LlamaEdge: самый быстрый способ запускать и настраивать LLM локально!

Общее введение
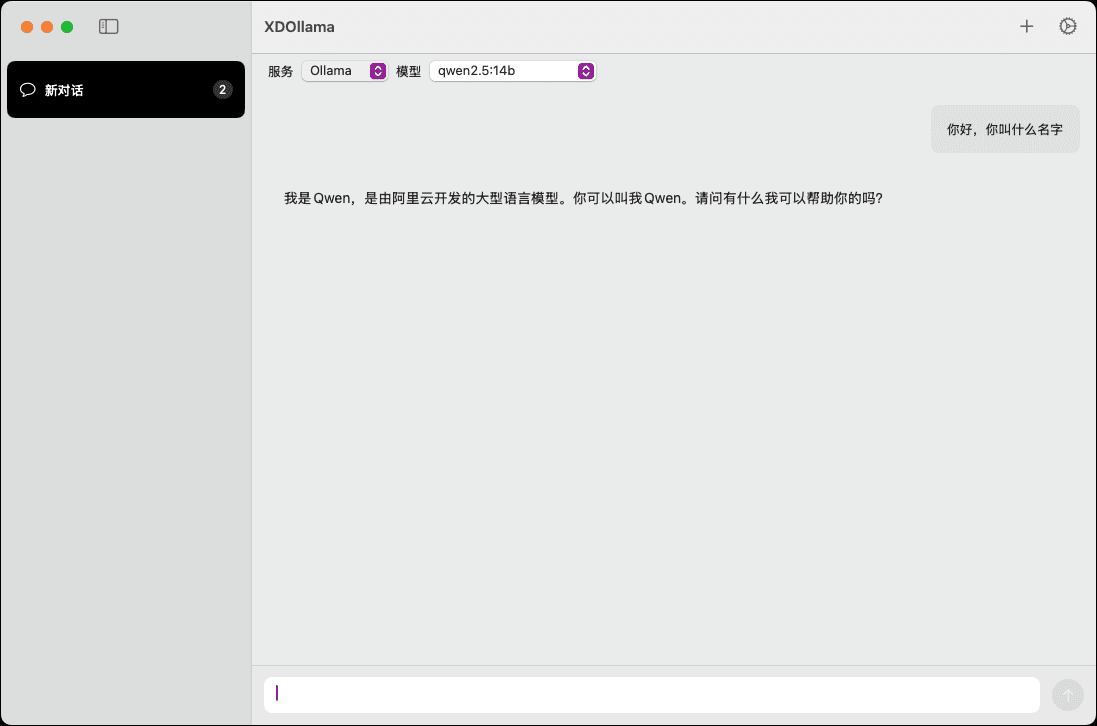
LlamaEdge - это проект с открытым исходным кодом, предназначенный для упрощения процесса запуска и тонкой настройки больших языковых моделей (LLM) на локальных или пограничных устройствах. Проект поддерживает семейство моделей Llama2 и предоставляет OpenAI-совместимые API-сервисы, которые позволяют пользователям легко создавать и запускать приложения для рассуждений на основе LLM. LlamaEdge использует технологические стеки Rust и Wasm, чтобы предоставить мощные альтернативы для рассуждений на основе ИИ. Пользователи могут быстро запустить модели с помощью простых операций командной строки, а также доработать и расширить их по мере необходимости.
Список функций
- Запуск LLM локально: Поддержка запуска моделей серии Llama2 на локальных или пограничных устройствах.
- Совместимые с OpenAI API-сервисы: Предоставляет совместимые с OpenAI API конечные точки сервисов, которые поддерживают чат, преобразование речи в текст, текст в речь, генерацию изображений и многое другое.
- Поддержка кросс-платформы: Поддерживает широкий спектр устройств на базе CPU и GPU и обеспечивает кроссплатформенность приложений Wasm.
- быстрый стартМодели могут быть быстро загружены и запущены с помощью простых операций командной строки.
- Тонкая настройка и расширение: Пользователи могут изменять и расширять исходный код по мере необходимости для удовлетворения конкретных потребностей.
- Документация и учебные пособия: Подробная официальная документация и учебные пособия помогут пользователям быстро освоиться.
Использование помощи
Процесс установки
- Установка WasmEdge: Для начала необходимо установить WasmEdge, что можно сделать с помощью следующей командной строки:
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash
- Скачать файлы модели LLM: В качестве примера возьмем модель Meta Llama 3.2 1B и загрузим ее с помощью следующей команды:
curl -LO https://huggingface.co/second-state/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q5_K_M.gguf
- Скачать приложение LlamaEdge CLI Chat App: Используйте следующую команду для загрузки кроссплатформенного приложения Wasm:
curl -LO https://github.com/second-state/LlamaEdge/releases/latest/download/llama-chat.wasm
- Запуск приложения для чата: Используйте следующую команду, чтобы пообщаться с LLM:
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Llama-3.2-1B-Instruct-Q5_K_M.gguf llama-chat.wasm -p llama-3-chat
Функции Поток операций
- Запуск службы API: Службу API можно запустить с помощью следующей команды:
wasmedge --dir .:. --env API_KEY=your_api_key llama-api-server.wasm --model-name llama-3.2-1B --prompt-template llama-chat --reverse-prompt "[INST]" --ctx-size 32000
- Взаимодействие с LLM с помощью веб-интерфейса: После запуска службы API вы можете взаимодействовать с локальным LLM через веб-интерфейс.
- Создание пользовательских служб APIПри необходимости можно создавать пользовательские конечные точки API-служб, такие как преобразование речи в текст, текст в речь, генерация изображений и т. д.
