LocalPdfChatRAG: интеллектуальный инструмент чата для поддержки локальных вопросов и ответов по PDF-документам из нескольких источников

Общее введение
МестныйPdfЧатRAG - это проект с открытым исходным кодом, целью которого является создание интеллектуального чата путем объединения локальных PDF-документов с моделями Retrieval Augmented Generation (RAG). Проект позволяет пользователям загружать PDF-документы, и с помощью вопросов на естественном языке получать соответствующую информацию из документа.PdfЧатRAG использует передовую технологию обработки естественного языка, чтобы обеспечить эффективный и точный поиск содержимого документов и услуги Q&A для широкого спектра сценариев, включая академические исследования и корпоративный документооборот.

Список функций
- Загрузка PDF-документов: Пользователи могут загружать локальные PDF-документы, а система будет автоматически анализировать и извлекать текстовое содержимое.
- викторина на естественном языке: Пользователи могут задавать вопросы на естественном языке, а система будет извлекать соответствующую информацию из загруженного PDF-документа и генерировать ответы.
- интеграция информации из нескольких источников: Поддержка объединения локальных PDF-документов и результатов веб-поиска для получения более полных ответов.
- векторизацияВекторизация текста с использованием моделей встраивания для повышения точности поиска и вопросов и ответов.
- Конфигурация переменной окружения: Поддерживает настройку ключей API и других параметров через файлы .env для пользовательских настроек.
Использование помощи
Процесс установки
- проект клонирования: Выполните следующую команду в терминале, чтобы клонировать код проекта:
git clone https://github.com/weiwill88/Local_Pdf_Chat_RAG.git
- Установка зависимостей: Перейдите в каталог проекта и установите необходимые зависимости:
cd Local_Pdf_Chat_RAG
pip install -r requirements.txt
- Настройка переменных среды: Создать
.envфайл и добавьте следующее:
SERPAPI_KEY=your_serpapi_key
главнокомандующий (военный)your_serpapi_keyЗамените его своим ключом SerpAPI.
Процесс использования
- Начальные услуги: Выполните следующую команду в терминале, чтобы запустить службу:
python rag_demo.py
- Загрузка документов в формате PDF: Откройте браузер для доступа к локальному адресу службы и загрузите PDF-документ, который необходимо обработать.
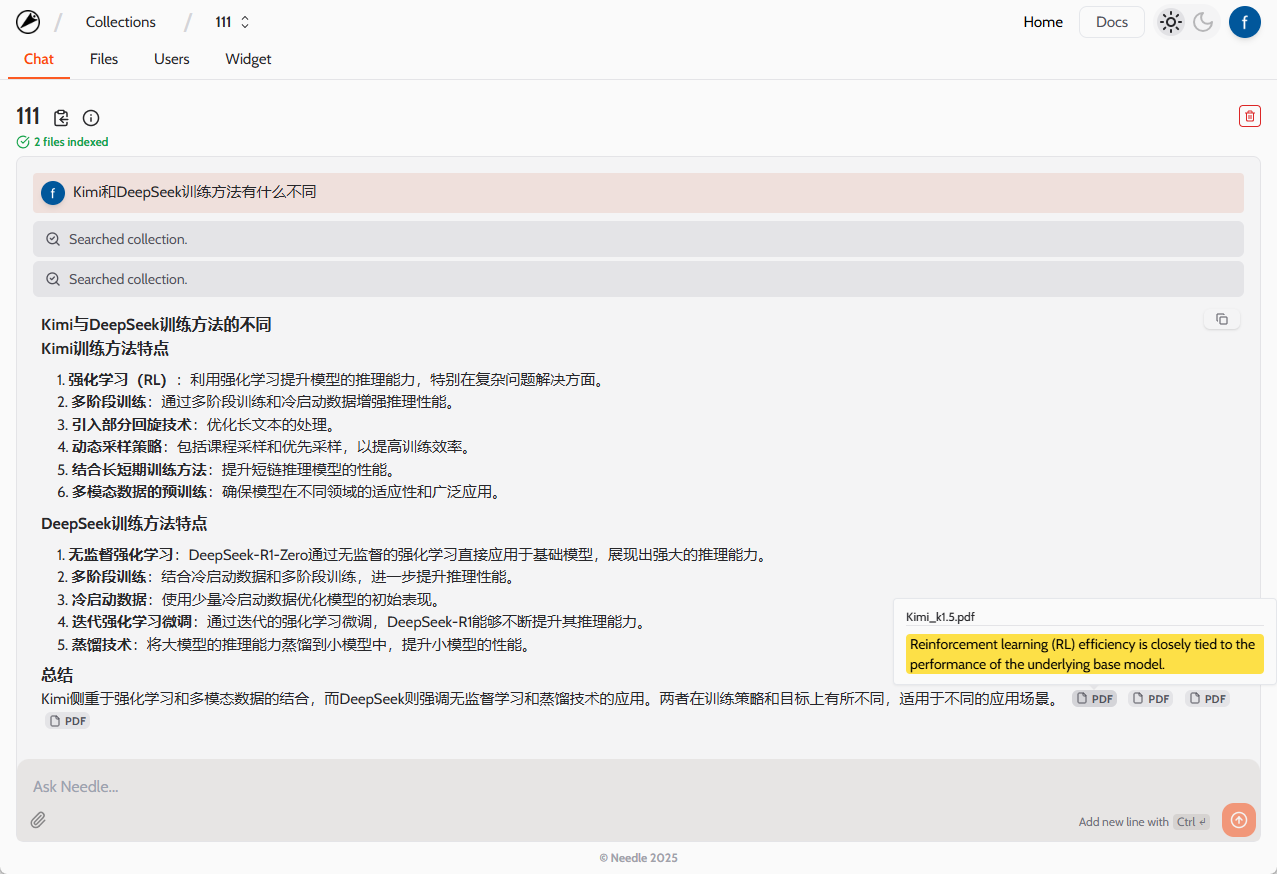
- задавать вопросы: Введите свой вопрос в поле ввода, и система извлечет соответствующую информацию из загруженного PDF-документа и сгенерирует ответ.
Детальное управление функциями
- Загрузка PDF-документов: Нажмите кнопку загрузки, выберите локальный PDF-файл, система автоматически проанализирует содержимое документа и сохранит его в базе данных.
- викторина на естественном языке: Введите вопрос в поле ввода, например "Каковы основные выводы этой статьи?". Система извлечет соответствующие абзацы из PDF-документа и сгенерирует ответ.
- интеграция информации из нескольких источников: Система будет не только получать информацию из локальных PDF-документов, но и осуществлять поиск в Интернете с помощью SerpAPI, объединяя несколько источников информации для предоставления более полных ответов.
- векторизация: Система использует модель SentenceTransformer для векторизации текста, чтобы обеспечить высокую точность поиска и вопросов и ответов.
- Конфигурация переменной окружения: Пользователи могут изменять параметры в файле .env для настройки ключей API, поисковых систем и т. д. в соответствии с индивидуальными потребностями.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...