LingBot-VA - 蚂蚁灵波开源的首个“自回归视频-动作世界模型”

LingBot-VA是什么
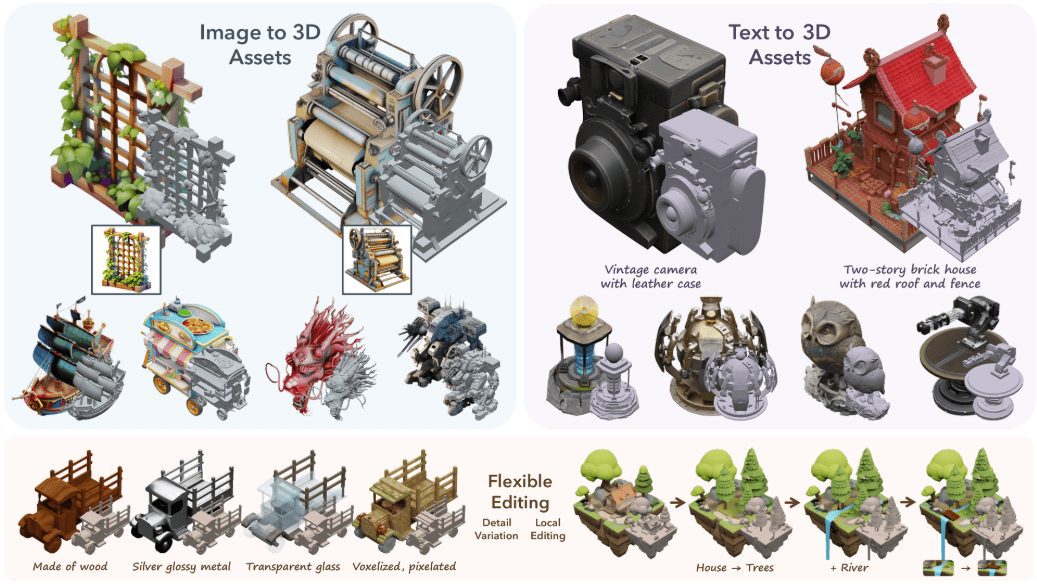
LingBot-VA 是蚂蚁灵波开源的全球首个“自回归视频-动作世界模型”,把视频生成与机器人控制塞进同一 Transformer,每一步同时输出下一帧世界画面和对应动作,实现“边想边干”。自研 MoT 架构分层处理视觉与动作流,配合因果记忆缓存,仅用 30–50 条演示就能把复杂长任务成功率提升 20%,在双臂协同基准 RoboTwin 2.0 上首破 90%,LIBERO 终身学习基准达 98.5% SOTA。模型已全栈开源,电商仓储、家庭服务机器人可零样本或少量数据快速落地。

LingBot-VA的功能特色
- 统一自回归生成:单模型同时输出“下一帧世界视频 + 机器人动作序列”,一步完成视觉推演与运动决策,闭环控制无需分阶段。
- 少样本快速适配:预训练世界模型带来强泛化,新任务只需 30–50 条真人演示即可微调上线,大幅削减数据采集成本。
- 长时序因果记忆:KV-Cache 记忆历史多步状态,自动区分相似场景,防止动作循环或误操作,支持终身持续学习。
- 毫秒级实时控制:异步推理管线把大模型容量与低延迟执行解耦,仿真-真机同步刷新,满足工业级节拍要求。
- 全栈开源工具链:提供训练代码、模型权重、评测基准及仿真接口,支持电商物流、仓储分拣、家庭服务等多场景二次开发。
LingBot-VA的核心优势
- 一体化框架:首次把大规模视频生成与机器人控制合进同一自回归网络,每步同时输出“下一帧世界状态”与对应动作序列,实现视觉推演和动作决策的闭环。
- MoT 架构:Mixture-of-Transformers 把视频流和动作流分层处理,兼顾复杂场景理解与低延迟控制,解决传统 VLA 模型“表征缠绕”问题。
- 因果记忆:利用 KV-Cache 保存长达数十步的历史信息,能在“循环状态”任务中自动区分相似场景,避免动作循环或错误。
- 少样本迁移:视频预训练带来强泛化,新任务只需几十条演示即可上线。
- 异步推理管线:动作预测与电机执行并行,兼顾大模型容量与毫秒级低延迟。
- удобство для конечного пользователя:通过记忆缓存、噪声历史增强等策略,减少生成步数,保证实时控制精度。
LingBot-VA官网是什么
- Веб-сайт проекта:https://technology.robbyant.com/lingbot-va
- Репозиторий GitHub:https://github.com/Robbyant/lingbot-va
- Библиотека моделей HuggingFace:https://huggingface.co/collections/robbyant/lingbot-va
- Технические документы:https://github.com/Robbyant/lingbot-va/blob/main/LingBot_VA_paper.pdf
LingBot-VA的适用人群
- 机器人算法团队:可直接微调 30–50 条演示,快速落地长时序、高精度任务,省去从头训练 VLA 模型的周期与算力。
- 工业自动化集成商:电商、3C、医药等仓储场景需要柔性拣选、上下料,利用开源权重+异步推理,两周内完成真机部署。
- 高校与研究机构:世界模型、具身智能方向需可复现基准,LIBERO/RoboTwin 已内置,方便发论文、打比赛。
- 中小硬件创业团队:无深度强化学习经验,也能借高泛化视频预训练,低成本让机械臂完成叠衣、冲泡等家庭服务 Demo。
- 数据标注与仿真平台:官方提供同步仿真接口和因果记忆格式,可做数据飞轮、众包演示收集,反向赋能生态。
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...