- Тонкая настройка и расширение: Пользователи могут изменять конфигурационные файлы и параметры в исходном коде для выполнения конкретных функциональных требований.
LlamaEdge Быстрое выполнение дистилляции на ноутбуке DeepSeek-R1
DeepSeek-R1 - это мощная и универсальная модель искусственного интеллекта, которая бросает вызов таким признанным игрокам, как OpenAI, благодаря своим расширенным возможностям вывода, экономичности и доступности с открытым исходным кодом. Несмотря на некоторые ограничения, инновационный подход и высокая производительность делают ее бесценным инструментом для разработчиков, исследователей и компаний. Для тех, кто заинтересован в изучении ее возможностей, модель и ее lite-версия доступны на таких платформах, как Hugging Face и GitHub.
Обученная китайской командой, работающей на GPU, она отлично справляется с математикой, кодированием и даже довольно сложными рассуждениями. Самое интересное, что это "легкая" модель, то есть она меньше и эффективнее, чем гигантская модель, на которой она основана. Это важно, потому что делает ее более практичной для использования и создания.

В этой статье мы представим
- Как запустить открытый исходный код на собственном устройстве DeepSeek моделирование
- Как создавать API-сервисы, совместимые с OpenAI, с помощью новейших моделей DeepSeek
Мы будем использовать LlamaEdge (стек технологий Rust + Wasm) для разработки и развертывания приложений для этой модели. Не нужно устанавливать сложные пакеты Python или инструментальные цепочки C++! Узнайте, почему мы выбрали именно эту технологию.
Запустите модель DeepSeek-R1-Distill-Llama-8B на собственном оборудовании!
Шаг 1: Установите WasmEge с помощью следующей командной строки.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1
Шаг 2: Загрузите квантованный файл модели DeepSeek-R1-Distill-Llama-8B-GGUF.
Это может занять некоторое время, поскольку размер модели составляет 5,73 ГБ.
curl -LO https://huggingface.co/second-state/DeepSeek-R1-Distill-Llama-8B-GGUF/resolve/main/DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf`
Шаг 3: Загрузите серверное приложение LlamaEdge API.
Это также кроссплатформенное, портативное приложение Wasm, которое работает на многих устройствах с CPU и GPU.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Шаг 4: Загрузите пользовательский интерфейс чатбота
для взаимодействия с моделью DeepSeek-R1-Distill-Llama-8B в браузере.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz tar xzf chatbot-ui.tar.gz rm chatbot-ui.tar.gz
Затем запустите сервер LlamaEdge API, используя следующую командную модель поведения.
wasmedge --dir .:. --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf \ llama-api-server.wasm \ --prompt-template llama-3-chat \ --ctx-size 8096
Затем откройте браузер и зайдите на сайт http://localhost:8080, чтобы начать общение! Или вы можете отправить запрос API к модели.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a helpful assistant."}, {"role":"user", "content": "What is the capital of France?"}], "model": "DeepSeek-R1-Distill-Llama-8B"}'
{"id":"chatcmpl-68158f69-8577-4da2-a24b-ae8614f88fea","object":"chat.completion","created":1737533170,"model":"default","choices":[{"index":0,"message":{"content":"The capital of France is Paris.\n</think>\n\nThe capital of France is Paris.<|end▁of▁sentence|>","role":"assistant"},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":34,"completion_tokens":18,"total_tokens":52}}
Создание OpenAI-совместимых API-сервисов для DeepSeek-R1-Distill-Llama-8B
LlamaEdge имеет небольшой вес и не требует запуска демона или процесса sudo. Его можно легко встроить в ваши собственные приложения! Благодаря поддержке чата и встраиванию моделей, LlamaEdge может стать альтернативой OpenAI API в приложениях на вашей локальной машине!
Далее мы покажем, как добавить новую функцию в DeepSeek-R1 модель и модель встраивания, чтобы запустить полноценный API-сервер. chat/completions ответить пением embeddings Конечные точки. В дополнение к шагам, описанным в предыдущем разделе, нам необходимо:
Шаг 5: Загрузите модель встраивания.
curl -LO https://huggingface.co/second-state/Nomic-embed-text-v1.5-Embedding-GGUF/resolve/main/nomic-embed-text-v1.5.f16.gguf
Затем мы можем запустить сервер LlamaEdge API с чатом и встраиваемыми моделями, используя следующую командную строку. Более подробные инструкции приведены в документации - Запуск службы LlamaEdge API.
wasmedge --dir .:. \ --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf \ --nn-preload embedding:GGML:AUTO:nomic-embed-text-v1.5.f16.gguf \ llama-api-server.wasm -p llama-3-chat,embedding \ --model-name DeepSeek-R1-Distill-Llama-8B,nomic-embed-text-v1.5.f16 \ --ctx-size 8192,8192 \ --batch-size 128,8192 \ --log-prompts --log-stat
Наконец, следуя этим инструкциям, вы можете интегрировать API-сервер LlamaEdge с другими фреймворками агентов в качестве замены OpenAI. В частности, замените API OpenAI следующими значениями в вашем приложении или конфигурации агента.
| Возможность настройки | (стоить |
|---|---|
| Базовый URL API | http://localhost:8080/v1 |
| Название модели (большая модель) | DeepSeek-R1-Distill-Llama-8B |
| Название модели (вставка текста) | nomic-embed |
Вот и все! Посетите репозиторий LlamaEdge и создайте своего первого ИИ-агента! Если вам это показалось интересным, пожалуйста, поставьте звезду в нашем репозитории здесь. Если у вас есть вопросы по работе с этой моделью, пожалуйста, зайдите в репозиторий, чтобы задать вопросы или заказать у нас демонстрацию, чтобы запустить свой собственный LLM на всех устройствах!
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...