Logics-Parsing - модель разбора документов с открытым исходным кодом на Ali

Что такое логический разбор
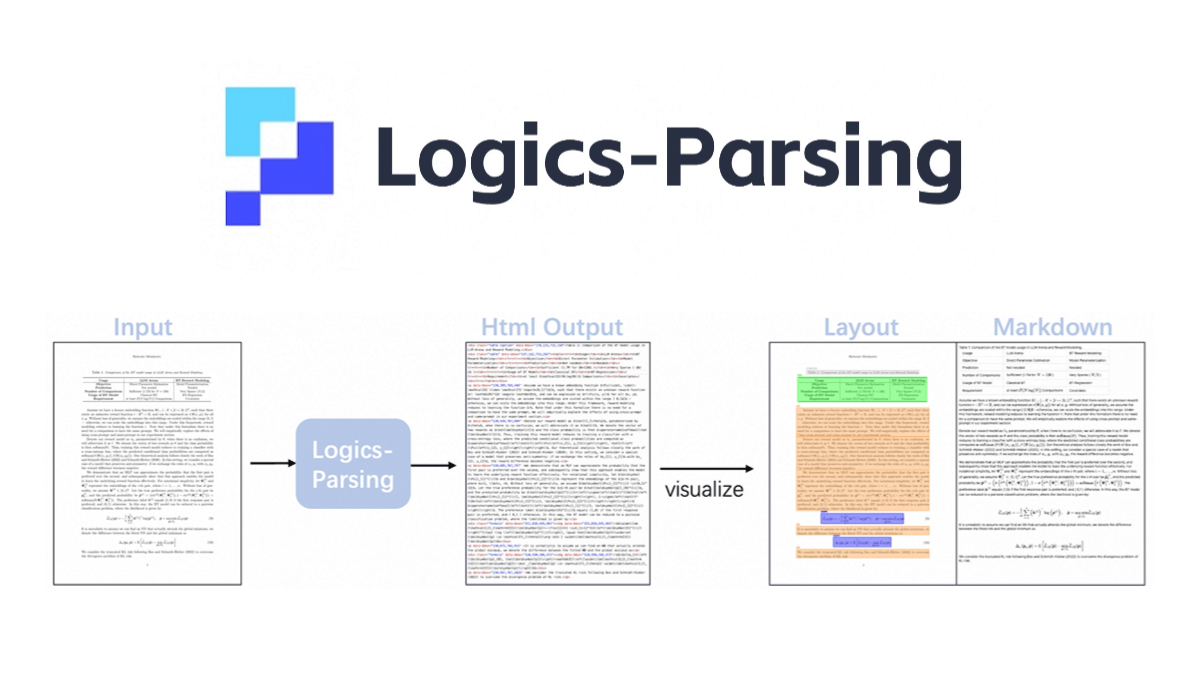
Logics-Parsing - это модель сквозного разбора документов с открытым исходным кодом, основанная на Qwen2.5-VL-7B. Оптимизация анализа макета документа и вывода порядка чтения с помощью обучения с усилением, PDF-изображения могут быть преобразованы в структурированный HTML-вывод, поддержка различных типов контента, включая обычный текст, математические формулы, таблицы, химические формулы и рукописные китайские символы. Модель обучается в два этапа: первый этап - контролируемая тонкая настройка, чтобы научиться генерировать структурированный вывод; второй этап - ориентированное на макет обучение с подкреплением, чтобы оптимизировать точность текста, расположение макета и порядок чтения. Он демонстрирует хорошие результаты в бенчмарке LogicsParsingBench, особенно превосходя другие методы в разборе обычного текста, химической структуры и рукописного контента.
Особенности логического разбора
- возможность комплексного решения проблем: Генерируйте структурированный HTML-вывод непосредственно из изображений документов без сложных многоступенчатых конвейеров.
- Расширенное распознавание контента: Точное распознавание сложных материалов, таких как математические формулы, химические структуры и рукописные китайские символы.
- Структурированный вывод: Созданный HTML сохраняет логическую структуру документа, с подробными тегами и координатами для каждого блока содержимого.
- Автоматическое удаление неактуальных элементов: Автоматически отфильтруйте неактуальные элементы, такие как верхние и нижние колонтитулы, чтобы сосредоточиться на основном содержимом.
- Оптимизация обучения: Оптимизация анализа расположения и порядка чтения для повышения точности синтаксического анализа путем интенсивного изучения.
- Высокая производительность: Превосходит другие существующие методы на широком спектре сложных типов документов.
- Простое развертывание и обоснование: После установки весовые коэффициенты модели можно быстро загрузить из командной строки и выполнить операции вывода.
Основные преимущества Logics-Parsing
- высокая точность: Отличная производительность и высокая точность при работе с широким спектром типов документов и сложным содержимым.
- комплексное решение: Упорядочение процесса путем создания структурированного вывода непосредственно из изображений документов без необходимости многоступенчатого конвейера.
- Способность работать со сложным контентом: Способность точно распознавать и разбирать сложные материалы, такие как математические формулы, химические структуры и рукописный китайский язык.
- Структурированный вывод: В результате HTML-вывод сохраняет логическую структуру документа для последующей обработки и применения.
- Автоматическая фильтрация неактуальных элементов: Автоматически определяет и удаляет лишнее содержимое, такое как верхние и нижние колонтитулы, чтобы сосредоточиться на основном сообщении.
- Оптимизация обучения: Оптимизация анализа макета и порядка чтения с помощью обучения с усилением для повышения общей производительности.
Что является официальным сайтом компании Logics-Parsing?
- Репозиторий Github:: https://github.com/alibaba/Logics-Parsing
- Библиотека моделей HuggingFace:: https://huggingface.co/Logics-MLLM/Logics-Parsing
- Технический документ arXiv:: https://arxiv.org/pdf/2509.19760
Для кого предназначен Logics-Parsing?
- (научный) исследователь: Используется для анализа академических статей и научных отчетов с целью извлечения ключевой информации.
- педагог: Работа с учебными материалами, экзаменационными работами, рукописными заметками и т.д. для поддержки преподавания и обучения.
- Корпоративный аналитик: Разбор деловых документов, отчетов, извлечение данных и информации.
- специалист по анализу данных: Работа с большими объемами данных о документах для поиска и анализа данных.
- Инженер по обработке документов: Разработка системы обработки документов для повышения уровня автоматизации.
- школьники: Assisted learning, разбор учебников и конспектов для повышения эффективности обучения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...