
LLaVA-OneVision-1.5 - бесплатная мультимодальная модель с открытым исходным кодом для высокопроизводительного мультимодального понимания

Что такое LLaVA-OneVision-1.5?
LLaVA-OneVision-1.5 - это мультимодальная модель с открытым исходным кодом от команды EvolvingLMMS-Lab, которая была предварительно обучена за 4 дня на 128 графических процессорах A800 при общей стоимости ~US$16K с использованием шкалы параметров 8B с помощью компактного трехэтапного процесса обучения (выравнивание языка и изображения, концептуальное выравнивание и введение знаний, а также тонкая настройка инструкций). Основные инновации включают поддержку визуальным кодером RICE-ViT нативного разрешения и тонкого семантического моделирования на уровне регионов, а также оптимизацию использования данных с помощью стратегии "балансировки концепций". Она превосходит Qwen2.5-VL в OCR, понимании документов и других задачах и впервые получила полный открытый исходный код (включая данные, инструментарий обучения и сценарии оценки), что значительно снижает порог для воспроизведения мультимодальных моделей. Код модели был опубликован на GitHub, что способствует ее дешевому воспроизведению и вторичной разработке сообществом.
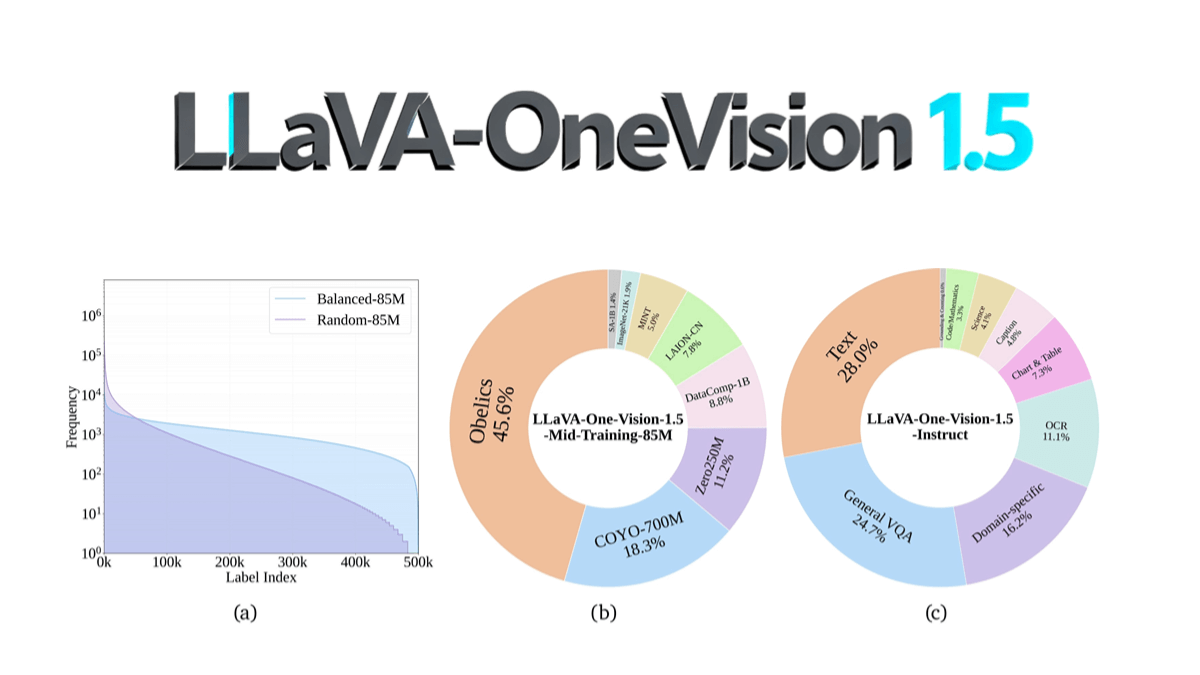
Особенности LLaVA-OneVision-1.5
- Высокопроизводительное мультимодальное понимание: Эффективно обрабатывает и понимает изображения и текстовую информацию для создания точных описаний и ответов для широкого спектра сложных сценариев.
