEFT может быть разработан как естественный регуляризатор для тонкой настройки. PEFT обычно требует относительно мало вычислительных ресурсов для обучения последующих моделей, и его легче использовать в сценариях с ограниченными ресурсами и ограниченным объемом наборов данных. В некоторых случаях полная тонкая настройка лучше справляется с конкретными задачами, но обычно ценой утраты некоторых возможностей исходной модели. Этот компромисс "научиться забывать" между производительностью на конкретной задаче и производительностью на других задачах легче использовать в Эта статья. Подробное сравнение LoRA и полной тонкой настройки представлено в статье.
Учитывая ограниченность ресурсов, метод PEFT может обеспечить лучшее соотношение производительности и затрат, чем полная тонкая настройка. Если производительность нисходящего потока является критически важной в условиях ограниченных ресурсов, наиболее эффективной будет полнообъемная тонкая настройка. В любом случае для создания высококачественных наборов данных важно придерживаться следующих ключевых принципов.
Свертка наборов данных
В экспериментах по тонкой настройке, проводимых в литературе, наборы данных имеют решающее значение для получения преимуществ тонкой настройки. Здесь больше нюансов, чем просто "лучшее качество и больше примеров", и вы можете разумно инвестировать в сбор наборов данных, чтобы улучшить производительность в экспериментах по тонкой настройке с ограниченными ресурсами.
Качество/количество данных
- Качество имеет решающее значение: Общая тенденция заключается в том, что качество важнее количества, т. е. лучше иметь небольшой набор высококачественных данных, чем большой набор низкокачественных данных. Ключевыми принципами качества являются последовательная маркировка, отсутствие ошибок, неправильно маркированных данных, зашумленных входов/выходов и репрезентативное распределение по сравнению с целым. При точной настройкеНабор данных LIMA из нескольких тысяч тщательно подобранных примеров показал лучшие результаты, чем набор данных Alpaca, состоящий из 50 тысяч машин.Документация по тонкой настройке OpenAI Предполагается, что даже набор данных из 50-100 примеров может оказать влияние.
- Более сложные языковые задачи требуют большего количества данных: Относительно сложные задачи, такие как генерация и обобщение текста, труднее поддаются тонкой настройке и требуют больше данных, чем простые задачи, такие как классификация и извлечение сущностей. Слово "сложнее" в данном контексте может означать самые разные вещи: большее количество лексем в выходных данных, требуемые человеческие способности более высокого порядка, множество правильных ответов.
- Эффективный и качественный сбор данных: В связи с высокой стоимостью сбора данных, для повышения эффективности выборки и снижения затрат рекомендуется использовать следующие стратегии
- Наблюдайте за примерами неудач: изучите примеры неудач предыдущих возможностей ML и добавьте примеры, учитывающие эти модели неудач.
- Человеко-машинное сотрудничество: это более дешевый способ масштабирования аннотирования данных. Мы используем LLM для автоматизации создания базовых ответов, которые человеческие аннотаторы могут аннотировать за меньшее время.
Разнообразие данных
Проще говоря, если вы перетренируете модель на определенном типе ответа, она будет предвзято давать именно этот ответ, а то и самый подходящий. Правило здесь такое: убедитесь, что обучающие данные максимально отражают то, как модель должна вести себя в реальном мире.
- Повторяйте: был отвергнут открытия является причиной деградации модели при тонкой настройке и предварительном обучении. Достижение разнообразия за счет дедупликации обычно улучшает показатели производительности.
- Входное разнообразие: Увеличивайте разнообразие, перефразируя исходные данные. В Тонкая настройка SQLCoder2 Команда переформулировала обычный текст, сопровождающий SQL-запросы, чтобы внести синтаксическое и семантическое разнообразие. Аналогичным образомОбратный перевод инструкций использовался для написанного вручную текста, задавая LLM вопрос "На какой вопрос это может быть ответом?". для создания набора данных вопросов и ответов.
- Разнообразие наборов данных: Было показано, что при тонкой настройке для решения более общих задач - например, многоязычной адаптации - использование различных наборов данных улучшает компромисс между забыванием первоначальных возможностей модели и обучением новым. Использование различных языков, таких как Хинди (язык) ответить пением Австронезийский (язык) Модель тонкой настройки использует богатый набор данных по конкретным языкам, а также другие наборы данных по тонкой настройке команд, такие как FLAN, иАльпака, Долли и др. для внесения разнообразия.
- Стандартизированный выход: Удаление пробельных символов из вывода и другие приемы форматирования оказались полезными.SQLCoder2 Удаление пробельных символов из генерируемого SQL позволяет модели сосредоточиться на изучении важных концепций SQL, а не на таких трюках, как пробелы и отступы. Если вам нужен особый тон в ответе". Чатбот службы поддержки..." , то добавьте их в набор данных для каждого примера.
Конвейер данных на основе LLM
Чтобы собрать высококачественные и разнообразные наборы данных, конвейеры обработки данных часто используют LLM для снижения затрат на аннотирование. На практике встречаются следующие приемы:
- Оценка: Обучите модель на высококачественном наборе данных и используйте ее для аннотирования большего набора данных, чтобы отфильтровать высококачественные примеры.
- Сгенерировать: Заправьте LLM примерами высокого качества и попросите сгенерировать аналогичные примеры высокого качества.Лучшие практики для синтетических наборов данных начинает обретать форму.
- Совместная работа человека и компьютера: Используйте LLM для создания начального набора выходных данных и позвольте людям улучшить их качество путем редактирования или выбора предпочтений.
Отладка вашего набора данных
- Оцените свой набор данных на предмет плохих результатов: Если модель все еще не справляется с определенными задачами, добавьте обучающие примеры, которые покажут модели, как правильно работать с этими задачами. Если у вашей модели есть проблемы с синтаксисом, логикой или стилем, проверьте данные на наличие таких же проблем. Например, если модель теперь говорит "Я организую для вас эту встречу" (когда она не должна этого делать), посмотрите, не учат ли существующие примеры модель, что она может делать что-то новое, чего она на самом деле делать не может.
- Дважды проверьте баланс положительных/отрицательных категорий: Вы можете получить слишком много отказов, если ответ помощника 60% в данных говорит "Я не могу ответить на этот вопрос", но только ответ 5% должен говорить это при рассуждениях.
- Всесторонность и последовательность: Убедитесь, что обучающие примеры содержат всю информацию, необходимую для ответа. Если мы хотим, чтобы модель похвалила пользователя на основе его личных характеристик, а обучающие примеры содержат похвалу помощника за характеристики, которые не фигурировали в предыдущем диалоге, модель может научиться искажать информацию. Убедитесь, что все обучающие примеры имеют тот же формат, который ожидается при рассуждениях. Проверьте согласованность обучающих примеров. Если обучающие данные создавались несколькими людьми, производительность модели может быть ограничена уровнем межличностной согласованности. Например, в задаче извлечения текста модель может не справиться с задачей, если люди согласны только с извлеченными сегментами 70%.
вынести вердикт
Тонкая настройка - ключевой аспект в разработке большой языковой модели, требующий тонкого баланса между искусством и наукой. Качество и курирование набора данных играет важную роль в успехе тонкой настройки, аНебольшие тонко настроенные модели больших языков, как правило, превосходят более крупные модели при решении конкретных задач. После принятия решения о тонкой настройке Руководство по тонкой настройке ламы обеспечивает надежную отправную точку. Собственный характер портфеля наборов данных для тонкой настройки препятствует обмену передовым опытом и открытому доступу к исходному коду. По мере развития этой области мы ожидаем появления общих лучших практик, сохраняя при этом творческий подход и адаптивность тонкой настройки.
благодарственная записка
Мы благодарим Сураджа Субраманиана и Варуна Вонтимитту за конструктивные замечания по организации и подготовке этой статьи.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...