- Эффективное обучение и низкая стоимость: Использование оптимизированных стратегий обучения и методов упаковки данных позволяет значительно снизить затраты на обучение при сохранении высокой производительности.
- Строгое соблюдение субординации: Может точно понимать и выполнять команды пользователя, обладает хорошими возможностями обобщения задач и может применяться для решения широкого спектра мультимодальных задач.
- Высококачественные данные, основанные на данныхУбедитесь, что модель приобретает богатые знания и семантическую информацию благодаря тщательно разработанным наборам данных для предварительного обучения и точной настройки.
- Поддержка гибкого разрешения входного сигналаЭнкодер технического зрения поддерживает переменное входное разрешение, что устраняет необходимость в точной настройке разрешения и адаптируется к различным требованиям к размеру изображения.
- Региональные механизмы перцептивного внимания: Улучшение семантического понимания локальных областей на изображении с помощью механизма внимания с учетом региона для улучшения способности модели улавливать детали.
- Поддержка нескольких языковПоддержка многоязычного ввода и вывода с возможностью межъязыкового понимания и генерации для адаптации к потребностям интернационализированных приложений.
- Прозрачная и открытая структура: Предоставление полных ресурсов кода, данных и моделей для обеспечения недорогого воспроизведения и верифицируемых расширений для сообщества, облегчающих академические и промышленные приложения.
- умение определять длинный хвостЭффективная идентификация и понимание категорий или понятий, которые встречаются в данных реже, также возможны, что улучшает обобщающую способность модели.
- Функция кросс-модального поискаПоддержка текстового запроса изображения или текстового запроса изображения для достижения эффективного кросс-модального поиска информации.
Основные преимущества LLaVA-OneVision-1.5
- высокая производительность: Хорошо справляется с мультимодальными задачами, эффективно обрабатывая изображения и текстовую информацию для получения высококачественного результата.
- недорого: Значительное снижение затрат на обучение и повышение экономической эффективности благодаря оптимизации стратегий обучения и методов упаковки данных.
- высокая воспроизводимостьПредоставление полного кода, данных и обучающих скриптов гарантирует, что сообщество сможет воспроизвести и проверить работу модели при небольших затратах.
- Эффективное обучениеДля повышения эффективности обучения и снижения потерь вычислительных ресурсов используются методы параллельной упаковки данных в автономном режиме и гибридные параллельные методы.
- Высококачественные данные: Для того чтобы модель усваивала богатую семантическую информацию, создается крупномасштабный и высококачественный набор данных для предварительного обучения и тонкой настройки инструкций.
- Гибкая поддержка вводаЭнкодер технического зрения поддерживает переменное входное разрешение, что устраняет необходимость в точной настройке разрешения и адаптируется к различным требованиям к размеру изображения.
- Возможность осознания территории: Улучшенное семантическое понимание локальных областей на изображении и улучшенный захват деталей с помощью механизма внимания с учетом региона.
Какой официальный сайт у LLaVA-OneVision-1.5?
- Адрес Github:: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- Библиотека моделей HuggingFace:: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- Технический документ arXiv:: https://arxiv.org/pdf/2509.23661
- Демонстрация опыта работы в режиме онлайн:: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
Люди, для которых подходит LLaVA-OneVision-1.5
- научный сотрудникУченые, работающие в области мультимодального обучения, компьютерного зрения и обработки естественного языка, смогут использовать эти модели для передовых исследований и разработки алгоритмов.
- разработчики: Инженеры-программисты и разработчики приложений могут интегрировать LLaVA-OneVision-1.5 в различные приложения для создания интеллектуального обслуживания клиентов, рекомендаций по содержанию и т. д.
- педагог: Преподаватели и педагоги-технологи, которые могут использовать его в образовании для помощи в преподавании и обучении, например, для интерпретации изображений и создания мультимедийного контента.
- Медицинские работники: Врачи и медицинские исследователи, могут быть использованы для анализа медицинских изображений и вспомогательной диагностики для повышения эффективности и точности медицинской помощи.
- создатель контента: Писатели, дизайнеры и медиапродюсеры используют модель для создания креативного контента, копий и описаний изображений, чтобы повысить эффективность творческой деятельности.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...